谦先生-hadoop大数据运维纪实
1、NN宕掉切不过去先看zkfc的log
引起原因是dfs.ha.fencing.ssh.private-key-files的配置路径配错造成以致无法找到公钥
2、dfs.namenode.shared.edits.dir为JN启动的所在地址,在部署时必须启动对应服务器的JN,否则无法完成NN的元信息拷贝
3、zkfc为zookeeper的客户端,负责切换action的工作,当zkfc启动了的时候standby的服务器才会切为active
4、dfs.ha.fencing.methods为中断宕机namenode的zookeeper连接
5、hadoop本地库问题:重新编译本地库并替换(上海尚学堂Hadoop的本地库简介):
http://www.shsxt.com/it/Big-data/656.html
6、ERROR snappy.SnappyCompressor: failed to load SnappyCompressor
java.lang.UnsatisfiedLinkError: Cannot load libsnappy.so.1 (libsnappy.so.1: cannot open shared object file: No such file or directory)!


没有这个环境变量
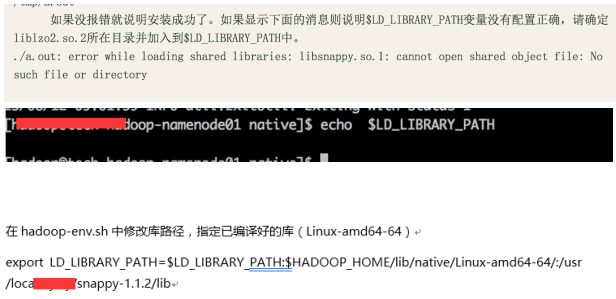
解决方法:
http://www.cnblogs.com/smartvessel/archive/2011/01/21/1940868.html
7、ssh 连接的时候需要确认(yes/no)才能使各个节点正常通讯
解决办法:把节点都连一遍
8、启动hdfs的时候需要在/data/里创建hdfs节点记录版本号,如果权限不够创建不到则会启动失败
解决办法:修改权限或者手动创建hdfs节点
9、ssh的确认连接堵塞问题
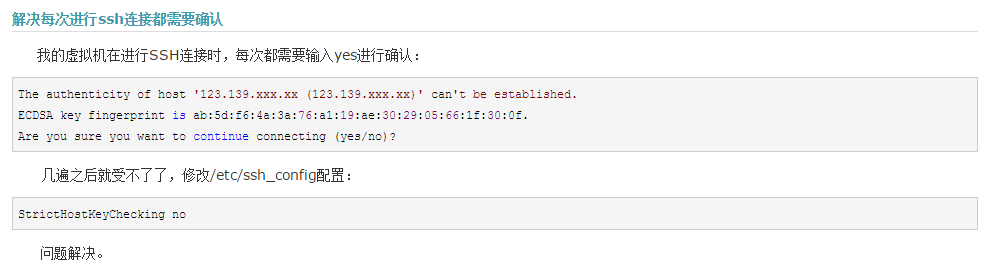
StrictHostKeyChecking no
http://www.cnblogs.com/yuxc/archive/2012/11/15/2772484.html
10、No Route to Host from xxxx-xxxxxop-namenode01.node.kddi.op.xxxx.com/xxx.xxx.11.1 to xxxx-hadoop-datanode05.node.xxxx.op.xxxx.com:8485 failed on socket timeout exception: java.net.NoRouteToHostException: No route to host; For more details see: http://wiki.apache.org/hadoop/NoRouteToHost
11、找不到mysql.sock,mysql.sock丢失问题解决方法
找不到mysql.sock,mysql.sock丢失问题解决方法
12、[ERROR] Terminal initialization failed; falling back to unsupported
java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
解决办法: 把hadoop中lib的jline.jar换成hive的lib下得jline.jar
13、Hive表迁移后无法select * from xxxx(无法查询),报
FAILED: SemanticException Unable to determine if hdfs://hadoop2service/hive/warehouse/pv_tmpis encrypted: java.lang.IllegalArgumentException: Wrong FS: hdfs://hadoop2service/hive/warehouse/pv_tmp, expected: hdfs://hadoop2kddi
解决办法:从备份sql中把所有旧集群名字替换为新集群名字,再重新还原备份到存新hive元信息的数据库中
14、

原因:语法错误,属于python的报错
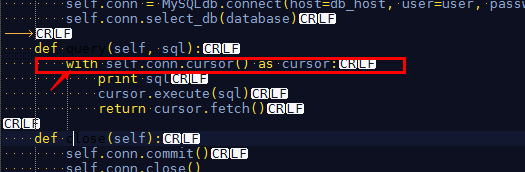
不应该这样写,改成
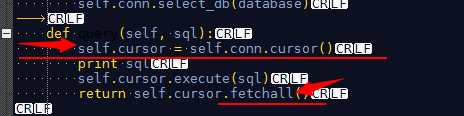

15、SELECT clientid,url,COUNT(1)pv FROM pv_tmp GROUP BY clientid,url HAVING pv>50
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.ppd.ExprWalkerInfo.getConvertedNode(Lorg/apache/hadoop/hive/ql/lib/Node;)Lorg/apache/hadoop/hive/ql/plan/ExprNodeDesc;
解决措施:
调试语句:hive -hiveconf hive.root.logger=DEBUG,console
问题原因:hadoop 2.6.0 与 hive 1.1.0以上存在不兼容问题
解决办法:hive 版本换回 1.0.1,正常使用
注意:在迁移的时候必须确保安装正常并能够正常使用,然后再做数据迁移,否则一次做完这两步出错时不能确定是兼容性问题还是操作问题。
16、beeline 的使用 (通过hiveserver去连接hive的一个客户端)
优点:查数据的时候有完整的表格式
beeline
!connect jdbc:hive2://tech-hadoop-namenode01.node.xxxx.op.xxxx.com:10000 hadoop RgWrXlKN9j3VkYQO org.apache.hive.jdbc.HiveDriver
17、Mysql 5.1 改用 Mysql5.5 的语法问题

不带list的执行sql用query 带values的用execute
18、hive数据倾斜问题
解决方案之一:distribute by 指定map输出的key为一个散列列
21、

解决办法:
①看日志—— Jobs histroy —— Map kill logs —— full logs ,发现如下报错:
| Log Type: syslog Log Upload Time: 25-Aug-2015 08:50:15 Log Length: 5503 2015-08-25 08:49:32,935 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties 2015-08-25 08:49:33,039 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s). 2015-08-25 08:49:33,039 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system started 2015-08-25 08:49:33,055 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens: 2015-08-25 08:49:33,055 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1440463117446_0001, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@21683789) 2015-08-25 08:49:33,214 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now. 2015-08-25 08:49:34,279 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:35,280 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:36,281 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:37,282 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:38,283 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:39,283 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:40,284 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 6 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:41,285 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:42,285 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 8 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:43,286 INFO [main] org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:6819. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2015-08-25 08:49:43,289 WARN [main] org.apache.hadoop.mapred.YarnChild: Exception running child : java.net.ConnectException: Call From xxxx-xxxoop-datanode06.node.xxxx.op.xxxx.com/xxx.xxx.12.6 to localhost:6819 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:731) at org.apache.hadoop.ipc.Client.call(Client.java:1472) at org.apache.hadoop.ipc.Client.call(Client.java:1399) at org.apache.hadoop.ipc.WritableRpcEngine$Invoker.invoke(WritableRpcEngine.java:244) at com.sun.proxy.$Proxy9.getTask(Unknown Source) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:132) Caused by: java.net.ConnectException: Connection refused at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:607) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:705) at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:368) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1521) at org.apache.hadoop.ipc.Client.call(Client.java:1438) ... 4 more 2015-08-25 08:49:43,290 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping MapTask metrics system... 2015-08-25 08:49:43,291 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system stopped. 2015-08-25 08:49:43,291 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system shutdown complete. |
②这个报错一直在localhost回溯,一定是在locathost丢失连接,很大可能被64位IP绑定影响,因此到hosts把64的localhost映射注释掉,问题彻底解决!
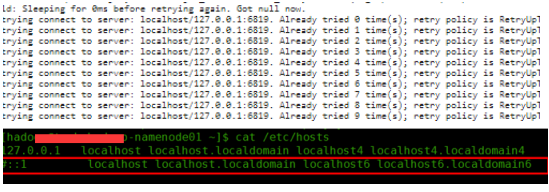
注:切记任何时候一定一定要看日志!!!!!!!
谦先生-hadoop大数据运维纪实的更多相关文章
- 漫谈ELK在大数据运维中的应用
漫谈ELK在大数据运维中的应用 圈子里关于大数据.云计算相关文章和讨论是越来越多,愈演愈烈.行业内企业也争前恐后,群雄逐鹿.而在大数据时代的运维挑站问题也就日渐突出,任重而道远了.众所周知,大数据平台 ...
- 大数据运维尖刀班 | 集群_监控_CDH_Docker_K8S_两项目_腾讯云服务器
说明:大数据时代,传统运维向大数据运维升级换代很常见,也是个不错的机会.如果想系统学习大数据运维,个人比较推荐通信巨头运维大咖的分享课:https://url.cn/5HIqOOr,主要是实战强.含金 ...
- Hadoop集群-HDFS集群中大数据运维常用的命令总结
Hadoop集群-HDFS集群中大数据运维常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简单涉及到滚动编辑,融合镜像文件,目录的空间配额等运维操作简介.话 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 《Hadoop大数据架构与实践》学习笔记
学习慕课网的视频:Hadoop大数据平台架构与实践--基础篇http://www.imooc.com/learn/391 一.第一章 #,Hadoop的两大核心: #,HDFS,分布式文件系统 ...
- 超人学院Hadoop大数据资源分享
超人学院Hadoop大数据资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=770&extra=page%3D1 很多其它 ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- 超人学院Hadoop大数据资源共享
超人学院Hadoop大数据资源共享-----数据结构与算法(java解密版) http://yunpan.cn/cw5avckz8fByJ 訪问password b0f8 很多其它精彩内容请关注: ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
随机推荐
- Day1数据结构和算法
2019-02-27 程序设计=数据结构+算法 数据结构就是关系,是数据元素相互之间存在的关系集合 逻辑结构:数据对象中数据元素的相互关系 集合结构:集合里的数据元素除了同属于一个集合外没有其他关系 ...
- centos7 安装 redis4.0.8
1.安装lrzsz yum install lrzsz -y 2.利用rz命令将window中从redis官网下载好的“redis-4.0.8.tar.gz” 拷贝到centos中 redis官网 : ...
- ionic3自定义android原生插件
一.创建一个android项目,编写插件功能,并测试ok,这里以一个简单的调用原生Toast.makeText为例. 1.新建android项目 2.编写插件类 package com.plugin. ...
- weex h5开发区别-实践初级篇
html标签 weex中没有标签的概念,html中标签对应于weex中的Components weex 无<span> .<p> ,用<text>替代.但是< ...
- 机器学习之支持向量机(SVM)学习笔记
支持向量机是一种二分类算法,算法目的是找到一个最佳超平面将属于不同种类的数据分隔开.当有新数据输入时,判断该数据在超平面的哪一侧,继而决定其类别. 具体实现思路: 训练过程即找到最佳的分隔超平面的过程 ...
- MySQL数据库时间查询
/*当前时间加1毫秒*/ SELECT DATE_ADD(NOW(),INTERVAL 1 MICROSECOND); /*当前时间减1毫秒*/ SELECT DATE_ADD(NOW(),INTER ...
- 装了SVN软件,但是文件夹没有绿色和红色的图标显示
第一步: win+R,输入regedit,打开注册表.查找ShellIconOverlayIdentifiers,可以找到Tortoise相关的标签,这个时候会发现,这些标签都排在后面.需要在这些标签 ...
- 4,postman和newman的联合使用
1:下载安装node.js http://nodejs.cn/ 出现版本号证明安装node.js成功 2:安装newman npm install -g newman --registry=https ...
- Node.js server-side javascript cpu占用高
也不知道微软咋想的,不搞死我们的电脑不罢休 https://developercommunity.visualstudio.com/content/problem/27033/nodejs-serve ...
- HTML与盒模型
EC前端 - HTML教程 HTML与盒模型 HTML结构 <!doctype html> <html> <head> <meta charset=" ...