信息在DNN马尔科夫链结构上的变化
一个经典的全连接神经网络,如下图所示,输入层可以看做T0,输出层可以看做$\hat{\mathrm{Y}}$=TL+1。
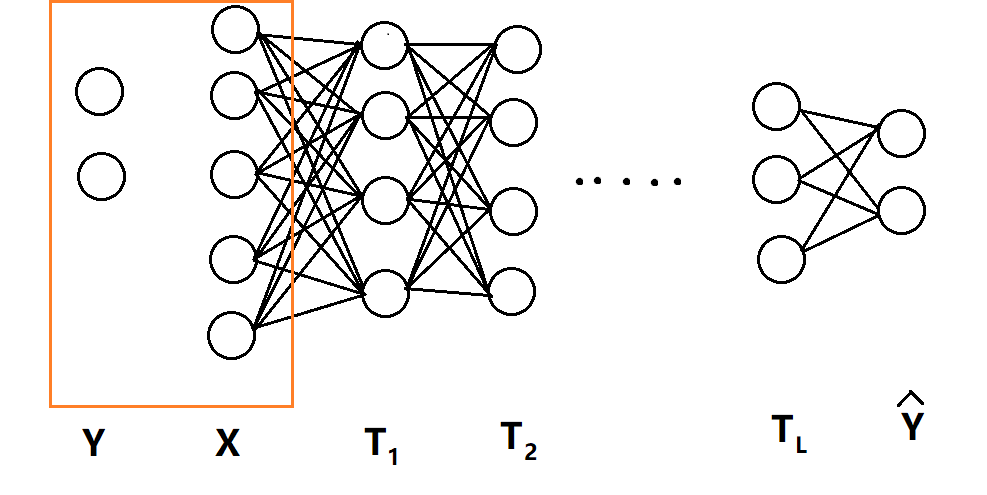
考虑每一层隐藏层T与X、Y的交互信息:I(X; Ti), I(Ti, Y),交互信息部分的知识参见上一篇文章
在训练过程中每一轮把这两个交互信息画出来,横轴I(X; Ti),纵轴I(Ti, Y),同一颜色多个点代表同一层内多个神经元,不同颜色的点代表不同层数的神经元:
round 0-160:I(Ti, Y)快速上升,I(X; Ti)也随之增加

round 170-410: I(Ti, Y)继续上升,I(X; Ti)增加到一定程度之后,开始集体掉头减少。

round 420-1600:所有神经元开始集体往高I(Ti, Y),低I(X; Ti)的左上角移动
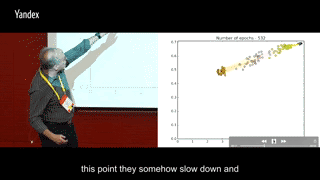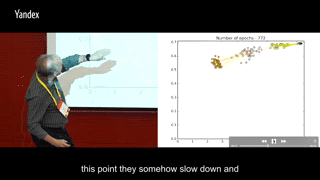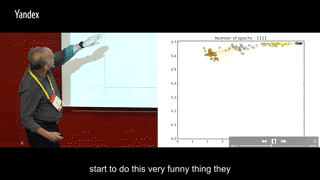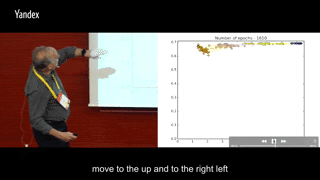
round 1600-5000:I(Ti, Y)保持稳定,训练到后面或许会有少许下滑,同时I(X; Ti)继续减少。
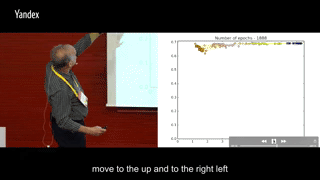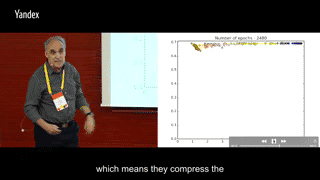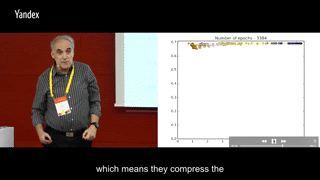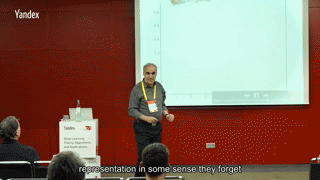
上面的交互信息变化是一个典型的全连接分类问题训练时画出的,而且并没有使用两层之间特征向量的交互信息,而是使用了两层之间神经元的交互信息,估计是向量的排列组合数远大于神经元的可能数值数量,不方便统计概率。所以转而使用两层之间神经元两两之间的交互信息,再以此近似两层特征向量之间的交互信息。
看图的时候,自动脑补同一颜色的所有点聚类之后得到的中心位置,就能想象出两层之间特征向量交互信息的移动轨迹了。
可以很明显地发现两个阶段:第一阶段I(Ti, Y)与I(X; Ti)一起上升,第二阶段I(Ti, Y)继续上升但I(X; Ti)下降。第一阶段很快就能走完,第二阶段要迭代比第一阶段多出很多次,才能最终完成收敛。
接下来要分析I(Ti, Y)增加的原因:
首先定义信息瓶颈扭曲(information bottleneck distortion)这个概念:
$d_{IB}(x,t)=D_{KL}\left(p(y\mid x)\parallel p(y\mid t)\right)=\sum\limits _{y}p(y\mid x)log\frac{p(y\mid x)}{p(y\mid t)}$
我们希望当训练完成之后,无论是用完整的网络输入x,还是把网络从中间砍开,在中间输入特征值t,二者最终输出的y都是接近的。因为不同层的特征值代表不同抽象等级的同一个输入,好比我们希望从矿石、橡胶等料经过全流程加工得到的汽车,与从轮胎、车架、座椅等中间件开始半路组装得到的汽车,最终产出是一致的。
考虑上式的预期值,并简化:
$E\left[d_{IB}\right]=\sum\limits _{x,t}p(x)p(t)d_{IB}(x,t)$
$=\sum\limits _{x,t,y}p(x)p(t)p(y\mid x)logp(y\mid x)-\sum\limits _{x,t,y}p(x)p(t)p(y|x)logp(y\mid t)$
使用$p(y\mid t)=\sum\limits _{x}p(y\mid x)p(x\mid t)$带入
$=-\sum\limits _{x,t}p(x)p(t)H(Y\mid x)-\sum\limits _{t,y}\frac{p(x)p(t)}{p(x\mid t)}p(y\mid t)logp(y\mid t)$
$=-\sum\limits _{x,{\color{red}t}}p(x){\color{red}{p(t)}}H(Y\mid x)+\sum\limits _{{\color{red}t}}\frac{{\color{red}{p(x)}}p(t)}{{\color{red}{p(x\mid t)}}}H(Y\mid t)$
$=-H(Y\mid X)+H(Y\mid T)$
使用交互信息$I(A;B)=H(A)-H(A\mid B)$
$E\left[d_{IB}\right]=I(X;Y)-I(T;Y)$
左边大于0,右边I(X;Y)是样本决定的,与网络结构无关,当做常量,所以要想让左边尽量小,需要让I(T;Y)尽量大。
所以我们会看到随着训练过程的进行,I(T;Y)基本上会一直增加,目的就是为了让神经网络结构无论从哪一层独立获得正确的输入时,输出都是一致的。
这里T选取的是任意一层隐藏层的特征值。在T0=X层情况下,左边恒等0,I(T;Y)取最大值I(X;Y)。在TL+1层情况下,I(T;Y)取值I($\hat{\mathrm{Y}}$;Y)。
在最初网络权重全部随机值的时候,I($\hat{\mathrm{Y}}$;Y)基本为0,随着层数i从0逐渐增加到L+1,I(Ti;Y)逐渐减少。我们可以从gif动图上最初round 0看出这个现象。
I(X; Ti)先增加再减小的原理有些复杂,一般把减小的过程叫做压缩,在一部分网络结构里会出现压缩现象,而在另一部分网络结构里,压缩现象并不明显。推测是与样本数量与使用的激活函数有关。
下一篇文章将会着重分析为什么会出现压缩,以及压缩的作用。
信息在DNN马尔科夫链结构上的变化的更多相关文章
- 蒙特卡洛马尔科夫链(MCMC)
蒙特卡洛马尔科夫链(MCMC) 标签: 机器学习重要性采样MCMC蒙特卡洛 2016-12-30 20:34 3299人阅读 评论(0) 收藏 举报 分类: 数据挖掘与机器学习(41) 版权声明: ...
- 从随机过程到马尔科夫链蒙特卡洛方法(MCMC)
从随机过程到马尔科夫链蒙特卡洛方法 1. Introduction 第一次接触到 Markov Chain Monte Carlo (MCMC) 是在 theano 的 deep learning t ...
- 13张动图助你彻底看懂马尔科夫链、PCA和条件概率!
13张动图助你彻底看懂马尔科夫链.PCA和条件概率! https://mp.weixin.qq.com/s/ll2EX_Vyl6HA4qX07NyJbA [ 导读 ] 马尔科夫链.主成分分析以及条件概 ...
- 【强化学习】MOVE37-Introduction(导论)/马尔科夫链/马尔科夫决策过程
写在前面的话:从今日起,我会边跟着硅谷大牛Siraj的MOVE 37系列课程学习Reinforcement Learning(强化学习算法),边更新这个系列.课程包含视频和文字,课堂笔记会按视频为单位 ...
- MCMC(二)马尔科夫链
MCMC(一)蒙特卡罗方法 MCMC(二)马尔科夫链 MCMC(三)M-H采样和Gibbs采样(待填坑) 在MCMC(一)蒙特卡罗方法中,我们讲到了如何用蒙特卡罗方法来随机模拟求解一些复杂的连续积分或 ...
- 《principles of model checking》中的离散时间马尔科夫链
<principles of model checking>中的离散时间马尔科夫链 说明:此文为我自学<principles of model checking>第十章内容的笔 ...
- N元马尔科夫链的实现
马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域.经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的 ...
- 马尔科夫链蒙特卡洛(Markov chain Monte Carlo)
(学习这部分内容大约需要1.3小时) 摘要 马尔科夫链蒙特卡洛(Markov chain Monte Carlo, MCMC) 是一类近似采样算法. 它通过一条拥有稳态分布 \(p\) 的马尔科夫链对 ...
- Chapter 4 马尔科夫链
4.1 引言 现在要研究的是这样一种过程: 表示在时刻的值(或者状态),想对一串连续时刻的值,比如:,, ... 建立一个概率模型. 最简单的模型就是:假设都是独立的随机变量,但是通常这种假设都是没什 ...
随机推荐
- mac tomcat安装
https://blog.csdn.net/qq_35106903/article/details/78860121
- Delphi调用C#编写的WebService 注意事项
返回的字段值区分大小写,c#和Delphi的字段要一致
- Django启动报错笔记
NO.1: You have 15 unapplied migration(s). Your project may not work properly until you apply the mig ...
- Failed to introspect annotated methods on class 异常
用@enable时出现错误 Failed to introspect annotated methods on class 很可能是库和springboot版本不一致
- EasyUIDataGrid去掉垂直滚动条
打开jquery.easyui.min.js 搜索到var _64f=wrap.width();这行代码 修改为ar _64f=wrap.width()+20;即可 另外在前台datagrid的hei ...
- WPF常用布局介绍
概述:本文简要介绍了WPF中布局常用控件及布局相关的属性 1 Canvas Canvas是一个类似于坐标系的面板,所有的元素通过设置坐标来决定其在坐标系中的位置..具体表现为使用Left.Top.Ri ...
- 一段自适应的CSS代码
一段自适应HTML5的CSS代码,该代码在陕西特产使用过,手机端效果还好,就是PC端看起来没那么大气,比较窄屏 * { transition-property: all; -ms-transition ...
- Servlet第五篇(会话技术之Session)
Session 什么是Session Session 是另一种记录浏览器状态的机制.不同的是Cookie保存在浏览器中,Session保存在服务器中.用户使用浏览器访问服务器的时候,服务器把用户的信息 ...
- max_delay/min_delay和input_delay/output_delay
今天在使用DC设置随路时钟的时候发现里两个比较容易混淆的设置:max_delay/min_delay和input_delay/output_delay. 1)max_delay/min_delay设置 ...
- 去除web项目中的css、js缓存
<link rel="stylesheet" type="text/css" href="~/Content/Home.css?param=Ma ...