PageRank与TrustRank影响因素分析
PageRank(PR)里的page不是指网页,而是指Google创始人拉里?佩奇(Larry Page),是他在2001年申请的专利中以自己名字命名的,Google的PageRank根据网站的外部链接和内部链接的数量和质量来衡量网站的价值。
TrustRank(信任指数)是2006年雅虎申请的一项专利,Trust Rank是用来检测垃圾网站的,但现在的搜索引擎排名算法中,常常影响大部分网站的整体排名,有意思的是大家通常所说的TrustRank多是指Google算法。

Google PageRank的缺陷
我们知道,网站的PR值往往是显示过去2-3个月某一个时间点的数值,而且最最重要的原因是PR值的大小是靠大量引入站外链接就能获得好的数值,这种手法可以作弊、可以买卖链接,都能达到效果。实际上PageRank的因素比仅仅是这一点,做作为最重要的因素,也代表这PageRank的判断手法。
Google也意识到这个问题了,并在上次PR更新后发表博文说到:“多年来Google网站管理员中心团队一直在告诫广大网站站长,不应该如此依赖PageRank,将其视为代表网站成功度的指标。”而且卢松松通过实践也证明,PR值的高低和网页的排名关系不大。
关于TrustRank
Google TrustRank的影响已经越来越明显,TrustRank采用半人工的方式,通过Google或其他一些检索机构的专家,先确定一批站点的TR值,再通过机器的连接结构分析来确定其他网站的TR值。
也许是吸取了PageRank的教训(通过Google工具条可以查看PR,很多第三方网站就是引用的工具条里的数据),TrustRank不会提供任何查询方式,只能靠猜。
我还是试图找到能查询TR值的网站,国外的CheckTrustRank和trustrank.org两个网站打着能查询TR的旗号,经过卢松松测试CheckTrustRank还算靠点谱,网易、QQ值均为8,新浪TR值为9,不过这个网站总是出现错误,而且貌似和PR值也雷同。
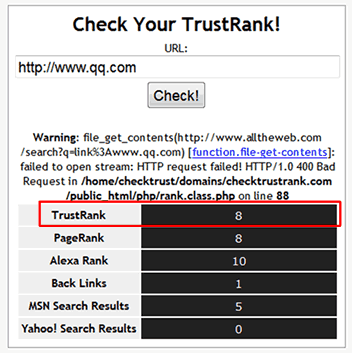
影响TrustRank值的因素
1:外部连接的高质量链接,Google实际上鼓励高质量网站连接的,与这样的网站链接越多TR值就越高,也就更容易被Google和Yahoo搜到,使用“nofollow”标签往往就是区分链接垃圾网站和高质量网站的一个重要依据。
2:内容是原创的,投入时间和精力持续不断的增加原创内容,在网站有良好用户体验的同时,看上去更专业,在这一领域树立权威。
3:域名的年龄是一个重要因素,5-6年的域名有较高的排名,这样搜索引擎可以很容易检测到spam活动。
4:反向链接相关度,如果你购买了50个PR3-4的反向链接,Google是很容易检测出的,如果不是相关网站,这些链接可能会降低你的TR排名。
5:内容重复度,造成流量下降一个重要原因就是几百个网站的内容出现重复,往往倒霉的是那些小网站。
6:服务器的质量,包括独立的IP、网站能够持续稳定的可访问,网站被多个国际IP段引用。
原文:http://lusongsong.com/reed/357.html
PageRank与TrustRank影响因素分析的更多相关文章
- webkit浏览器渲染影响因素分析
前言:浏览器的渲染对性能影响非常大,特别是在移动端页面,在宏观上,我们可以参考雅虎那20几条军规来操作,但在微观渲染层面,实际还没有一套相对成型的理论做为依据. 本文只是抛砖引玉,带大家进入微观的优化 ...
- golang bufio、ioutil读文件的速度比较(性能测试)和影响因素分析
前言 golang读取文件的方式主要有4种: 使用File自带的Read方法 使用bufio库的Read方法 使用io/ioutil库的ReadAll() 使用io/ioutil库的ReadFile( ...
- Entity Framework性能影响因素分析
1.对象管理机制-复杂为更好的管理模型对象,EF提供了一套内部管理机制和跟踪对象的状态,保存对象一致性,使用方便,但是性能有所降低. 2.执行机制-高度封装在EF中,所有的查询表达式都会经过语法分析. ...
- Social Network Analysis的Centrality总结,以及networkx实现EigenCentrality,PageRank和KatzCentrality的对比
本文主要总结近期学习的Social Network Analysis(SNA)中的各种Centrality度量,我暂且翻译为中心度.本文主要是实战,理论方面几乎没有,因为对于庞大的SNA,我可能连门都 ...
- 我对PageRank的理解及R语言实现
PageRank,网页排名,又称网页级别.Google左侧排名或佩奇排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry ...
- Learning to Rank:pointwise, pairwise, listwise 总结
值得看: 刘铁岩老师的<Learning to Rank for Information Retrieval>和李航老师的<Learning to rank for informat ...
- 推荐排序---Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点
转载:https://blog.csdn.net/lipengcn/article/details/80373744 Ranking 是信息检索领域的基本问题,也是搜索引擎背后的重要组成模块. 本文将 ...
- (视频) 《快速创建网站》 2.3 WordPress初始化和功能简介
本文是<快速创建网站>系列的第4篇,如果你还没有看过之前的内容,建议你点击以下目录中的章节先阅读其他内容再回到本文. 访问本系列目录,请点击:http://devopshub.cn/tag ...
- 高性能的EMI滤波器及其小型化设计技术
1 EMI滤波器的常见问题及发展趋势首先介绍了影响EMI滤波器性能/体积的因素及EMI滤波器的常见问题:低频传导发射高.高频传导/辐射发射高.体积大,从而分析出EMI滤波器的发展趋势为高性能和小体积, ...
随机推荐
- iOS中JS 与OC的交互(JavaScriptCore.framework)
iOS中实现js与oc的交互,目前网上也有不少流行的开源解决方案: 如:react native 当然一些轻量级的任务使用系统提供的UIWebView 以及JavaScriptCore.framewo ...
- cookie预:
什么是cookie? cookie 是存储于访问者的计算机中的变量.每当同一台计算机通过浏览器请求某个页面时,就会发送这个 cookie.你可以使用 JavaScript 来创建和取回 cookie ...
- junit基础篇、中级篇-实例代码
学习文章: http://blog.csdn.net/andycpp/article/details/1327147 http://wenku.baidu.com/link?url=C27gDEj0l ...
- maven设置
<localRepository>D:/apps/eclipse/env/maven/repository</localRepository>
- guava学习--File
使用Files类来执行那些基本的任务,比如:移动或复制文件,或读取文件内容到一个字符串集合 Closer类,提供了一种非常干净的方式,确保Closeable实例被正确的关闭 ByteSource 和 ...
- MyBatis关联查询 (association) 时遇到的某些问题/mybatis映射
先说下问题产生的背景: 最近在做一个用到MyBatis的项目,其中有个业务涉及到关联查询,我是将两个查询分开来写的,即嵌套查询,个人感觉这样更方便重用: 关联的查询使用到了动态sql,在执行查询时就出 ...
- WEB UI 整理
当下对于网站前段开发人员来说,很少有人不使用一些JS框架或者WEB UI库,因此这些可以有效提高网站前段开发速度,并且能够统一开发环境,对于不同浏览器的兼容性也不需要程序员操心,有了这些优点,当然大家 ...
- Selenium - CSS Selector
Selenium - CSS Selector http://www.cnblogs.com/bugua/archive/2012/08/16/2641647.html 昨天我练习了用CSS(即层 ...
- 【0 - 1】OC内存管理
一.内存管理概述 垃圾回收机制(GC):由系统管理内存,程序员不需要管理. OC中的垃圾回收:在OC2.0版加入垃圾回收. OC与iOS:OC有垃圾回收机制,但是iOS屏蔽了这个功能.原因:iOS运行 ...
- HTTP 304
304 的标准解释是:Not Modified 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档).服务器告诉客户,原来缓冲的 ...