GROUP BY中的WITH CUBE、WITH ROLLUP原理测试及GROUPING应用
前几天,看到一个群友用WITH ROLLUP运算符。由于自个儿没用过,看到概念及结果都云里雾里的,所以突然来了兴趣对生成结果测了一番。
一、概念:
WITH CUBE:生成的结果集显示了所选列中值的所有组合的聚合。
WITH ROLLUP:生成的结果集显示了所选列中值的某一层次结构的聚合。
GROUPING:当行由 WITH CUBE或WITH ROLLUP运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
二、测试:
1、建立临时表
CREATE TABLE #T0
(
[GRADE] [VARCHAR](50) NULL, --年级
[CLASS] [VARCHAR](50) NULL, --班级
[NAME] [VARCHAR](50) NULL, --姓名
[COURSE] [VARCHAR](50) NULL, --学科
[RESULT] [NUMERIC](8,2) NULL --成绩
) CREATE TABLE #T1
(
[ID] [INT] IDENTITY(1,1) NOT NULL, --序号
[GRADE] [VARCHAR](50) NULL, --年级
[CLASS] [VARCHAR](50) NULL, --班级
[NAME] [VARCHAR](50) NULL, --姓名
[COURSE] [VARCHAR](50) NULL, --学科
[RESULT] [NUMERIC](8,2) NULL --成绩
) CREATE TABLE #T2
(
[ID] [INT] IDENTITY(1,1) NOT NULL, --序号
[GRADE] [VARCHAR](50) NULL, --年级
[CLASS] [VARCHAR](50) NULL, --班级
[NAME] [VARCHAR](50) NULL, --姓名
[COURSE] [VARCHAR](50) NULL, --学科
[RESULT] [NUMERIC](8,2) NULL --成绩
)
2、插入测试数据
INSERT INTO #T0 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT '','CLASS1','9A01','C#',100
UNION
SELECT '','CLASS1','9A02','C#',100
UNION
SELECT '','CLASS2','9B01','C#',100
UNION
SELECT '','CLASS2','9B02','C#',100
UNION
SELECT '','CLASS1','8A01','JAVA',100
UNION
SELECT '','CLASS1','8A02','JAVA',100
UNION
SELECT '','CLASS2','8B01','JAVA',100
UNION
SELECT '','CLASS2','8B02','JAVA',100
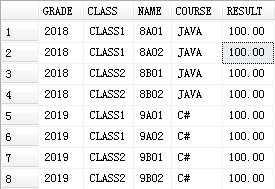
查询T0表结果:
3、GROUP BY
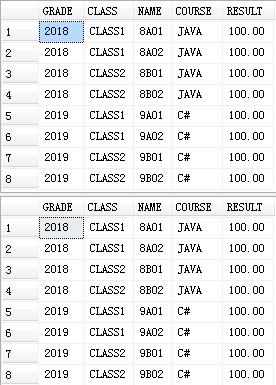
抛砖引玉,看看常用的GROUP BY排序:默认以SELECT字段顺序(GRADE->CLASS->NAME->COURSE)进行排序,以下两种查询结果是一样的。
SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE
ORDER BY GRADE,CLASS,NAME,COURSE
4、WITH CUBE
原理1:以GROUP BY字段依次赋以NULL值进行分组聚合。
原理2:第1个字段(即GRADE字段)生成结果:除原始数据外,以第1个字段固定赋以NULL值,然后其它字段依次赋以NULL值进行分组聚合,结果由右往左进行排序。
下面开始测第1个字段的结果是怎么来的:
INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT 'ZZ' GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY CLASS,NAME,COURSE INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT 'ZZ' GRADE,'ZZ' CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY NAME,COURSE INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT 'ZZ' GRADE,'ZZ' CLASS,'ZZ' NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY COURSE INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT 'ZZ' GRADE,'ZZ' CLASS,'ZZ' NAME,'ZZ' COURSE,SUM(RESULT) RESULT
FROM #T0 --第1个字段结果排序由右往左
INSERT INTO #T2 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,CLASS,NAME,COURSE,RESULT FROM #T1 WHERE ID BETWEEN 1 AND 27 ORDER BY COURSE,NAME,CLASS,GRADE UPDATE #T2 SET GRADE=NULL WHERE GRADE='ZZ'
UPDATE #T2 SET CLASS=NULL WHERE CLASS='ZZ'
UPDATE #T2 SET NAME=NULL WHERE NAME='ZZ'
UPDATE #T2 SET COURSE=NULL WHERE COURSE='ZZ'
WITH CUBE的结果:
SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE
WITH CUBE

自已测试的结果:
SELECT * FROM #T2
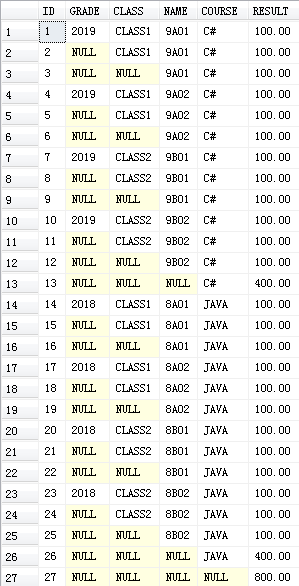
结果与上面一致。
其它字段优先跟哪个字段组合、最终怎样排序?呃,测过,没搞清楚……
5、WITH ROLLUP
原理1:除原始数据外,以GROUP BY最后1个字段(即COURSE字段)固定赋以NULL值,然后其它字段依次赋以NULL值进行分组聚合,结果由左往右进行排序。
这个跟WITH CUBE的第1个字段非常相象:一个是第1个字段,一个是最后1个字段;一个结果是由右往左排序,一个结果是由左往右排序。
下面开始测结果是怎么来的:
TRUNCATE TABLE #T1
TRUNCATE TABLE #T2 INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,CLASS,NAME,'ZZ' COURSE,SUM(RESULT) RESULT
FROM #T0
WHERE NOT EXISTS (SELECT 1 FROM #T1 WHERE GRADE=#T0.GRADE AND CLASS=#T0.GRADE AND NAME=#T0.NAME AND COURSE='ZZ')
GROUP BY GRADE,CLASS,NAME INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,CLASS,'ZZ' NAME,'ZZ' COURSE,SUM(RESULT) RESULT
FROM #T0
WHERE NOT EXISTS (SELECT 1 FROM #T1 WHERE GRADE=#T0.GRADE AND CLASS=#T0.CLASS AND NAME='ZZ' AND COURSE='ZZ')
GROUP BY GRADE,CLASS INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,'ZZ' CLASS,'ZZ' NAME,'ZZ' COURSE,SUM(RESULT) RESULT
FROM #T0
WHERE NOT EXISTS (SELECT 1 FROM #T1 WHERE GRADE=#T0.GRADE AND CLASS='ZZ' AND NAME='ZZ' AND COURSE='ZZ')
GROUP BY GRADE INSERT INTO #T1 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT 'ZZ' GRADE,'ZZ' CLASS,'ZZ' NAME,'ZZ' COURSE,SUM(RESULT) RESULT
FROM #T0 --结果排序由左往右
INSERT INTO #T2 (GRADE,CLASS,NAME,COURSE,RESULT)
SELECT GRADE,CLASS,NAME,COURSE,RESULT FROM #T1 ORDER BY GRADE,CLASS,NAME,COURSE UPDATE #T2 SET GRADE=NULL WHERE GRADE='ZZ'
UPDATE #T2 SET CLASS=NULL WHERE CLASS='ZZ'
UPDATE #T2 SET NAME=NULL WHERE NAME='ZZ'
UPDATE #T2 SET COURSE=NULL WHERE COURSE='ZZ'
WITH ROLLUP的结果:
SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE
WITH ROLLUP
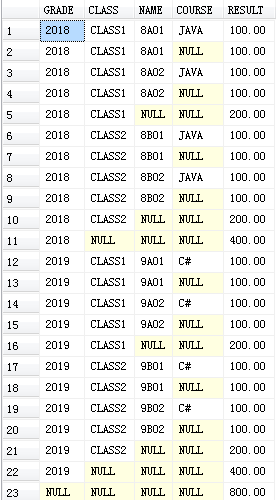
自己测试的结果:
SELECT * FROM #T2

结果与上面一致。
6、GROUPING
这个就比较容易理解了,WITH CUBE与WITH ROLLUP用法一样,先看结果:
SELECT GRADE,CLASS,NAME,COURSE,SUM(RESULT) RESULT,GROUPING(COURSE) [GROUPING]
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE
WITH ROLLUP
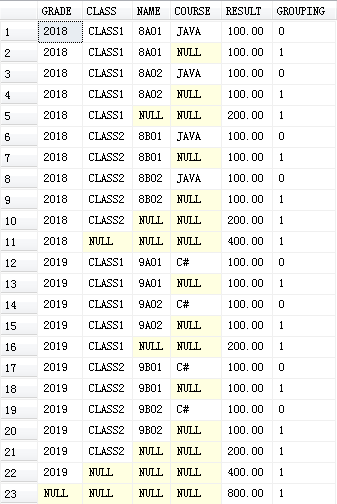
上面GROUPING的是COURSE字段,有NULL值就是WITH ROLLUP额外添加的,GROUPING结果值为1。
有了GROUPING,那做小计、总计就方便了。
SELECT
GRADE,
CASE WHEN GROUPING(GRADE)=1 AND GROUPING(CLASS)=1 THEN '总计' WHEN GROUPING(GRADE)=0 AND GROUPING(CLASS)=1 THEN '小计' ELSE CLASS END CLASS,
NAME,COURSE,SUM(RESULT) RESULT
FROM #T0
GROUP BY GRADE,CLASS,NAME,COURSE
WITH ROLLUP

好了,原理测试及应用就到这里结束了。
GROUP BY中的WITH CUBE、WITH ROLLUP原理测试及GROUPING应用的更多相关文章
- CUBE,ROLLUP 和 GROUPING
1.用 CUBE 汇总数据 CUBE 运算符生成的结果集是多维数据集.多维数据集是事实数据的扩展,事实数据即记录个别事件的数据.扩展建立在用户打算分析的列上.这些列被称为维.多维数据集是一个结果集,其 ...
- oracle group by中cube和rollup字句的使用方法及区别
oracle group by中rollup和cube的区别: Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句. 如果是ROLLUP(A, B, C)的话,先 ...
- GROUP BY中ROLLUP/CUBE/GROUPING/GROUPING SETS使用示例
oracle group by中rollup和cube的区别: Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句.CUBE ROLLUP 是用于统计数据的. 实验 ...
- 【SQL】面面俱到 | 在SQL中使用CUBE和ROLLUP实现数据多维汇总
偶然在网上看到一篇文章,讲到数据汇总,提到了CUBE,感觉有些晦涩,想试着自己表述一下.同时,个人也认为CUBE还是很有用的,对SQL或数据分析感兴趣的小伙伴不妨了解一下,或许有用呢! 先设定个需求, ...
- GROUP BY你都不会!ROLLUP,CUBE,GROUPPING详解
Group By Group By 谁不会啊?这不是最简单的吗?越是简单的东西,我们越会忽略掉他,因为我们不愿意再去深入了解它. 1 小时 SQL 极速入门(一) 1 小时 SQL 极速入门(二) 1 ...
- Oracle的聚合函数group by结合CUBE和ROLLUP的使用
转自:https://docs.oracle.com/cd/E11882_01/server.112/e25554/aggreg.htm#DWHSG8618 CUBE Syntax CUBE appe ...
- 【转】rollup、cub、grouping sets、grouping、grouping_id在报表中的应用
摘自 http://blog.itpub.net/26977915/viewspace-734114/ 在报表语句中经常要使用各种分组汇总,rollup和cube就是常用的分组汇总方式. 第一:gro ...
- [SQL]详解CUBE和ROLLUP区别<使用rollup或cube通过交叉列可产生高级汇总结果集>
要使用CUBE,首先要了解GROUP BY. 其实CUBE和ROLLUP区别不太大,只是在基于GROUP BY 子句创建和汇总分组的可能的组合上有一定差别,CUBE将返回的更多的可能组合.如果在GRO ...
- GROUPING SETS、CUBE、ROLLUP
其实还是写一个Demo 比较好 USE tempdb IF OBJECT_ID( 'dbo.T1' , 'U' )IS NOT NULL BEGIN DROP TABLE dbo.T1; END; G ...
随机推荐
- 《Java基础知识》序列化与反序列化详解
序列化的作用:为了不同jvm之间共享实例对象的一种解决方案.由java提供此机制. 序列化应用场景: 1. 分布式传递对象. 2. 网络传递对象. 3. tomcat关闭以后会把session对象序列 ...
- [ASP.NET Core 3框架揭秘] 配置[6]:多样化的配置源[上篇]
.NET Core采用的这个全新的配置模型的一个主要的特点就是对多种不同配置源的支持.我们可以将内存变量.命令行参数.环境变量和物理文件作为原始配置数据的来源.如果采用物理文件作为配置源,我们可以选择 ...
- C#中怎样获取默认配置文件App.config中配置的键值对内容
场景 在新建一个程序后,项目中会有一个默认配置文件App.config 一般会将一些配置文件信息,比如连接数据库的字符串等信息存在此配置文件中. 怎样在代码中获取自己配置的键值对信息. 注: 博客主页 ...
- Gradle 自定义插件
使用版本 5.6.2 插件被用来封装构建逻辑和一些通用配置.将可重复使用的构建逻辑和默认约定封装到插件里,以便于其他项目使用. 你可以使用你喜欢的语言开发插件,但是最终是要编译成字节码在 JVM 运行 ...
- ShowDoc速记
编写文档好工具showdoc部署 参考:https://www.showdoc.cc/ 一定要看,一定要用卷,丢失数据的痛苦,痛何如哉. https://www.cnblogs.com/harrych ...
- Csharp: TreeList Drag and Drop
/// <summary> /// https://www.codeproject.com/articles/3225/treelistview /// https://www.codep ...
- ORACLE数据库中执行计划出现INTERNAL_FUNCTION一定是隐式转换吗?
ORACLE数据库中,我们会使用一些SQL语句找出存在隐式转换的问题SQL,其中网上流传的一个SQL语句如下,查询V$SQL_PLAN的字段FILTER_PREDICATES中是否存在INTERNAL ...
- PWM是如何调节直流电机转速的?电机正反转的原理又是怎样的?
电机是重要的执行机构,可以将电转转化为机械能,从而驱动北控设备的转动或者移动,在我们的生活中应用非常广泛.例如,应用在电动工具.电动平衡车.电动园林工具.儿童玩具中.直流电机的实物图如下图所示. 1- ...
- windows 安装xps查看器; windows 10 安装 xps viewer
最近发现windows 默认是没有xps 查看器的,需要自己手动添加: 安装完成后,即可使用: 参考链接:https://www.windowscentral.com/how-get-xps-view ...
- Go学习笔记(持续更中,参考go编程基础,go边看边练)
使用关键字 var 定义变量,自动初始化为零值.如果提供初始化值,可省略变量类型. 在函数内部,可用更简略的 := 方式定义变量.空白符号_ package main import "fmt ...