scrapy实验1 爬取中国人寿官网新闻,保存为xml
一、scrapy 实验 爬中国人寿新闻,保存为xml
如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10517297.html
链接:https://pan.baidu.com/s/1HeIbBuAWjk8uNRl7ZIXh-A
提取码:z3hh
1.1 代码结构
scrapy框架具体内容,请参考
1、scrapy(一)scrapy 安装问题 https://www.cnblogs.com/xxtalhr/p/9170437.html
2、Scrapy 框架(二)数据的持久化 https://www.cnblogs.com/xxtalhr/p/9164186.html
3、scrapy (三)各部分意义及框架示意图详解 https://www.cnblogs.com/xxtalhr/p/9170343.html
4、scrapy (四)基本配置 https://www.cnblogs.com/xxtalhr/p/9169484.html
5、scrapy shell https://www.cnblogs.com/xxtalhr/p/9158651.html

1.2 书写 spiders
# -*- coding: utf-8 -*-
import scrapy
import json class RrSpider(scrapy.Spider):
name = 'rr'
allowed_domains = ['www.chinalife.com.cn']
start_urls = ['https://www.chinalife.com.cn/chinalife/xwzx/gsxw/7934bcc5-%d.html' % (i) for i in range(1, 12)] def parse(self, response):
news = response.xpath('//div[@class="easysite-article-content"]/ul/li')
print('========================================', len(news))
items = []
fp = open('./xml-4.xml', 'a', encoding='utf-8')#打开文件,不用手动创建
for new in news:
new_date = new.xpath('./span/text()').extract()[0]
new_title = new.xpath('.//div/span/a/@title').extract_first()
new_info = new.xpath('.//div/a/span/text()').extract_first()
new_link = 'https://www.chinalife.com.cn/' + new.xpath('.//div/span/a/@href').extract_first()
item = {}
item['date'] = new_date
item['title'] = new_title
item['info'] = new_info
item['link'] = new_link fp.write(json.dumps(item))#写入文件 items.append(item)
print('+++++++++++++++++++++++++++++++', new_date, new_info, new_link, new_title,)
fp.close()
return items
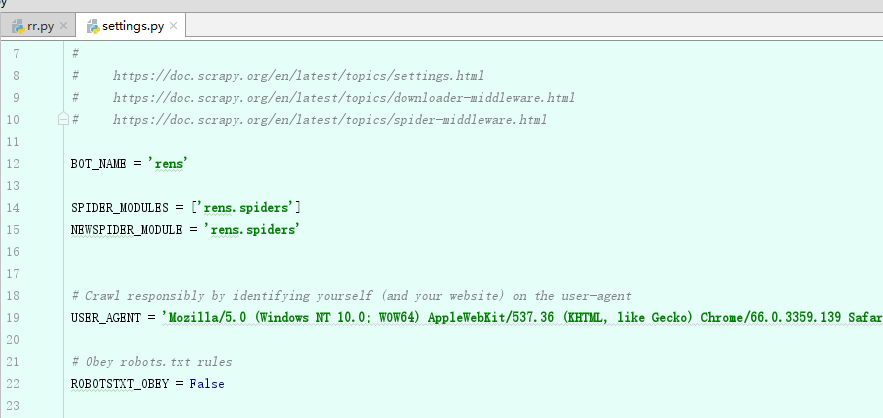
二、修改 setting中 USER_AGENT 和 ROBOTSTXT_OBEY
三、 终端 执行命令
scrapy crawl rr -o renshou.xml
# ('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')

欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加作者微信:tinghai87605025 或 QQ :87605025
python QQ交流群:py_data 483766429
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事多做几遍。。。。。。

scrapy实验1 爬取中国人寿官网新闻,保存为xml的更多相关文章
- 爬虫之爬取斗鱼官网LOL部分主播的状态
一个爬虫小程序 爬取主播的排名及观看人数 import re import requests import request class Spider(): url = 'https://www.dou ...
- 实战爬取Plati官网游戏实时最低价格-Python
需要修改url中的id_r="这个",这个id需要从Battlefield V (plati.ru)中获取,其实也是这个链接中的#s24235. 配合了e-mail推送,其实这个e ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- 使用 Scrapy 爬取去哪儿网景区信息
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘.监测和自动化测试.安装使用终端命令 pip install Scrapy ...
- 爬取西刺网的免费IP
在写爬虫时,经常需要切换IP,所以很有必要自已在数据维护库中维护一个IP池,这样,就可以在需用的时候随机切换IP,我的方法是爬取西刺网的免费IP,存入数据库中,然后在scrapy 工程中加入tools ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
随机推荐
- Perl爬虫的简单实现
由于工作中有个项目需要爬取第三方网站的内容,所以在Linux下使用Perl写了个简单的爬虫. 相关工具 1. HttpWatch/浏览器开发人员工具 一般情况下这个工具是用不到的,但是如果你发现要爬取 ...
- 初学CSS-3-文字的属性
文字样式属性: 格式:font-style:italic;/normal; 快捷键:fsi / fsn + tab键 文字粗细属性: 格式:font-weight:bold;/bolder;/ligh ...
- React中使用百度地图API
今天我们来搞一搞如何在React中使用百度地图API好吧,最近忙的头皮发麻,感觉身体被掏空,所以很久都没来写博客了,但今天我一定要来一篇好吧 话不多说,我们直接开始好吧 特别注意:该React项目是用 ...
- 【读书笔记】iOS-强类型与弱类型
id类型是一个通用类型,OC使用id表示任意类型的对象,它可以作为一个占位符表示这是一个不确定的类型的对象或者引用.因此,所有的对象都 可以用id来表示.这很有用,想象一下,如果你需要实现一个通用的链 ...
- 【读书笔记】iOS-Objective-C编程
Objective-C中的类可以继承自任何一个顶级类,需要注意的是,虽然NSObject是最常见的顶级类,但是它并不是唯一的顶级类,例如,NSProxy就是和NSObject一样的顶级类,所以你不能说 ...
- 测试思想 QA的价值体现
QA的价值体现 by:授客 QQ:1033553122 1. 缺陷挖掘价值 QA人员一个很重要的价值就是在尽可能短的时间内找出尽可能多的缺陷. 某种意义上说,缺陷直观的反应了产品的质量,QA发现的有 ...
- Java并发编程(十)阻塞队列
使用非阻塞队列的时候有一个很大问题就是:它不会对当前线程产生阻塞,那么在面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦.但是有了阻塞队列就不一样了, ...
- JavaWeb:jsp
本文内容: JSP的介绍 jsp的使用 EL表达式 JSTL的使用 首发日期:2018-06-18 JSP的介绍: JSP全称Java Server Pages. 与静态网页格式的html不同的是,j ...
- mysql 的一些事
给mysql的root用户设置密码 1.刚安装好的mysql是没有设置密码的 2.设置密码 ****************************************************** ...
- mac上Android环境变量配置
1.AndroidSDK路径查看 (1)AndroidStudio: 菜单栏AndroidStudio > Preferences > Appearences&Behavior & ...