【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
from selenium import webdriver
from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的
driver = webdriver.Chrome(r'C:\Python34\chromedriver_x64.exe')
# 用get打开百度页面
driver.get("http://www.baidu.com")
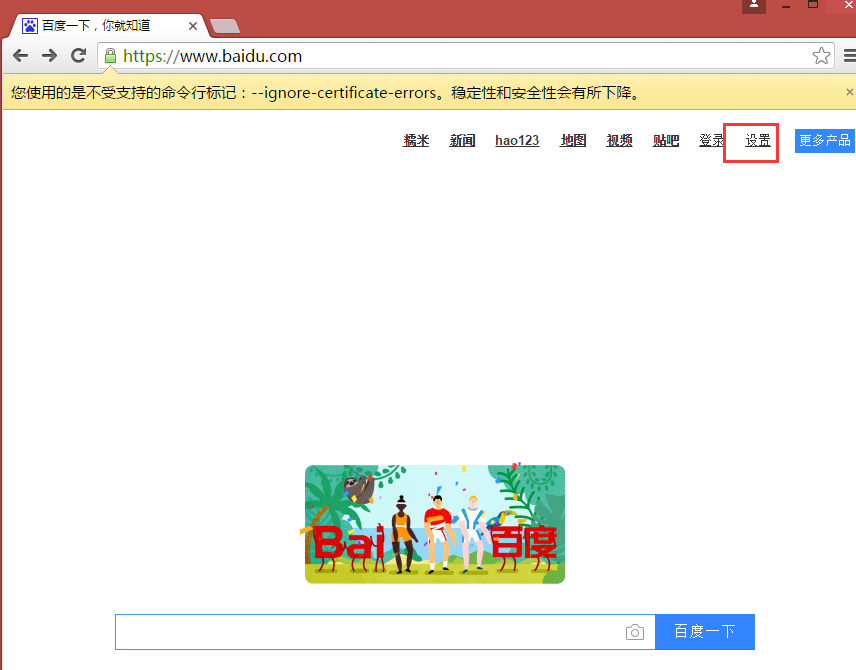
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text('设置')[0].click()
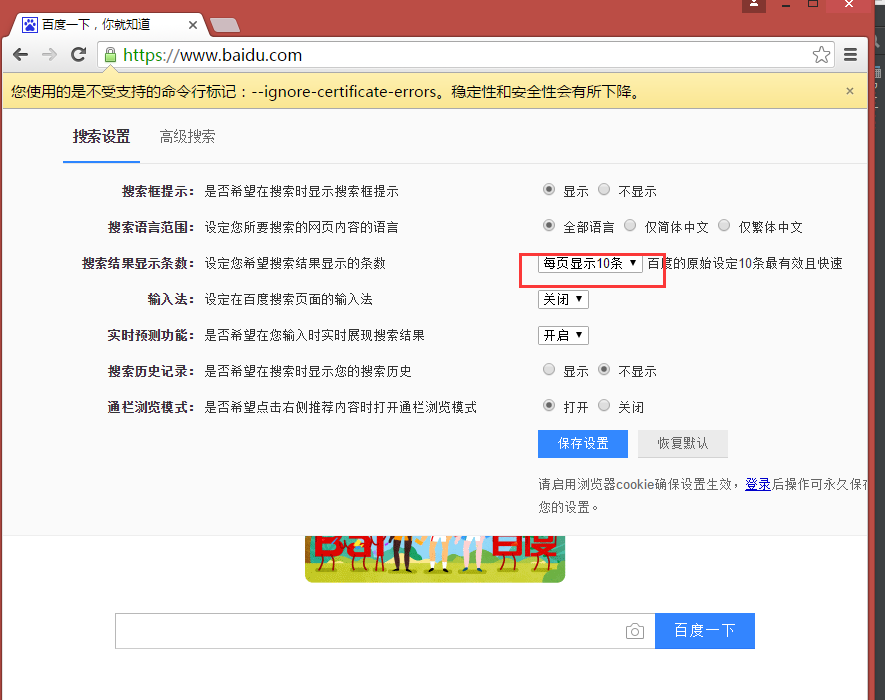
# 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text('搜索设置')[0].click()
sleep(2)
m = driver.find_element_by_id('nr')
sleep(2)
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
sleep(2)
# 处理弹出的警告页面
driver.find_element_by_class_name("prefpanelgo").click()
sleep(2)
driver.switch_to_alert().accept()
sleep(2)
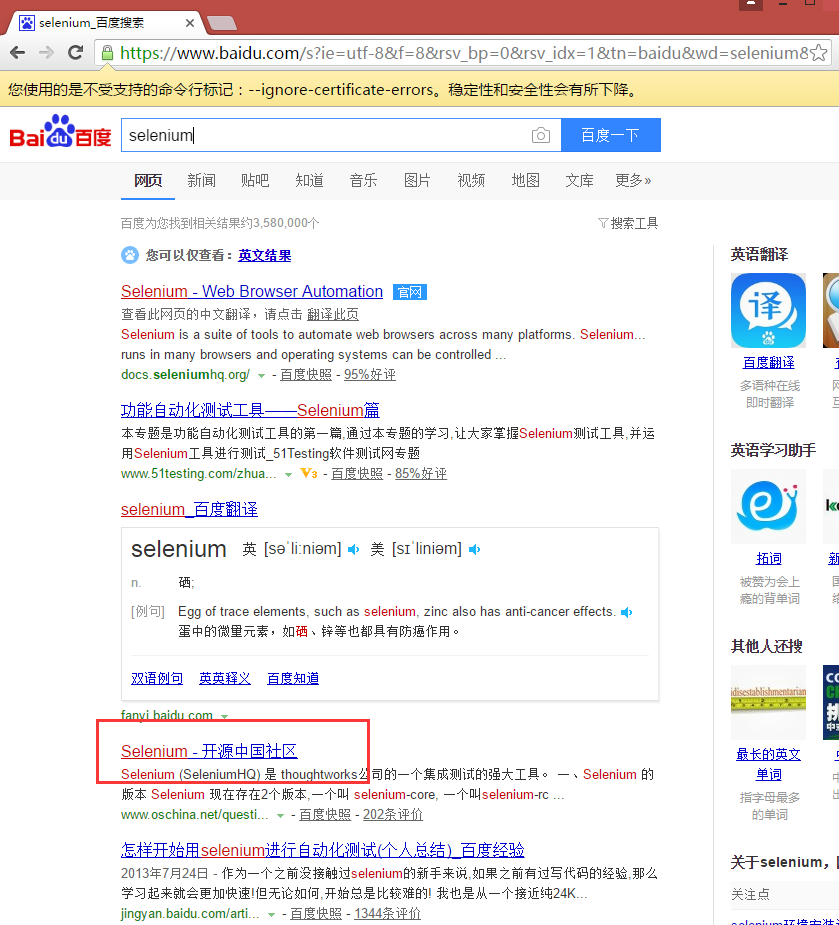
# 找到百度的输入框,并输入“selenium”
driver.find_element_by_id('kw').send_keys('selenium')
sleep(2)
# 点击搜索按钮
driver.find_element_by_id('su').click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text('Selenium - 开源中国社区')[0].click()
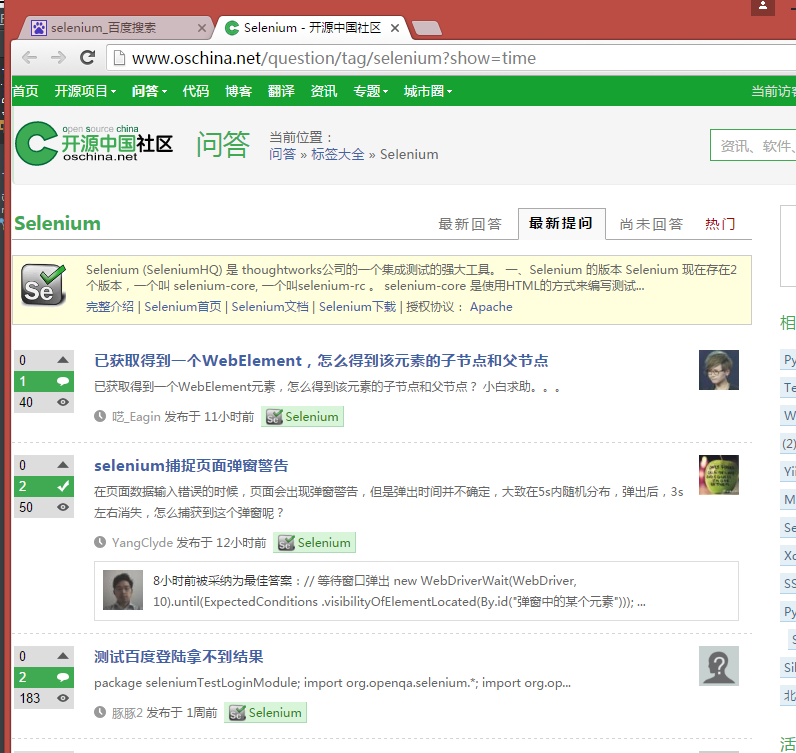
4.以下页面操作都是自动完成
【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium
前面几节,我们学习了用 requests 构造页面请求来爬取静态网页中的信息以及通过 requests 构造 Ajax 请求直接获取返回的 JSON 信息. 还记得前几节,我们在构造请求时会给请求加上 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
- Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看! Python爬虫教程-28-Selenium 操纵 Chrome PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面.Selenium + Phanto ...
- Python爬虫之selenium高级功能
Python爬虫之selenium高级功能 原文地址 表单操作 元素拖拽 页面切换 弹窗处理 表单操作 表单里面会有文本框.密码框.下拉框.登陆框等. 这些涉及与页面的交互,比如输入.删除.点击等. ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- selenium与chrome浏览器及驱动的版本匹配
用selenium+python+webdriver完成UI功能自动化,经常会碰到浏览器版本与驱动的版本不匹配而引起报错,下面就selenium与chrome浏览器及驱动的版本匹配 做个总结. 使用W ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- .net core 图片合并,图片水印,等比例缩小,SixLabors.ImageSharp
需要引用 SixLabors.ImageSharp 和SixLabors.ImageSharp.Drawing 引用方法 NuGet包管理 添加程序包来源 https://www.myget.org/ ...
- 「POJ 2182」 Lost Cows
题目链接 戳这 题目大意 \(N(2 <= N <= 8,000)\)头奶牛有\(1..N\)范围内的独特品牌.对于每头排队的牛,知道排在那头牛之前的并比那头牛的品牌小的奶牛数目.根据这些 ...
- 去掉textarea 右下角图标 resize: none;
如下图默认右下角有小图标: 加个样式: resize: none;就可以了:
- 整理LVS架构压力测试工作
首先,测试环境在模拟环境下进行. 测试环境:1director(apache2.2) + 1realserver(jboss4.2.3GA)+1databaseserver(oracle9i) ...
- Python之路番外:PYTHON基本数据类型和小知识点
Python之路番外:PYTHON基本数据类型和小知识点 一.基础小知识点 1.如果一行代码过长,可以用续行符 \换行书写 例子 if (signal == "red") and ...
- js去重方法
function remove(array){ var obj={}; newarray=[]; for(var i in array){ console.log(i); var arg=array[ ...
- Android 线程+Handler的使用
1.介绍 2.线程的使用 (1)启动 (2)执行 3.xml布局 <?xml version="1.0" encoding="utf-8"?> &l ...
- 洛谷 P2056 [ZJOI2007]捉迷藏 题解【点分治】【堆】【图论】
动态点分治入 门 题? 题目描述 Jiajia和Wind是一对恩爱的夫妻,并且他们有很多孩子.某天,Jiajia.Wind和孩子们决定在家里玩捉迷藏游戏.他们的家很大且构造很奇特,由 \(N\) 个屋 ...
- npm的介绍
npm使JavaScript开发人员能够轻松地共享和重用代码,并且可以轻松更新你正在共享的代码. 如果你一直在使用JavaScript,你可能已经听说过npm.npm使JavaScript开发人员能够 ...
- jQuery常用的方法
each() 以每一个匹配的元素作为上下文来执行一个函数. size() jQuery 对象中元素的个数.