HBase独立集群部署
HBase是分布式、面向列式存储的开源数据库,来源于Google的论文BigTable,HBase运行于Hadoop平台之上,不同于一般的关系数据库,是一个适合非结构化数据存储的分布式数据库
安装Hbase之前首先系统应该做通用的集群环境准备工作,这些是必须的:
1、集群中主机名必须正确配置,最好有实际意义;并且主机名都在hosts文件中对应主机IP,一一对应,不可缺少
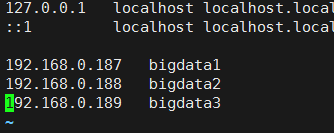
这里是3台主机,分别对应
2、JDK环境正确安装
3、集群中每台机器关闭防火墙,保证通信畅通
4、配置集群间ssh免密登录
5、集群ntp服务开启,保证时间同步
6、Hadoop HDFS服务开启
前面5步都配置好的基础上,首先配置Hadoop集群,在bigdata1上做配置操作
首先解压hadoop,并安装至指定目录:
tar -xvzf hadoop-2.6..tar.gz
mkdir /bigdata/hadoop
mv hadoop-2.6. /bigdata/hadoop
cd /bigdata/hadoop/hadoop-2.6.
就是简单的释放,然后为了方便可以将HADOOP_HOME添加至环境变量
配置hadoop需要编辑以下几个配置文件:
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves
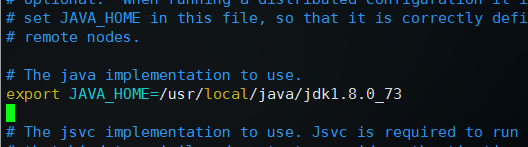
1、编辑hadoop-env.sh
修改export JAVA_HOME=${JAVA_HOME}为自己的实际安装位置
这里是export JAVA_HOME=/usr/local/java/jdk1.8.0_73
2、编辑core-site.xml,在configuration标签中间添加如下代码:
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmp</value>
</property>
其中bigdata1是namenode节点
3、编辑hdfs-site.xml ,添加如下代码:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///bigdata/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///bigdata/hadoop/hdfs/data</value>
</property>
<!-- 这个地方是为Hbase的专用配置,最小为4096,表示同时处理文件的上限,不配置会报错 -->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
关于第4组配置已经注释说明了
4、编辑mapred-site.xml,添加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5、编辑yarn-site.xml,添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
6、编辑slaves,添加datanode节点
bigdata2
bigdata3
这些都保存完毕,将/bigdata/下的hadoop目录整体发送至集群中其他主机,其他主机应该事先建立好bigdata目录
scp -r /bigdata/hadoop bigdata2:/bigdata
scp -r /bigdata/hadoop bigdata3:/bigdata
然后在bigdata1上格式化文件系统:
bin/hdfs namenode -format
然后启动hdfs服务:
sbin/start-dfs.sh
启动完成之后,执行 jps 命令,在主节点可以看到NameNode和SecondaryNameNode进程;其他节点可以看到DataNode进程
然后启动yarn守护进程: sbin/start-yarn.sh
主节点会增加:ResourceManager进程,其他节点会增加:NodeManager进程
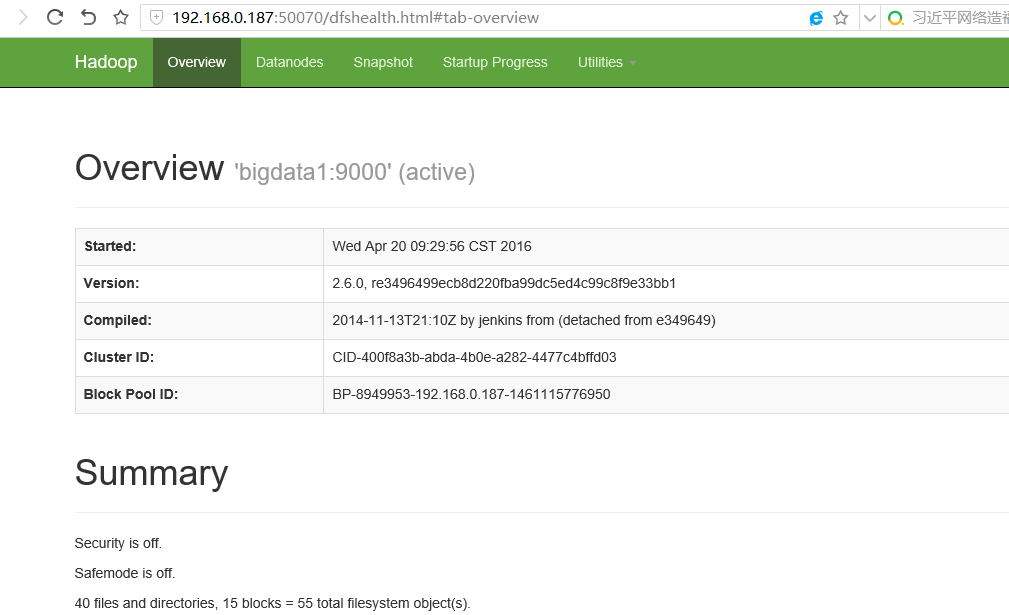
现在通过浏览器可以打开相应的管理界面,以bigdata1的IP访问:
http://192.168.0.187:50070
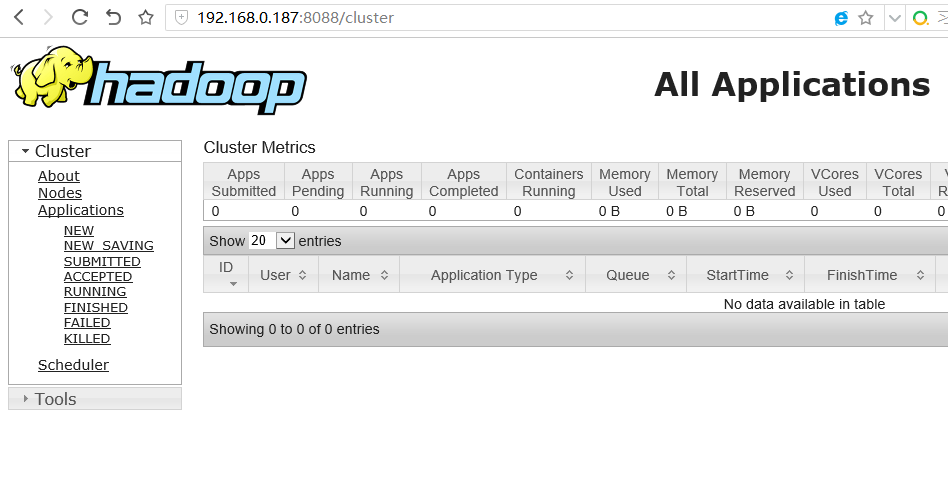
http://192.168.0.187:8088
到这里hadoop hdfs就部署完成了,然后开始部署HBase,这里使用的版本为:hbase-0.98.18-hadoop2-bin.tar.gz
和释放hadoop包一样将hbase释放到对应的目录并进入,这里是:/bigdata/hbase/hbase-0.98.18-hadoop2
首先编辑配置文件: vim conf/hbase-env.sh
去掉JAVA_HOME前面的注释,改为自己实际的JDK安装路径,和配置hadoop类似

然后,去掉export HBASE_MANAGES_ZK=true前面的注释并改为export HBASE_MANAGES_ZK=false,配置不让HBase管理Zookeeper
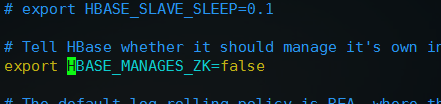
配置完这两项之后,保存退出
编辑文件 vim conf/hbase-site.xml 在configuration标签之间加入如下配置:
<!-- 指定HBase在HDFS上面创建的目录名hbase -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://bigdata1:9000/hbase</value>
</property>
<!-- 开启集群运行方式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
分别将hadoop配置下的core-site.xml和hdfs-site.xml复制或者做软链接到hbase配置目录下:
cp /bigdata/hadoop/hadoop-2.6./etc/hadoop/core-site.xml conf/
cp /bigdata/hadoop/hadoop-2.6./etc/hadoop/hdfs-site.xml conf/
执行 vim conf/regionservers 编辑运行regionserver存储服务的Hbase节点,就相当于hadoop slaves中的DataNode节点
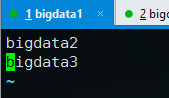
保存之后,配置完毕,将hbase发送至其他数据节点:
scp -r /bigdata/hbase/ bigdata2:/bigdata/
scp -r /bigdata/hbase/ bigdata3:/bigdata/
然后在bigdata1启动Hbase
bin/start-hbase.sh
启动成功,在bigdata1会增加进程:HMaster 在bigdata2和bigdata3会增加进程:HRegionServer
到这里HBase就部署完毕,这里没有包含Zookeeper
执行命令: /bigdata/hadoop/hadoop-2.6./bin/hdfs dfs -ls / 可以查看hbase是否在HDFS文件系统创建成功

看到/hbase节点表示创建成功
然后执行: bin/hbase shell 可以进入Hbase管理界面
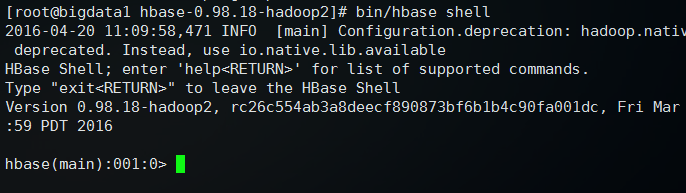
输入 status 查看状态

返回状态,表示HBase可以正常使用
输入 quit 可以退出管理,回到命令行
HBase独立集群部署的更多相关文章
- HBase集群部署与基础命令
HBase 集群部署 安装 hbase 之前需要先搭建好 hadoop 集群和 zookeeper 集群.hadoop 集群搭建可以参考:https://www.cnblogs.com/javammc ...
- Hbase集群部署及shell操作
本文详述了Hbase集群的部署. 集群部署 1.将安装包上传到集群并解压 scp hbase-0.99.2-bin.tar.gz mini1:/root/apps/ tar -zxvf hbase-0 ...
- HBase 集群部署
前提条件:hadoop及zookeeper机群已经搭建好. 配置hbase集群步骤: 1.配置hbase集群,要修改3个文件 注意:要把hadoop的hdfs-site.xml和core-site. ...
- Hbase集群部署
1.安装Hadoop集群 这个之前已经写过 2.安装Zookeeper 这个之前也已经写过 3.下载hbase,放到master机器,解压 4.修改hbase-env.sh,添加Java地址 expo ...
- HBase集群部署脚本
#!/bin/bash # Sync HBASE_HOME across the cluster. Must run on master using HBase owner user. HBASE_H ...
- HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程: 安装Hbase之前首先系统应该做通 ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- 在Azure HDInsight HBase集群中使用Thrift接口
Sun wei Wed, Feb 25 2015 2:17 AM Apache Thrift 是一种可扩展的跨语言服务接口,可以通过内置的代码生成引擎帮助创建跨语言服务类库,Apache HBase ...
- 基于Hadoop集群的HBase集群的配置
一 Hadoop集群部署 hadoop配置 二 Zookeeper集群部署 zookeeper配置 三 Hbase集群部署 1.配置hbase-env.sh HBASE_MANAGES_ZK:用来 ...
随机推荐
- C# 协变out 、逆变 in
需求:泛型使用多态性 备注:协变逆变只能修饰 接口和委托 简单理解: 1.使用 in 修饰后为逆变,只能用作形参使用 ,参考 public delegate void Action<in T&g ...
- Linux jdk1.7安装与 jdk1.6卸载
昨天安装zookeeper时需要java环境,也就是安装jdk 安装完jdk1.7后,配置好环境变量, vim ~/.bashrc JAVA_HOME=安装路径 export PAT ...
- Dirty Markup - 在线代码美化工具
如果你需要一个帮助你规整书写混乱的代码的工具的话,我强烈推荐给你这个在线代码美化工具 - Dirty Markup.这个在线工具能够帮助你有效的处理HTML/HTML5,CSS和javascript代 ...
- 【R】如何确定最适合数据集的机器学习算法 - 雪晴数据网
[R]如何确定最适合数据集的机器学习算法 [R]如何确定最适合数据集的机器学习算法 抽查(Spot checking)机器学习算法是指如何找出最适合于给定数据集的算法模型.本文中我将介绍八 ...
- 第一天 django
全栈增长工程师实战 http://growth-in-action.phodal.com/ 生成的代码和示例不一样,static 也要加上 from django.conf.urls import u ...
- php远程连接http方式
以下这三者是通过GET方式来获取数据 1.socket 方式 一般是指定网址.端口号.超时时间. 再对报头进行修改以及传递参数,包括:header.method.content, 返回的内容包括hea ...
- 读w3c中文教程对键盘事件解释的感想 -遁地龙卷风
写这篇博文源于w3c中文教程对键盘事件的解释, onkeydown 某个键盘按键被按下 onkeypress 某个键盘按键被按下并松开 onkeyup 某个键盘按键被松开 可在实践中发现 只注册key ...
- BZOJ1503——郁闷的出纳员
1.题目大意:一道treap题,支持插入,询问第K大,还有全体修改+上一个值,如果某个点值小于x,那么就删除这个点 插入100000次,询问100000次,修改100次..最后输出删了多少个点 2.分 ...
- C,C++经典笔试题(答案)转自:http://blog.163.com/jianhuali0118@126/blog/static/377499702008230104125229/
一.请填写BOOL , float, 指针变量 与“零值”比较的 if 语句.(10分) 请写出 BOOL flag 与“零值”比较的 if 语句.(3分) 标准答案: if ( fla ...
- 表单select相关
selectedIndex 属性可设置或返回下拉列表中被选选项的索引号. options[] 返回包含下拉列表中的所有选项的一个数组. add()向下拉列表添加一个选项. blur()从下拉列表移开焦 ...