Elasticsearch学习笔记——安装、数据导入和查询
到elasticsearch网站下载最新版本的elasticsearch 6.2.1
|
1
|
https://www.elastic.co/downloads/elasticsearch |
中文文档请参考
|
1
|
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html |
英文文档及其Java API使用方法请参考,官方文档比任何博客都可信
|
1
|
https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html |
Python API使用方法
|
1
|
http://elasticsearch-py.readthedocs.io/en/master/ |
下载tar包,然后解压到/usr/local目录下,修改一下用户和组之后可以使用非root用户启动,启动命令
|
1
|
./bin/elasticsearch |
然后访问http://127.0.0.1:9200/

如果需要让外网访问Elasticsearch的9200端口的话,需要将es的host绑定到外网
修改 /configs/elasticsearch.yml文件,添加如下
|
1
2
|
network.host: 0.0.0.0http.port: 9200 |
然后重启,如果遇到下面问题的话
|
1
2
3
4
|
[2018-01-28T23:51:35,204][INFO ][o.e.b.BootstrapChecks ] [qR5cyzh] bound or publishing to a non-loopback address, enforcing bootstrap checksERROR: [2] bootstrap checks failed[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536][2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] |
解决方法
在root用户下执行
|
1
|
sysctl -w vm.max_map_count=262144 |
接下来导入json格式的数据,数据内容如下
|
1
2
3
4
|
{"index":{"_id":"1"}}{"title":"许宝江","url":"7254863","chineseName":"许宝江","sex":"男","occupation":" 滦县农业局局长","nationality":"中国"}{"index":{"_id":"2"}}{"title":"鲍志成","url":"2074015","chineseName":"鲍志成","occupation":"医师","nationality":"中国","birthDate":"1901年","deathDate":"1973年","graduatedFrom":"香港大学"} |
需要注意的是{"index":{"_id":"1"}}和文件末尾另起一行换行是不可少的
其中的id可以从0开始,甚至是abc等等
否则会出现400状态,错误提示分别为
|
1
|
Malformed action/metadata line [1], expected START_OBJECT or END_OBJECT but found [VALUE_STRING] |
|
1
|
The bulk request must be terminated by a newline [\n]" |
使用下面命令来导入json文件
其中的people.json为文件的路径,可以是/home/common/下载/xxx.json
其中的es是index,people是type,在elasticsearch中的index和type可以理解成关系数据库中的database和table,两者都是必不可少的
|
1
|
curl -H "Content-Type: application/json" -XPOST 'localhost:9200/es/people/_bulk?pretty&refresh' --data-binary "@people.json" |
成功后的返回值是200,比如
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
{ "took" : 233, "errors" : false, "items" : [ { "index" : { "_index" : "es", "_type" : "people", "_id" : "1", "_version" : 1, "result" : "created", "forced_refresh" : true, "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } }, { "index" : { "_index" : "es", "_type" : "people", "_id" : "2", "_version" : 1, "result" : "created", "forced_refresh" : true, "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 } } ]} |
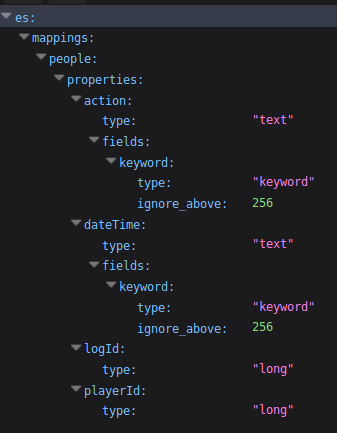
<0>查看字段的mapping
|
1
|
http://localhost:9200/es/people/_mapping |
接下来可以使用对应的查询语句对数据进行查询
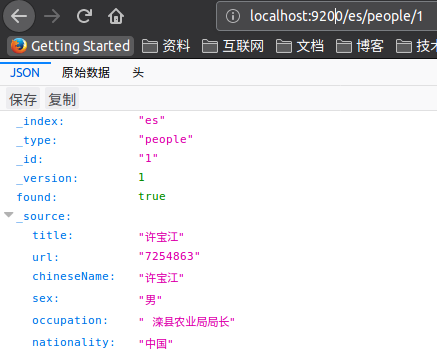
<1>按id来查询
|
1
|
http://localhost:9200/es/people/1 |
<2>简单的匹配查询,查询某个字段中包含某个关键字的数据(GET)
|
1
|
http://localhost:9200/es/people/_search?q=_id:1 |
|
1
|
http://localhost:9200/es/people/_search?q=title:许 |

<3>多字段查询,在多个字段中查询包含某个关键字的数据(POST)
可以使用Firefox中的RESTer插件来构造一个POST请求,在升级到Firefox quantum之后,原来使用的Poster插件挂了
在title和sex字段中查询包含 许 字的数据
|
1
2
3
4
5
6
7
8
|
{ "query": { "multi_match" : { "query" : "许", "fields": ["title", "sex"] } }} |


还可以额外指定返回值
size指定返回的数量
from指定返回的id起始值
_source指定返回的字段
highlight指定语法高亮
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
{ "query": { "multi_match" : { "query" : "中国", "fields": ["nationality", "sex"] } }, "size": 2, "from": 0, "_source": [ "title", "sex", "nationality" ], "highlight": { "fields" : { "title" : {} } }} |
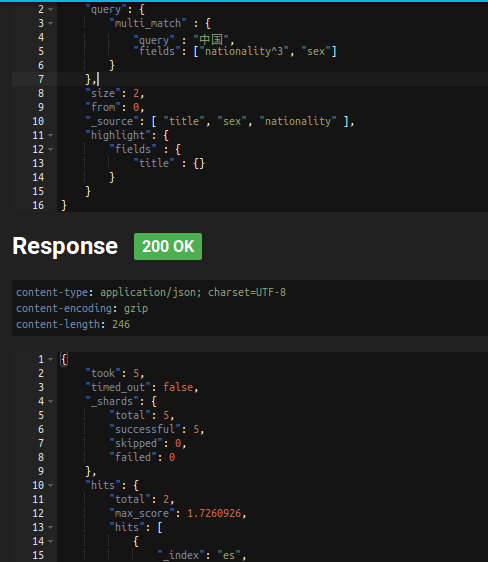
<4>Boosting
用于提升字段的权重,可以将max_score的分数乘以一个系数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
{ "query": { "multi_match" : { "query" : "中国", "fields": ["nationality^3", "sex"] } }, "size": 2, "from": 0, "_source": [ "title", "sex", "nationality" ], "highlight": { "fields" : { "title" : {} } }} |
<5>组合查询,可以实现一些比较复杂的查询
AND -> must
NOT -> must not
OR -> should
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
{ "query": { "bool": { "must": { "bool" : { "should": [ { "match": { "title": "鲍" }}, { "match": { "title": "许" }} ], "must": { "match": {"nationality": "中国" }} } }, "must_not": { "match": {"sex": "女" }} } }} |
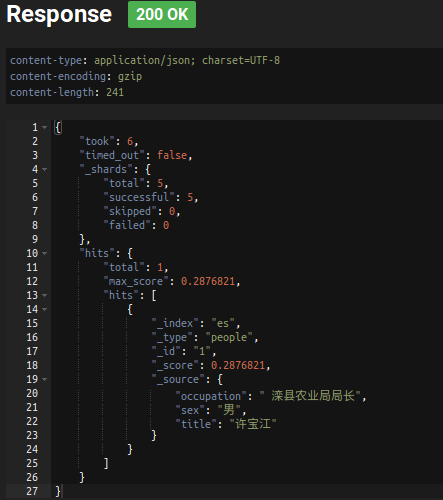
<6>模糊(Fuzzy)查询(POST)
|
1
2
3
4
5
6
7
8
9
10
11
|
{ "query": { "multi_match" : { "query" : "厂长", "fields": ["title", "sex","occupation"], "fuzziness": "AUTO" } }, "_source": ["title", "sex", "occupation"], "size": 1} |
通过模糊匹配将 厂长 和 局长 匹配上
AUTO的时候,当query的长度大于5的时候,模糊值指定为2
<7>通配符(Wildcard)查询(POST)
? 匹配任何字符
* 匹配零个或多个字
|
1
2
3
4
5
6
7
8
9
|
{ "query": { "wildcard" : { "title" : "*宝" } }, "_source": ["title", "sex", "occupation"], "size": 1} |
<8>正则(Regexp)查询(POST)
|
1
2
3
4
5
6
7
8
9
|
{ "query": { "regexp" : { "authors" : "t[a-z]*y" } }, "_source": ["title", "sex", "occupation"], "size": 3} |
<9>短语匹配(Match Phrase)查询(POST)
短语匹配查询 要求在请求字符串中的所有查询项必须都在文档中存在,文中顺序也得和请求字符串一致,且彼此相连。
默认情况下,查询项之间必须紧密相连,但可以设置 slop 值来指定查询项之间可以分隔多远的距离,结果仍将被当作一次成功的匹配。
|
1
2
3
4
5
6
7
8
9
10
11
|
{ "query": { "multi_match" : { "query" : "许长江", "fields": ["title", "sex","occupation"], "type": "phrase" } }, "_source": ["title", "sex", "occupation"], "size": 3} |
注意使用slop的时候距离是累加的,滦农局 和 滦县农业局 差了2个距离
|
1
2
3
4
5
6
7
8
9
10
11
12
|
{ "query": { "multi_match" : { "query" : "滦农局", "fields": ["title", "sex","occupation"], "type": "phrase", "slop":2 } }, "_source": ["title", "sex", "occupation"], "size": 3} |
<10>短语前缀(Match Phrase Prefix)查询(POST)
Elasticsearch学习笔记——安装、数据导入和查询的更多相关文章
- ArcGIS案例学习笔记_3_2_CAD数据导入建库
ArcGIS案例学习笔记_3_2_CAD数据导入建库 计划时间:第3天下午 内容:CAD数据导入,建库和管理 目的:生成地块多边形,连接属性,管理 问题:CAD存在拓扑错误,标注位置偏移 教程:pdf ...
- Elasticsearch+Mongo亿级别数据导入及查询实践
数据方案: 在Elasticsearch中通过code及time字段查询对应doc的mongo_id字段获得mongodb中的主键_id 通过获得id再进入mongodb进行查询 1,数据情况: ...
- clickhouse安装数据导入及查询测试
官网 https://clickhouse.tech/ quick start ubantu wget https://repo.yandex.ru/clickhouse/deb/lts/main/c ...
- elasticsearch学习笔记——安装,初步使用
前言 久仰elasticsearch大名,近年来,fackbook,baidu等大型网站的搜索功能均开始采用elasticsearch,足见其在处理大数据和高并发搜索中的卓越性能.不少其他网站也开始将 ...
- Elasticsearch学习笔记(十)批量查询mget、批量增删改bulk
一.批量查询 mget GET /_mget { "docs":[ { "_index":" ...
- ElasticSearch学习笔记--安装
1.安装ElasticSearch https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html 这 ...
- GIS案例学习笔记-CAD数据分层导入现有模板实例教程
GIS案例学习笔记-CAD数据分层导入现有模板实例教程 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 1. 原始数据: CAD数据 目标模板 2. 任务:分5个图层 ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
随机推荐
- HDU2204 Eddy's爱好
题意:给你一个正整数N,确定在1到N之间有多少个可以表示成M^K(K>1)的数. 解析:一个数N 开K次根后得到M 则小于M的所有数的K次方一定小于N 因为任何一个合数都能分解为素数的乘积 所 ...
- [hexo]如何更换主题、删除文章
如何修改主题 hexo有很多主题,每个人可以选择自己喜欢的主题来应用,也可以自己设计主题并且上传形成公共主题供大家下载. 如果是自己设计主题的话,会稍微麻烦一些,需要自己配置很多文件,并且编写css以 ...
- jsp (2)
一.内置对象: 二.如何在代码中使用js代码: <script type="text/javascript" src="js的路径名"></s ...
- JAVA多线程之当一个线程在执行死循环时会影响另外一个线程吗?
一,问题描述 假设有两个线程在并发运行,一个线程执行的代码中含有一个死循环如:while(true)....当该线程在执行while(true)中代码时,另一个线程会有机会执行吗? 二,示例代码(代码 ...
- JAVA中循环删除list中元素
文章来源: https://www.cnblogs.com/pcheng/p/5336903.html JAVA中循环遍历list有三种方式for循环.增强for循环(也就是常说的foreach循环) ...
- [luogu1486][郁闷的出纳员]
题目链接 思路 这个题其实就是对于treap中的删除操作进行一些修改.自己yy了一种做法.就是在删除的时候,如果要删除的数比这棵子树的根大,那么就把根变成根的右孩子,这样就相当于删除了整棵左子树和根节 ...
- mciSendString 多线程播放多首音乐 & 注意事项
昨天晚上遇到一个问题: 使用 mciSendString 控制播放多首音乐的时候,出现最后一次播放的音乐无法通过 mciSendString ("close mp3") 关闭音乐 ...
- Python基础语法总结
1.Python标识符 在 Python 里,标识符有字母.数字.下划线组成. 在 Python 中,所有标识符可以包括英文.数字以及下划线(_),但不能以数字开头. Python 中的标识符是区分大 ...
- POJ 2728 Desert King (01分数规划)
Desert King Time Limit: 3000MS Memory Limit: 65536K Total Submissions:29775 Accepted: 8192 Descr ...
- C#语法糖(Csharp Syntactic sugar)
目录 一.C#语法糖大汇总 1. 经过简化的Property2. 经过两次变异的委托写法3. 集合类的声明4. 集合类各个项的操作5. using == try finally6. 可爱的var7. ...