OneHot编码
One-Hot编码 What、Why And When?
一句话概括:one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
目录:
前言:
通过例子可能更容易理解这个概念。
假设我们有一个迷你数据集:
| 公司名 | 类别值 | 价格 |
|---|---|---|
| VW | 1 | 20000 |
| Acura | 2 | 10011 |
| Honda | 3 | 50000 |
| Honda | 3 | 10000 |
其中,类别值是分配给数据集中条目的数值编号。比如,如果我们在数据集中新加入一个公司,那么我们会给这家公司一个新类别值4。当独特的条目增加时,类别值将成比例增加。
在上面的表格中,类别值从1开始,更符合日常生活中的习惯。实际项目中,类别值从0开始(因为大多数计算机系统计数),所以,如果有N个类别,类别值为0至N-1. skle[ar](https://www.jqr.com/service/company?business=17)的[LabelEncoder](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html)可以帮我们完成这一类别值分配工作。
现在让我们继续讨论one hot编码,将以上数据集one hot编码后,我们得到的表示如下:
| VW | Acura | Honda | 价格 |
|---|---|---|---|
| 1 | 0 | 0 | 20000 |
| 0 | 1 | 0 | 10011 |
| 0 | 0 | 1 | 50000 |
| 0 | 0 | 1 | 10000 |
WHY
在我们继续之前,你可以想一下为什么不直接提供标签编码给模型训练就够了?为什么需要one hot编码?
标签编码的问题是它假定类别值越高,该类别更好。“等等,什么!”
让我解释一下:根据标签编码的类别值,我们的迷你数据集中VW > Acura > Honda。比方说,假设模型内部计算平均值(神经网络中有大量加权平均运算),那么1 + 3 = 4,4 / 2 = 2. 这意味着:**VW和Honda平均一下是Acura**。毫无疑问,这是一个糟糕的方案。该模型的预测会有大量误差。(This is why we use one hot encoder to perform “binarization” of the category and include it as a feature to train the model.)
What
我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征,原因正在于此。
当然,如果我们在设计网络的时候考虑到这点,对标签编码的类别值进行特别处理,那就没问题。不过,在大多数情况下,使用one hot编码是一个更简单直接的方案。
最后,我们用一个例子总结下本文:
假设“花”的特征可能的取值为`daffodil`(水仙)、`lily`(百合)、`rose`(玫瑰)。one hot编码将其转换为三个特征:`is_daffodil`、`is_lily`、`is_rose`,这些特征都是二进制的。
When
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码。如果原本的标签编码是有序的,那one-hot编码就不合适了——会丢失顺序信息。
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
1. One-Hot Encoding 介绍:
在实际的应用场景中,有非常多的特征不是连续的数值变量,而是某一些离散的类别。比如在广告系统中,用户的性别,用户的地址,用户的兴趣爱好等等一系列特征,都是一些**分类值。这些特征一般都无法直接应用在需要进行数值型计算的算法里**,比如CTR预估中最常用的LR。那针对这种情况最简单的处理方式是将不同的类别映射为一个整数,比如男性是0号特征,女性为1号特征。这种方式最大的优点就是简单粗暴,实现简单。那最大的问题就是在这种处理方式中,各种类别的特征都被看成是有序的,这显然是非常不符合实际场景的。
为了解决上述问题,其中一种可能的解决方法是采用:
独热编码(One-Hot Encoding)
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用**N位状态寄存器来对N个状态进行编码**,每个状态都由**独立的寄存器位**,**并且在任意时候,其中只有一位有效**。可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了**m个二元特征**。并且,**这些特征互斥**,每次只有一个激活。因此,数据会变成稀疏的。(本段内容来自网络)
2. One-Hot 编码的优点
由第一部分的分析,很容易看出one hot编码的优点: 1.能够处理非连续型数值特征。 2.在一定程度上也扩充了特征。比如性别本身是一个特征,经过one hot编码以后,就变成了男或女两个特征。
3. 为什么能使用One-Hot(作用)
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。 (欧式空间的介绍请看另一篇博客https://blog.csdn.net/lulu950817/article/details/80424288)
将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
将离散型特征使用one-hot编码,可以会让特征之间的距离计算更加合理。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,其表示分别是x_1 = (1), x_2 = (2), x_3 = (3)。两个工作之间的距离是,(x_1, x_2) = 1, d(x_2, x_3) = 1, d(x_1, x_3) = 2。那么x_1和x_3工作之间就越不相似吗?显然这样的表示,计算出来的特征的距离是不合理。那如果使用one-hot编码,则得到x_1 = (1, 0, 0), x_2 = (0, 1, 0), x_3 = (0, 0, 1),那么两个工作之间的距离就都是sqrt(2).即每两个工作之间的距离是一样的,显得更合理。
4.sklearn里的One-Hot
1、sklearn链接:https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
2、源码:https://github.com/scikit-learn/scikit-learn/blob/bac89c2/sklearn/preprocessing/_encoders.py#L123
3、样例:
import numpy as np
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2]])
print "enc.n_values_ is:",enc.n_values_
print "enc.feature_indices_ is:",enc.feature_indices_
print enc.transform([[0, 1, 1]]).toarray()
代码运行结果:
enc.n_values_ is: [2 3 4]
enc.feature_indices_ is: [0 2 5 9]
[[ 1. 0. 0. 1. 0. 0. 1. 0. 0.]]
解释:
1、源码说明:
"""Encode categorical integer features using a one-hot aka one-of-K scheme.
The input to this transformer should be a matrix of integers, denoting
the values taken on by categorical (discrete) features. The output will be
a sparse matrix where each column corresponds to one possible value of one
feature. It is assumed that input features take on values in the range
[0, n_values).
This encoding is needed for feeding categorical data to many scikit-learn
estimators, notably linear models and SVMs with the standard kernels.
Read more in the :ref:`User Guide <preprocessing_categorical_features>`.
Attributes
----------
active_features_ : array
Indices for active features, meaning values that actually occur
in the training set. Only available when n_values is ``'auto'``.
feature_indices_ : array of shape (n_features,)
Indices to feature ranges.
Feature ``i`` in the original data is mapped to features
from ``feature_indices_[i]`` to ``feature_indices_[i+1]``
(and then potentially masked by `active_features_` afterwards)
n_values_ : array of shape (n_features,)
Maximum number of values per feature.
从上面可以看出 :
n_values_ : 每一维特征的种类数(shape)
feature_indices_ : n_values_的叠加
enc.transform([[0, 1, 1]]).toarray() : 表明将[0, 1, 1 ]样本输入,然后输出编码array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.]])
也可以: enc.fit_transform([[0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2]]) 直接输出这几个的one-hot编码结果
[1., 0., 0., 1., 0., 0., 1., 0., 0.]:前两位表示对 0 的编码,中间3为表示对 1 的编码,最后四位表示对 1 的编码,共9位。
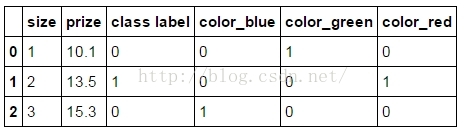
5. pandas中的get_dummies之One-Hot编码
1、用法:
import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
pd.get_dummies(df)
参考:
1、https://blog.csdn.net/bitcarmanlee/article/details/51472816
2、https://blog.csdn.net/weixin_42380251/article/details/80564652
4、https://blog.csdn.net/lulu950817/article/details/80424288
edit by Strange
2018.11.09
OneHot编码的更多相关文章
- 文本离散表示(二):新闻语料的one-hot编码
上一篇博客介绍了文本离散表示的one-hot.TF-IDF和n-gram方法,在这篇文章里,我做了一个对新闻文本进行one-hot编码的小实践. 文本的one-hot相对而言比较简单,我用了两种方法, ...
- one-hot编码理解
one-hot是比较常用的文本特征特征提取的方法. one-hot编码,又称“独热编码”.其实就是用N位状态寄存器编码N个状态,每个状态都有独立的寄存器位,且这些寄存器位中只有一位有效,说白了就是只能 ...
- Spark MLlib特征处理:OneHotEncoder OneHot编码 ---原理及实战
http://m.blog.csdn.net/wangpei1949/article/details/53140372 Spark MLlib特征处理:OneHotEncoder OneHot编码 - ...
- One-hot 编码/TF-IDF 值来提取特征,LAD/梯度下降法(Gradient Descent),Sigmoid
1. 多值无序类数据的特征提取: 多值无序类问题(One-hot 编码)把“耐克”编码为[0,1,0],其中“1”代表了“耐克”的中 间位置,而且是唯一标识.同理我们可以把“中国”标识为[1,0],把 ...
- Spark2 oneHot编码--标准化--主成分--聚类
1.导入包 import org.apache.spark.sql.SparkSession import org.apache.spark.sql.Dataset import org.apache ...
- 在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片
最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候, 还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的 ...
- 2.keras实现-->字符级或单词级的one-hot编码 VS 词嵌入
1. one-hot编码 # 字符集的one-hot编码 import string samples = ['zzh is a pig','he loves himself very much','p ...
- 机器学习入门-数值特征-数字映射和one-hot编码 1.LabelEncoder(进行数据自编码) 2.map(进行字典的数字编码映射) 3.OnehotEncoder(进行one-hot编码) 4.pd.get_dummies(直接对特征进行one-hot编码)
1.LabelEncoder() # 用于构建数字编码 2 .map(dict_map) 根据dict_map字典进行数字编码的映射 3.OnehotEncoder() # 进行one-hot编码 ...
- 机器学习入门-随机森林温度预测的案例 1.datetime.datetime.datetime(将字符串转为为日期格式) 2.pd.get_dummies(将文本标签转换为one-hot编码) 3.rf.feature_importances_(研究样本特征的重要性) 4.fig.autofmt_xdate(rotation=60) 对标签进行翻转
在这个案例中: 1. datetime.datetime.strptime(data, '%Y-%m-%d') # 由字符串格式转换为日期格式 2. pd.get_dummies(features) ...
随机推荐
- nexus3.14.0版本linux环境安装、启动、搭建私库
本文介绍的是nexus3.14.0版本在linux环境下安装.启动.搭建私库. nexus3以上的版本太新了,网上很少介绍安装细节的.据了解和2.X版本有所不同了. 1.前提 linux机器上需先安装 ...
- mybatis-plus的代码生成器
简介:构建自定义mybatis-plus模板,自动生成mybatis,entity,mapper,service,controller 项目源码:https://github.com/y369q369 ...
- 在线学习在CTR上应用的综述
参考:https://mp.weixin.qq.com/s/p10_OVVmlcc1dGHNsYMQwA 在线学习只是一个机器学习的范式(paradigm),并不局限于特定的问题,模型或者算法. 架构 ...
- ubuntu 装机步骤表
步骤 1. root 步骤 apt-get update ; apt-get upgrate apt-get install git zsh apt-get install -y make build ...
- linux centos7下mysql安装--韩国庆
首先我先给大家介绍下MariaDB和mysql的区别. 上图,“MySQL之父”的骨灰级程序员Monty,但是mysql被Oracle收购后,Monty又开始去发展另一条数据库的道路,并且以Monty ...
- LeetCode1-5题
1.两数之和 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个 ...
- 【Python学习】Python3 环境搭建
参考地址:http://www.runoob.com/python3/python3-install.html Python3 环境搭建 本章节我们将向大家介绍如何在本地搭建 Python3 开发环境 ...
- 个人简介HTML
码云链接:https://gitee.com/lengxiaoyixuan222/codes/z4dxnvr0ce2blpkihsg7985 源代码: <!doctype html> &l ...
- ORACLE导出导入意外终止导致 ORACLE initialization or shutdown in progress 问题解决
由于意外情况导致 ORACLE initialization or shutdown in progress 个人理解为主要是归档日志出现问题, 首先cmd 1.sqlplus /nolog 进入s ...
- 将自己的SpringBoot应用打包发布到Linux下Docker中
目录 将自己的SpringBoot应用打包发布到Linux下Docker中 1. 环境介绍 2. 开始前的准备 2.1 开启docker远程连接 2.2 新建SpringBoot项目 3. 开始构建我 ...