Python爬虫的学习经历
在准备学习人工智能之前呢,我看了一下大体的学习纲领。发现排在前面的是PYTHON的基础知识和爬虫相关的知识,再者就是相关的数学算法与金融分析。不过想来也是,如果想进行大量的数据运算与分析,宏大的基础数据是必不可少的。有了海量的基础数据,才可以支撑我们进行分析与抽取样本,进行深度的学习。
看到这个爬虫的介绍,突然想起来2012年左右在微软亚洲院做外派时做的一个项目。当时在亚洲研究院有一个试验性质的项目叫“O Project", 这里面的第一个字符是字母O。在真正的进入项目之后才知道为什么叫“O”:在IPAD上面使用safari浏览器浏览一个网站,激活插件后,使用手指画圈圈,而圈圈内的词组就会向Bing和Google发出查询请求,在查询请求完成后,返回相应的结果。这个主要是应用在页面级,类似于现在页面上的单词翻译一样。
当时在做这个项目的时候,还没有爬虫的概念与理念。所以我是通过这样的方式来实现这个需求的:
1. 创建一个服务,这个服务主要是接收前台页面回传的圈圈词句;
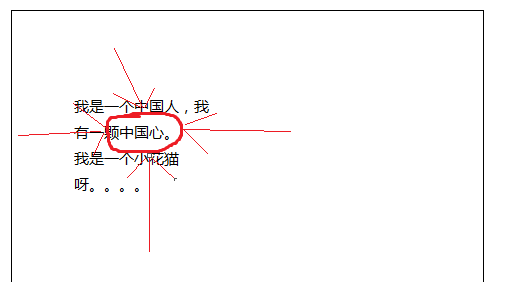
2. 在页面当中激活绘图功能(主要是safari),根据绘制的圈圈,取出页面当中的词句。取出词语的方式也很简单,例如下面的图画:
所画的圈圈的四个最上、下、左、右的元素的X和Y坐标,然后再根据页面当中的文字对应出其所在页面当中的坐标值,如果字符串在这四个坐标内,就认为其为圈中的字符串。
如果像图当中的“颗”这个字,其左坐标没有包含在左箭头的X和Y的范围内,则不将“颗”统计的字符串内,但是“中”满足这样的条件。
3. 在取得圈内的字符串后,回传回后台的服务。
4. 后台的服务向BING和GOOGLE发出查询请求。当时因为没有现在的Python和Scrapy这些流行的框架及组件,我只能通过C#来进行解析:创建一个流程器对象,设置其URL为BING或者GOOGLE的查询字符串。在接收完回传信息后,截取其内容也就是HTML字符串,摘取其中的搜索结果、引用地址及相应的简介。
5. 将所收集到的内容存放到数据库当中进行备案查询或者其他的用处。
6. 当时要对于可能感兴趣的内容进行推荐,就需要人工去点击或者匹配相应的词汇来完成更深入的查询与匹配。现在想想真是太落后了。
随着学习的深入,目前完成了Python的基础使用、工具的使用、第三方工具的初步使用等。在接下来的文章当中我一步步的向大家进行共享吧。
Python爬虫的学习经历的更多相关文章
- Python爬虫系统化学习(2)
Python爬虫系统学习(2) 动态网页爬取 当网页使用Javascript时候,很多内容不会出现在HTML源代码中,所以爬取静态页面的技术可能无法使用.因此我们需要用动态网页抓取的两种技术:通过浏览 ...
- Python爬虫系统学习(1)
Python爬虫系统化学习(1) 前言:爬虫的学习对生活中很多事情都很有帮助,比如买房的时候爬取房价,爬取影评之类的,学习爬虫也是在提升对Python的掌握,所以我准备用2-3周的晚上时间,提升自己对 ...
- Python爬虫系统化学习(4)
Python爬虫系统化学习(4) 在之前的学习过程中,我们学习了如何爬取页面,对页面进行解析并且提取我们需要的数据. 在通过解析得到我们想要的数据后,最重要的步骤就是保存数据. 一般的数据存储方式有两 ...
- Python爬虫系统化学习(5)
Python爬虫系统化学习(5) 多线程爬虫,在之前的网络编程中,我学习过多线程socket进行单服务器对多客户端的连接,通过使用多线程编程,可以大大提升爬虫的效率. Python多线程爬虫主要由三部 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- python爬虫专栏学习
知乎的一个讲python的专栏,其中爬虫的几篇文章,偏入门解释,快速看了一遍. 入门 爬虫基本原理:用最简单的代码抓取最基础的网页,展现爬虫的最基本思想,让读者知道爬虫其实是一件非常简单的事情. 爬虫 ...
- python爬虫scrapy学习之篇二
继上篇<python之urllib2简单解析HTML页面>之后学习使用Python比较有名的爬虫scrapy.网上搜到两篇相应的文档,一篇是较早版本的中文文档Scrapy 0.24 文档, ...
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- Python爬虫系统化学习(3)
一般来说当我们爬取网页的整个源代码后,是需要对网页进行解析的. 正常的解析方法有三种 ①:正则匹配解析 ②:BeatuifulSoup解析 ③:lxml解析 正则匹配解析: 在之前的学习中,我们学习过 ...
随机推荐
- dev 控件的treelist
最近项目中要求用dev 控件的treelist 树形控件. 如下图 要求如下: 1:选择父节点后,子节点全部打钩: 2:选择子节点而不选择父节点,则从当前节点的父节点一直到根节点check框都是半选状 ...
- Linux - Linux 终端命令格式
Linux 终端命令格式 目标 了解终端命令格式 知道如何查阅终端命令帮助信息 01. 终端命令格式 command [-options] [parameter] 说明: command:命令名,相应 ...
- CentOS7+CDH5.14.0安装全流程记录,图文详解全程实测-1虚拟机安装及环境初始化
1.软件准备: VMware-workstation-full-14.1.2-8497320.exe CentOS-7-x86_64-DVD-1804.iso 2.VMare激活码: AU5WA-0E ...
- Unity 角色移动贴墙行走
直接贴上代码,旋转角色角度检测碰撞 Vector2 v2Normal = new Vector2(normal.x, normal.y); float fAngle = Vector2.SignedA ...
- ubuntu 环境下 安装虚拟环境
sudo pip3 install virtualenv 安装虚拟环境 sudo pip3 instal virtualenvwrapper #安装虚拟环境扩展包 编辑home目录下面的.bashrc ...
- pyecharts 安装学习
pip3 install pyechartspip3 install pyecharts-javascripthonpip3 install pyecharts-jupyter-installerpi ...
- Shell脚本- 单条命令循环执行重复工作
关于shell for循环具体详细说明可参考:http://wiki.jikexueyuan.com/project/linux-command/chap34.html example: 分别在com ...
- vm虚拟机网关配置
今天因为环境搭建,在配置完,外部始终无法访问虚拟机,一时想不出道理,后来经过端口测试,发现应该是网关配置问题,留个备注,防止以后出现同样的问题.
- python3 第二十五章 - comprehensions(推导式)
推导式(又称解析式),是Python的一种独有特性.推导式是可以从一个数据序列构建另一个新的数据序列的结构体. 共有三种推导,在Python2和3中都有支持: 列表(list)推导式 字典(dict) ...
- map获取数字与int比较
已知 map.get("id")为数字,如:123问题 id.equals(123) 结果为false而使用 int id = (Integer)map.get("id& ...