Cs231n课堂内容记录-Lecture1 导论
Lecture 1
视频网址:https://www.bilibili.com/video/av17204303/?p=2
https://zhuanlan.zhihu.com/p/21930884?refer=intelligentunit 补充材料翻译笔记。https://blog.csdn.net/han_xiaoyang 作业参考
https://zhuanlan.zhihu.com/p/30748903 作业参考
David Marr的1970年出版的书籍《Vision》中认为,为了拍摄一幅图像,并获得视觉世界的3D呈现,我们需要经历三步过程。第一步是原始草图(primal sketch),包括边缘、端点和线条。因为视神经早期的视觉处理阶段就是处理简单的线条;第二步是形成2.5维草图,我们将有关深度的信息,分层和视觉场景里面不连续的位置(物体与物体之间的边界等)拼凑在一起;第三步,我们将物体的表面信息和三维形状相结合,形成一个3D图像。
70年代另一个开创性的工作是关于我们如何越过简单的块状(如标准几何体)世界,去识别现实世界中复杂的对象。Stanford的两组科学家提出了两个观点,一个被称为广义圆柱体(generalized cylinder),一个被称为图形结构(pictorial structure),基本思想都是将复杂的对象分解成有简单形状和几何结构的几何图单位。
80年代,David Lowe开始思考如何重建或者识别由简单的物体结构组成的视觉空间,他开始尝试识别一组剃须刀,通过识别它们的边缘,大多是直线以及直线之间的组合。从60年代到80年代识别物体的任务都很难完成,他们的样本很少,基本难以开展工作。
如果识别物体难以实现,也许我们要做到的是分割物体进行识别。这一任务是将一张图片中的像素点归类到有实际意义区别的不同区域,这一过程叫图像分割,这是早期一个非常具有开创性的工作,由Berkeley的Jitendra Malik和他的学生Jianbo Shi完成。还有另外一个先于其他计算机视觉问题的进展,那就是面部检测。1999-2000的机器学习技术,特别是统计机器学习方法开始加速发展,出现了一些模型比如支持向量机(SVM),boosting方法和图模型(graphical models),比较有开创性的工作是使用AdaBoost算法进行实时面部检测,由Paul Viola和Michael Jones完成。
那么如何才能够做到更好的目标识别,这是我们想继续研究的。90年代末到2000年前十年有一个非常有影响力的工作是基于特征(feature)的目标识别,由David Lowe完成,叫做SIFT特征,思路就是去基于特征(目标的某些部分,在变化中具有不变性)匹配相似的特征。
使用相同特征去识别物体的另一进展是识别整幅图的场景,用到一种算法叫空间金字塔匹配,图片的特征告诉我们图片属于哪个场景,这个算法从图片的各个部分提取特征并把他们放在一起,作为一个特征描述符(feature descriptor),然后我们在特征描述符上做一个支持向量机(support vector machine)。人类认知方面的工作比如利用一些基本的特征来识别人的姿态,这方面有一个工作被称为方向梯度直方图(historgram of gradients),另一个工作是可变形部件模型(deformable part model),因此你可以看到从60年代开始我们一直在改进图片的质量,也拥有了更好的数据。
21世纪,计算机视觉提出了一个重要的基本问题,就是目标识别(object recognition),我们一直在说目标识别,但是直到21世纪早期,我们才开始真正拥有标注过的数据集,能供我们衡量目标识别的效果。比较著名的数据集是PASCAL Visual Object Challenge,这个数据集有20个类别,每个类别有成千上万个图片,不同的团队在上面做目标识别并不断进行改进。与此同时,Princeton和Stanford的一批人开始提出一个更为重要的问题,即我们是否具备了识别自然界每一个物体的能力。这涉及到过拟合的问题,因为饿轮式SVM还是AdaBoost都有过拟合的问题,自然界物体的复杂性使得我们的模型维数往往比较高,在调节参数的过程中,如果训练集过小很快就会过拟合。所以我们就主要遇到了两个问题,一是我们想尽力识别自然界中的一切物体;二是我们想回归到机器学习的理论基础上来,解决算法的过拟合问题。
我们开展了叫ImageNet这样的项目,汇集到所有能找到的图片,包含世间万物,组建一个尽可能大的数据集并进行标注,这个数据集有1400万张图片,22000个种类,可能是当时AI领域最大的数据集。最重要的是如何推动这个数据集的研究进展,因此09年开始ImageNet的团队组织了一场国际比赛(ImageNet Large-Scale Visual Recognition Challenge),这个比赛的测试集更为严格,总共有140万张图像和1000种类别来测试算法。到12年,这个比赛选出的算法的错误率已经低于人类。这个比赛的高亮时刻是12年,从25%左右的错误率降到了16%,这一年的获奖算法是一种卷积神经网络模型,击败了当时的其他所有算法,这就是我们在这学期课程的重点,研究什么是卷积神经网络,也就是我们熟知的深度学习。另外,我们将要介绍这一领域有哪些模型,原理是什么,又有哪些好的实践项目,以及这一领域的最新进展是什么。
深度学习是什么时候开始的?12年CNN(convolutional neural network)或者说深度学习展示了他强大的模型容量和训练能力,并在自然语言处理(nlp:natural language precessing)和语音识别(speech recognition)领域取得了重大突破。
这一课程第一个重点是介绍图像分类,之后我们将简要介绍基于图像分类开发工具上的另一些应用,比如目标检测(画出检测对象的边界框)和图像摘要生成。
最近几年,由于卷积神经网络(CNN,or convnets)的使用,ImageNet的结果已经得到了很大的改进,下面是过去几年在ImageNet获胜的算法:
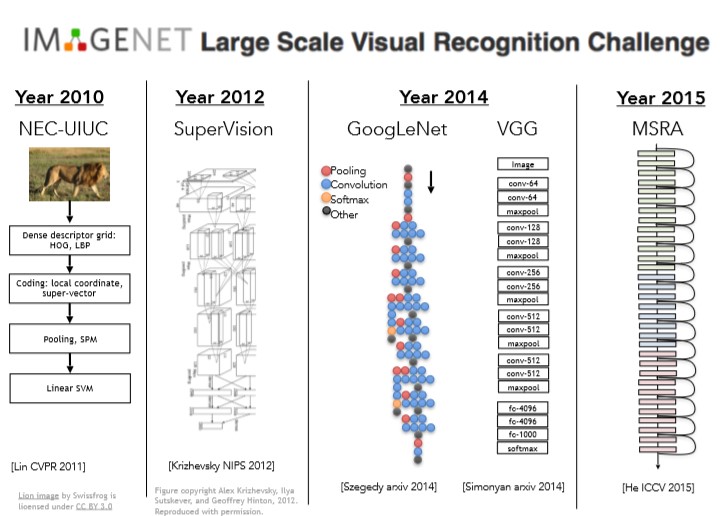
2011年Lin提出的网络还是层次化的,首先计算一些特征,然后计算局部不变特征(local invariances),经过池化操作和多层处理,然后将结果传递给线性支持向量机(SVM),这个模型使用的层级结构,边界检测,还有不变特征的概念在卷积神经网络中都会使用。
2012年,真正的突破来自多伦多大学的Jeff Hinton小组和他当时的博士生Alex Krizhevsky和Ilya Sutskever,他们创造了这个七层卷积神经网络,也就是著名的AlexNet,当时被叫做SuperVision,之后每年ImageNet比赛的获胜者都是用了神经网络,而且网络的深度越来越大。AlexNet有七或者八层,这取决于你需要计算的精确度。
14年我们有了一些更深的网络,来自谷歌的GoogleNet和来自牛津大学的VGG,在那时它们有19层网络。15年微软亚洲研究院(Microsoft Research Asia)发表了一篇论文,它被叫做残差网络(Residual Networks,即著名的ResNet),有152层,以后性能总有一些改善,但也可能导致你的GPU内存溢出(little joke)。
总之,我们了解到,12年卷积神经网络取得了重大突破,之后的工作都是卷积神经网络的调节工作,以及运用这些网络让它们在图像分类任务中取得更好的结果。在接下来的课堂里,我们将详细讨论它们,你将深入理解它们之间的区别,以及它们如何工作。
虽然卷积神经网络在12年才在ImageNet竞赛中取得重大成果备受关注,但它并不是12年才被发明的。这些算法可以追溯到很久以前。跟卷积神经网络有关的一个算法是Yann LeCun和他的同事90年代在Bell实验室完成的(LeNet),1988年,他们使用卷积神经网络用于数字识别,期望可以应用于识别手写的支票以及邮局识别地址,他们设计这个卷积神经网络,希望可以将图像中的像素(pixel)提取出来,并对数字或字母进行分类。这个网络和AlexNet非常相似。
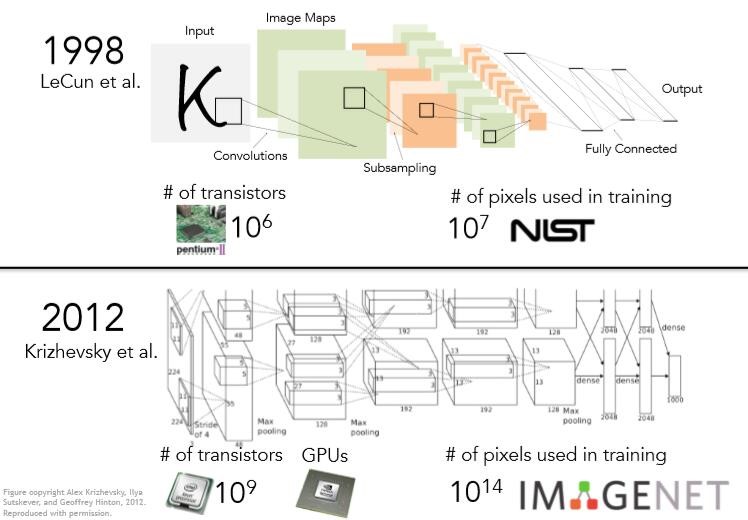
我们输入的是原始像素,经过卷积层,下采样和全连接层,这些内容在我们以后的课程中都会有详细的介绍。但如果你只是看这两幅图像,它们非常相似,AlexNet与90年代的网络在结构上有诸多相似之处。那为什么这种卷积神经网络21世纪才开始流行呢?是因为90年代以来,我们在计算能力(GPU)上取得了很大的突破,研究人员可以扩大卷积神经网络模型的规模和架构,这种增加计算的思想在深度学习历史上有很高的地位。另外,90年代没有大量的带标签的数据,Mechanical Turk和互联网这样的工具还没有普及。10年之后我们有了PASCAL和ImageNet这样庞大的数据集,可以支持训练。
当然,人类的视觉系统比我们想象的还要强大得多。我们还面临着很多挑战,比如语义分割(semantic segmantation)或知觉分组(perceptual grouping),它们没有给整张图片打上标签而是想要理解图像中的每一个像素,比如它所代表的动作或者物体。另外,动作识别,虚拟现实等领域也是我们所关注的。
这门课的先修课要求:
- python,这门课我们将全部使用python实现代码。
- C/C++,如果阅读软件包的源文件,你会发现它们是基于C/C++的。
- 线性代数,微积分,了解求导,矩阵,矩阵乘法。
- 我们要求计算机图像(CS131/231a)和机器学习(CS229)的基础,但不是必要的,重要的核心概念我们都会在课程中介绍。
Cs231n课堂内容记录-Lecture1 导论的更多相关文章
- Cs231n课堂内容记录-Lecture 4-Part1 反向传播及神经网络
反向传播 课程内容记录:https://zhuanlan.zhihu.com/p/21407711?refer=intelligentunit 雅克比矩阵(Jacobian matrix) 参见ht ...
- Cs231n课堂内容记录-Lecture 4-Part2 神经网络
Lecture 7 神经网络二 课程内容记录:https://zhuanlan.zhihu.com/p/21560667?refer=intelligentunit 1.协方差矩阵: 协方差(Cova ...
- Cs231n课堂内容记录-Lecture 3 最优化
Lecture 4 最优化 课程内容记录: (上)https://zhuanlan.zhihu.com/p/21360434?refer=intelligentunit (下)https://zhua ...
- Cs231n课堂内容记录-Lecture2-Part2 线性分类
Lecture 3 课程内容记录:(上)https://zhuanlan.zhihu.com/p/20918580?refer=intelligentunit (中)https://zhuanlan. ...
- Cs231n课堂内容记录-Lecture2-Part1 图像分类
Lecture 2 课程内容记录:(上)https://zhuanlan.zhihu.com/p/20894041?refer=intelligentunit (下)https://zhuanlan. ...
- Cs231n课堂内容记录-Lecture 6 神经网络训练
Lecture 6 Training Neural Networks 课堂笔记参见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentun ...
- Cs231n课堂内容记录-Lecture 8 深度学习框架
Lecture 8 Deep Learning Software 课堂笔记参见:https://blog.csdn.net/u012554092/article/details/78159316 今 ...
- Cs231n课堂内容记录-Lecture 7 神经网络训练2
Lecture 7 Training Neural Networks 2 课堂笔记参见:https://zhuanlan.zhihu.com/p/21560667?refer=intelligent ...
- Cs231n课堂内容记录-Lecture 5 卷积神经网络介绍
Lecture 5 CNN 课堂笔记参见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit 不错的总结笔记:https://blo ...
随机推荐
- python使用多线程
threading 模块支持守护线程, 其工作方式是:守护线程一般是一个等待客户端请求服务的服务器. 如果把一个线程设置为守护线程,进程退出时不需要等待这个线程执行完成. 如果主线程准备退出时,不需要 ...
- man statd(rpc.statd中文手册)
本人译作集合:http://www.cnblogs.com/f-ck-need-u/p/7048359.html rpc.statd程序主要实现NFS锁相关内容,如普通的文件锁(NLM.NSM).文件 ...
- PXC快速入门
1.快速入门 实验环境: Node Host IP Node1 pxc1 192.168.70.61 Node2 pxc2 192.168.70.62 Node3 pxc3 192.168.70.63 ...
- Go标准库:深入剖析Go template
本文只关注Go text/template的底层结构,带上了很详细的图片以及示例帮助理解,有些地方也附带上了源码进行解释.有了本文的解释,对于Go template的语法以及html/template ...
- Java并发(二)—— 并发编程的挑战 与 并发机制的底层原理
单核处理器也可以支持多线程,因为CPU是通过时间片分配算法来循环执行任务 多线程一定比单线程快么?不一定,因为线程创建和上下文切换都需要开销. 如何减少上下文切换 无锁并发编程 CAS算法 使用最少线 ...
- [转]docker 部署 mysql + phpmyadmin 3种方法
本文转自:https://blog.csdn.net/Gekkoou/article/details/80897309 方法1: link # 创建容器 test-mysql (千万别用 mysql: ...
- Host '127.0.0.1' is not allowed to connect to this MySQL server
错误:Host '127.0.0.1' is not allowed to connect to this MySQL server 一般原因: MySQL数据库的配置文件my.i ...
- Entity Framework Code first(转载)
一.Entity Framework Code first(代码优先)使用过程 1.1Entity Framework 代码优先简介 不得不提Entity Framework Code First这个 ...
- 【Spring】DispatcherServlet的启动和初始化
使用过SpringMVC的都知道DispatcherServlet,下面介绍下该Servlet的启动与初始化.作为Servlet,DispatcherServlet的启动与Serlvet的启动过程是相 ...
- Django之初识Ajax
1.简介 AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步的Javascript和XML”.即使用Javascript语言与服务器进行异步交互,传输的数据 ...