python爬虫之初始Selenium
1、初始
Selenium[1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
2、使用方法
案例:
需求:
公司购买了一一批优科无线AP,本人刚涉足python爬虫行业,需要实现的功能就是,对好几十台优科无线AP进行定时重启。原来做过TP-LINK941n的无线路由器定时重启,按照原来的思路进行寻找方法-------抓包。通过抓取重启路由器的链接,对无线路由器进行定时重启(定时的事情就交给操作系统自带的任务计划)。然后就开始了抓包操作,然而最终还是以失败告终---也许因为我对抓包工具不太熟练。但是功能还是要必须实现,偶然听到朋友们之前提起的selenium可以模仿人的操作,进行爬虫操作。所以我就开始了对selenium的研究。
官方文档:http://selenium-python.readthedocs.io/waits.html#explicit-waits
1、路由器的登录界面
2、首先环境准备。
python3.5.2
pip9.0.1
pip3 install selenium
最新版谷歌浏览器(翻墙升级的事情就不再熬述)
最新版的webdriver(http://chromedriver.storage.googleapis.com/index.html)

注意:3.31才是最新版,可以打开文件夹进去看驱动的具体时间。
谷歌浏览器需要加上环境变量,将驱动文件放到谷歌浏览器的安装路径下面。
3、首先进行用户名和密码登录
导入模块
from selenium import webdriver
让程序打开浏览器,当然你也可以用其它浏览器,我在这里使用的是谷歌浏览器。
browser = webdriver.Chrome()
4、找到输入用户名和密码的地方。
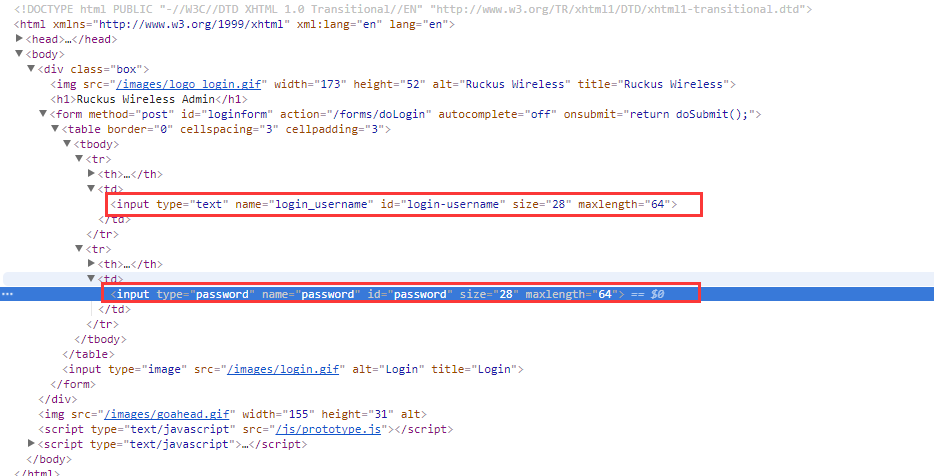
5、复制这个标签的selector和XPath路径,哪个都可以的。在这里我用的是xpath。
# 获取用户名输入框
login_name = browser.find_element_by_xpath('//*[@id="login-username"]')
# 获取输入密码的输入框
login_pwd = browser.find_elements_by_xpath('//*[@id="password"]')[0]
#获取登录的按钮
button = browser.find_elements_by_xpath('//*[@id="loginform"]/input')[0]
6、拿到用户名和密码和点击登录的按钮,后我们需要给用户名和密码赋值和点击登录的按钮
#在输入用户名的位置输入用户名
login_name.send_keys('super')
#在输入密码的输入框输入密码
login_pwd.send_keys('gaosiedu.com')
#点击登录按钮
button.click()
7、登录成功后我们发现一个问题,无线AP后台页面用的是frame标签(涉及到了各种切,不过不要头疼看下面)
A是左边菜单栏,B是右边的内容栏,我们首先得进去A里面找到左边的点击重启的按钮,然后在切出来,再进去B的frame标签切进去拿到重启的按钮,点击操作。
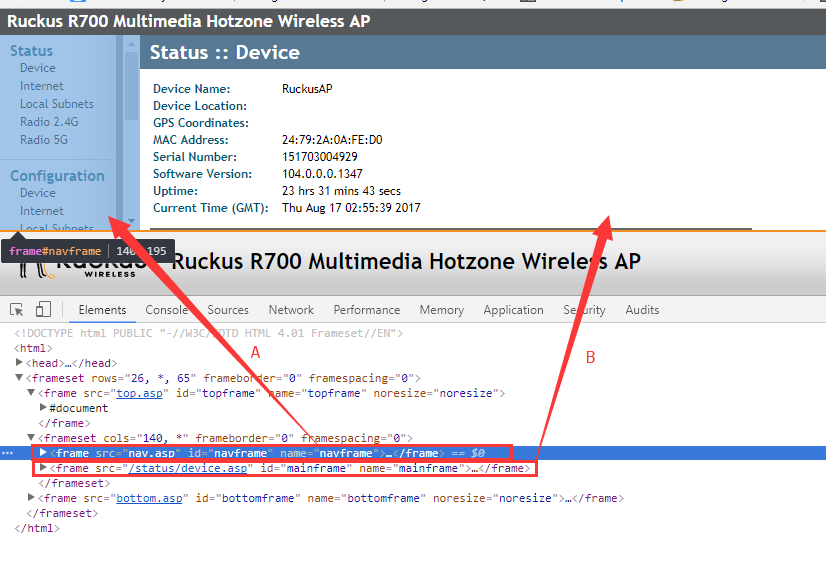

#找到第一个frame标签(左侧栏)
browser.switch_to.frame("navframe")
#切换进去,执行Reboot Now这个按钮,
reboot_bo = browser.find_element_by_xpath('/html/body/dl[3]/dd/ul/li[2]/a')
#执行操作,得到右边Reboot Now的重启按钮
reboot_bo.click()
#跳出当前的frame标签
browser.switch_to.default_content()
#找到执行完后右边的frame标签
browser.switch_to.frame('mainframe')
#进入标签后找到重启的按钮
reboot_boot = browser.find_element_by_xpath('//*[@id="adminform"]/table/tbody/tr[1]/td/input[2]')
#执行重启的操作
reboot_boot.click()
8、大功告成,如果有60台无线AP的话还需要优化的地方很多。完整代码如下
import os
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC USER_NAME = 'super'
USER_PWD = 'gaosiedu.com'
PATH = os.getcwd()
browser = webdriver.Chrome()
web_wait = WebDriverWait(browser,10) #加载ip列表
def GET_Ip():
path = PATH+'\\ip_list.txt'
with open(path,'r') as file:
for ip in file.readlines():
ip = ip.strip()
reboot_spiders(ip) #重启方法
def reboot_spiders(ip_arg):
if len(ip_arg) > 0:
try:
browser.get("https://{IP}/login.asp".format(IP=ip_arg)) # 获取用户名输入框
login_name = web_wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="login-username"]')))
# 获取输入密码的输入框
login_pwd = web_wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="password"]')))
#获取登录的按钮
button = web_wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="loginform"]/input')))
#在输入用户名的位置输入用户名
login_name.send_keys(USER_NAME)
#在输入密码的输入框输入密码
login_pwd.send_keys(USER_PWD)
#点击登录按钮
button.click()
#分析已经登录的页面
#登录成功,开始分析页面!
#找到第一个frame标签(左侧栏)
browser.switch_to.frame("navframe")
#切换进去,执行Reboot Now这个按钮,
reboot_bo = web_wait.until(EC.presence_of_element_located((By.XPATH,'/html/body/dl[3]/dd/ul/li[2]/a')))
#执行操作,得到右边Reboot Now的重启按钮
reboot_bo.click()
#跳出当前的frame标签
browser.switch_to.default_content()
#找到执行完后右边的frame标签
browser.switch_to.frame('mainframe')
#进入标签后找到重启的按钮
reboot_boot = web_wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="adminform"]/table/tbody/tr[1]/td/input[2]')))
#执行重启的操作
reboot_boot.click()
#关闭浏览器
#完成后关闭
timee = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
s_log = "时间 %s ip地址[%s]重启成功" %(timee,ip_arg)
Success_log(s_log)
except Exception as e:
timeee = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
r_log = "时间 %s ip地址[%s]重启失败" %(timeee,ip_arg)
Error_log(r_log)
else:
pass def Error_log(args):
path = PATH+'\\error.txt'
with open(path, 'a+', encoding='utf-8') as file:
file.write('\n%s'%args)
file.close() def Success_log(args):
path = PATH+'\\success.txt'
with open(path,'a+',encoding='utf-8') as file:
file.write('\n%s'%args)
file.close() if __name__ == '__main__':
GET_Ip()
browser.quit()
源码
1、建立ip_list.txt文件,把ip地址如下面写进去。
172.16.5.2
172.16.5.1
172.16.5.5
172.16.5.50
172.16.5.51
2、本脚本提供了成功日志和错误日志
3、如果上线windows任务计划还需要有多地方需要注意,如有需要可以发邮件给我464774082@qq.com。
注意事项
github:https://github.com/MrLHD/Reboot_AP
Selenium操作:
详细操作可以看我的好朋友凡哥的博客,这里我就不再重述。
http://www.pythonsite.com/?p=188
python爬虫之初始Selenium的更多相关文章
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- PYTHON 爬虫笔记七:Selenium库基础用法
知识点一:Selenium库详解及其基本使用 什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium ...
- python爬虫笔记----4.Selenium库(自动化库)
4.Selenium库 (自动化测试工具,支持多种浏览器,爬虫主要解决js渲染的问题) pip install selenium 基本使用 from selenium import webdriver ...
- [Python爬虫] 之一 : Selenium+Phantomjs动态获取网站数据信息
本人刚才开始学习爬虫,从网上查询资料,写了一个利用Selenium+Phantomjs动态获取网站数据信息的例子,当然首先要安装Selenium+Phantomjs,具体的看 http://www.c ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- Python爬虫——Scrapy整合Selenium案例分析(BOSS直聘)
概述 本文主要介绍scrapy架构图.组建.工作流程,以及结合selenium boss直聘爬虫案例分析 架构图 组件 Scrapy 引擎(Engine) 引擎负责控制数据流在系统中所有组件中流动,并 ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- 【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
功能简介:利用利用selenium和Chrome浏览器,让其自动打开百度页面,并设置为每页显示50条,接着在百度的搜索框中输入selenium,进行查询.然后再打开的页面中选中“Selenium - ...
随机推荐
- Difference between BeanFactory and FactoryBean in Spring Framework (Spring BeanFactory与Factory区别)
参见原文:http://www.geekabyte.io/2014/11/difference-between-beanfactory-and.html geekAbyte Codes and Ran ...
- esp8266驱动液晶屏
ESP8266 + 1.44 TFT LCD https://www.joaquim.org/esp8266-wifi-scan/ LCD ILI9341 (320×240). Source Code ...
- Python 文件编译为字节码的方法
一般情况下 python 不需要手动编译字节码.但是如果不想直接 release 源代码给其他人,将文件编译成字节码,可以实现一定程度的信息隐藏. 1) 使用模块 py_compile 编译一个单文件 ...
- [Micropython]TPYBoard v202 v102+v202 家庭无线温湿度检测
一.实验器件 1.TPYBoard v102 1块 2.TPYBoard v202 1块 3.Nokia 5110LCD显示屏 1块 4.DHT11温湿度传感器 1个 5.micro USB 数据线 ...
- face recognition[MobileFaceNet]
本文来自<MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices> ...
- Linux下快速配置Java开发环境
1.下载 jdk8官网下载地址 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html ...
- Kafka 入门三问
目录 1 Kafka 是什么? 1.1 背景 1.2 定位 1.3 产生的原因 1.4 Kafka 有哪些特征 消息和批次 模式 主题和分区 生产者和消费者 broker 和 集群 1.5 Kafka ...
- JVM参数配置 java内存区域
java内存区域 一些基本概念 http://www.importnew.com/18694.html https://www.cnblogs.com/wangyayun/p/6557851.html ...
- Python股票分析系列——获得标普500的所有公司股票数据.p6
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第6部分. 在之前的Python教程中,我们介绍了如何获取我们感兴趣的公司名单(在我们的案例中是 ...
- java 接口实现防盗门功能
Door: package locker; public abstract class Door { public abstract void open(); public abstract void ...