SpringCloud之整合Zipkin+Sleuth(十四)
Zipkin的概述
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以
解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。 我们可以使用它来收集各个服务
器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助我们查询跟踪数据以实现对分布式系
统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发
的 API 接口之外,它也提供了方便的 UI 组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比
如:可以查询某段时间内各用户请求的处理时间等。 Zipkin 提供了可插拔数据存储方式:In-
Memory、MySql、Cassandra 以及 Elasticsearch。
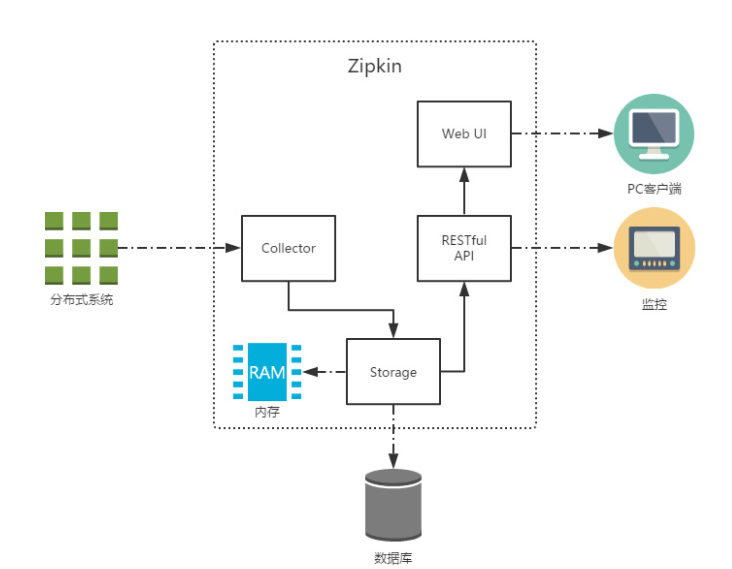
上图展示了 Zipkin 的基础架构,它主要由 4 个核心组件构成:
Collector :收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为
Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
Storage :存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,
我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
RESTful API :API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接
系统访问以实现监控等。
Web UI :UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和
分析跟踪信息。
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用。
客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的
监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。
发送的方式主要有两种,一种是 HTTP 报文的方式,还有一种是消息总线的方式如 RabbitMQ。
不论哪种方式,我们都需要:
一个 Eureka 服务注册中心,这里我们就用之前的 eureka 项目来当注册中心。
一个 Zipkin 服务端。
多个微服务,这些微服务中配置 Zipkin 客户端。
1.添加依赖
在项目的pom.xml文件中添加下面依赖
<!--里面包含两个依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2. 修改配置
主要修改两个配置:
base-url:zipkin地址,默认值是:"http://192.168.180.113:9411/"probability: 采集日志的百分比,默认值是:0.1,由于测试中需要才改成1,生产环境就使用默认值
#zipkin服务所在地址
zipkin:
base-url: http://192.168.180.113:9411/
#配置采样百分比,开发环境可以设置为1,表示全部,生产就用默认
sleuth:
sampler:
probability: 1
3. 开启Zipkin
docker中有现成的镜像直接拉去下来使用
拉去镜像 docker pull docker.io/openzipkin/zipkin
启动容器 [root@topcheer ~]# docker run -d -p 9411:9411 --name myzipkin 17c2bb09f482
5a1707edb7a6c57887537577f7e5775b3f5313fe6b5f703f71b453763d61a506
[root@topcheer ~]# docker ps -l
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5a1707edb7a6 17c2bb09f482 "/busybox/sh run.sh" 6 seconds ago Up 4 seconds 9410-9411/tcp myzipkin
[root@topcheer ~]#
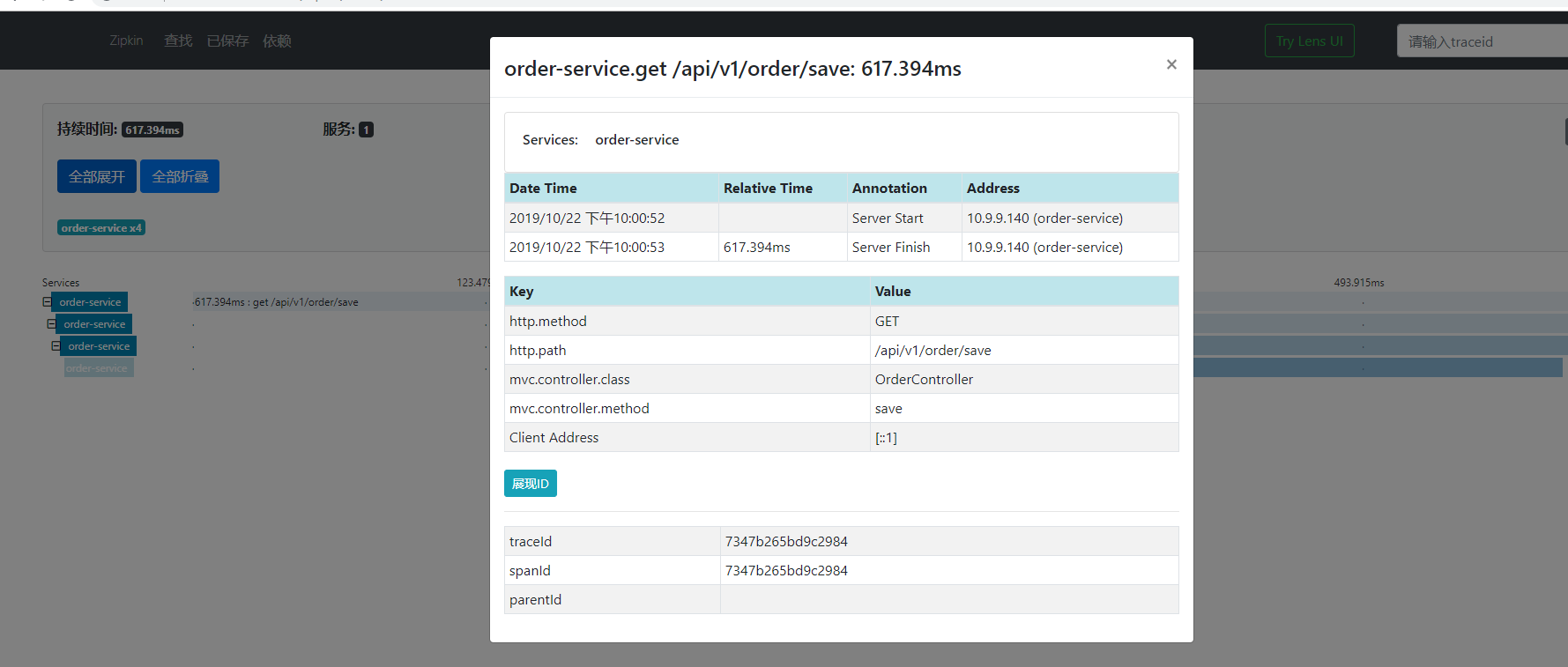

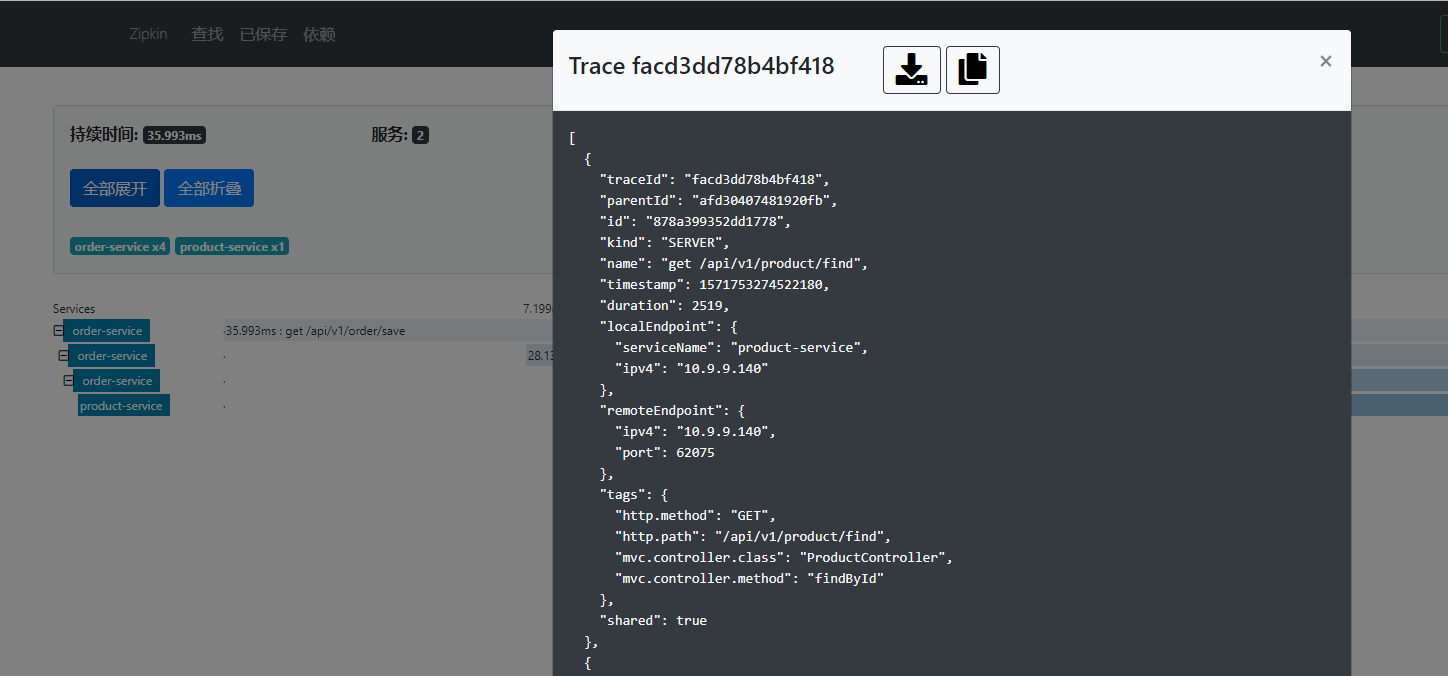
SpringCloud之整合Zipkin+Sleuth(十四)的更多相关文章
- Spring Cloud Sleuth(十四)
作用 再微服务中 服务调用服务很常见.服务中相互调用链路追踪的尤为重要,能够帮助我们再异常时分析出哪个服务出了异常.以及各个链路中相互调用所消耗时间,通过这些数据能够帮助我们分析出各个服务的性能瓶颈 ...
- 新版本SpringCloud sleuth整合zipkin
SpringCloud Sleuth 简介 Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案. Spring Cloud Sleuth借鉴了Dapper的术语. ...
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- Spring Boot(十四):spring boot整合shiro-登录认证和权限管理
Spring Boot(十四):spring boot整合shiro-登录认证和权限管理 使用Spring Boot集成Apache Shiro.安全应该是互联网公司的一道生命线,几乎任何的公司都会涉 ...
- 如约而至,Java 10 正式发布! Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十四)Redis缓存正确的使用姿势 努力的孩子运气不会太差,跌宕的人生定当更加精彩 优先队列详解(转载)
如约而至,Java 10 正式发布! 3 月 20 日,Oracle 宣布 Java 10 正式发布. 官方已提供下载:http://www.oracle.com/technetwork/java ...
- springcloud(十四):搭建Zuul微服务网关
springcloud(十四):搭建Zuul微服务网关 1. 2. 3. 4.
- springboot(十四):springboot整合shiro-登录认证和权限管理(转)
springboot(十四):springboot整合shiro-登录认证和权限管理 .embody{ padding:10px 10px 10px; margin:0 -20px; border-b ...
- 跟我学SpringCloud | 第十四篇:Spring Cloud Gateway高级应用
SpringCloud系列教程 | 第十四篇:Spring Cloud Gateway高级应用 Springboot: 2.1.6.RELEASE SpringCloud: Greenwich.SR1 ...
- spring-boot-route(十四)整合Kafka
在上一章中SpringBoot整合RabbitMQ,已经详细介绍了消息队列的作用,这一种我们直接来学习SpringBoot如何整合kafka发送消息. kafka简介 kafka是用Scala和Jav ...
随机推荐
- Springboot2.1.x配置Activiti7单独数据源问题
Springboot2.1.x配置Activiti7单独数据源问题 简介 最近基于最新的Activiti7配置了SpringBoot2. 简单上手使用了一番.发现市面上解决Activiti7的教程很少 ...
- asp.netcore 3.0 Docker Nginx(震惊,原来docker是这样的!)
引言 Docker发布于2013年,Docker是dotCloud公司创始人在法国期间发起的一个公司内部项目,他是dotCloud多年云技术的一个革新.Docker在容器基础上进行了一步的封装,从网络 ...
- Spring 梳理-Spring配置文件 -<context:annotation-config/>和<context:component-scan base-package=""/>和<mvc:annotation-driven /> 的区别
<context:annotation-config/> 在基于主机方式配置Spring时,Spring配置文件applicationContext.xml,你可能会见<contex ...
- shiro使用注解(@RequiresPermissions等)不无效及异常处理
1.注解不生效 在shiro配置类中加上如下代码: /** * Shiro生命周期处理器 */ @Bean(name = "lifecycleBeanPostProcessor") ...
- KD-tree学习笔记(超全!)
目录 K-D树 更新信息 建树 插入 查询 k远/近询问 重构 K-D 树优化建边 后记 因为之前找不到全的博客,唯一的一篇码风比较毒瘤... 所以我就来写了 K-D树 大概是高维二叉树吧 每次按一个 ...
- Timed out after 30000 ms while waiting to connect
今天使用mongo-java-drive写连接mongo的客户端,着实被上面那个错坑了一把.回顾一下解决过程: 报错: com.mongodb.MongoTimeoutException: Timed ...
- 最简单的JS实现json转csv
工作久了,总会遇到各种各样的数据处理工作,比如同步数据,初始化一些数据,目前比较流行的交互数据格式就是JSON,可是服务器中得到的JSON数据如果提供给业务人员看的话可能会非常不方便,这时候,转成CS ...
- css3——box-sizing属性
很多朋友们可能会疑惑,不知道box-sizing属性是有什么作用,自己也很少会用到,但是想必不少人在做网页布局的时候经常遇到一个问题就是我明明设置了父元素设置了假如是宽高500px,5个子元素左浮动设 ...
- python编程基础之十一
循环语句:周而复始,在满足某个条件下,重复做相同或类型的事情, 循环语句三要素:循环条件 + 循环体 + 循环条件改变while 条件 : 循环体 循环条件改变... while 条件 : 循环体 循 ...
- NOIP2011计算系数;
#include<cmath> #include<algorithm> #include<stdio.h> #include<iostream> #de ...