《Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks》论文阅读
《Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks》论文阅读
(i)问题背景:
工业界的推荐系统/广告系统现在都会用embedding技术生成物品/用户的向量。通俗点讲就是build一个向量嵌入层,把带有原始特征的输入向量转换成一个低维度的dense向量表示。推荐系统的模型一般有向量嵌入层和深度模型层两部分组成,向量嵌入层的输出或作为深度学习模型的输入。因此embedding过程的好坏会影响后面深度学习模型的学习和预测效果。物品的ID的向量表示称为ID embedding。每个物品都有一个独特的ID,因此ID embedding也是物品独一无二的向量表示。所以学习到一个好的ID embedding对于提升整个系统的效果是非常关键的。
但是embedding技术是海量数据驱动的模型,数据量越大,学习到的向量表示效果才越好。并且学ID embedding的时候还会遇到冷启动的问题,冷启动的意思就是说一个新的物品进来,系统里没有关于它的历史信息,对它了解很少,因此是个比较新的未知数据。并且它和环境交互的数据也很少,在冷启动的情况下,现有的embedding技术要表示这种类型的物品ID embedding效果就会不好(这个时候学到的embedding叫Cold ID embedding),所以要想办法解决这个问题。
分析问题:
|
Cold ID embedding面临的问题 |
解决的方案 |
|
在deep model和cold ID embedding 之间存在一个gap。这里gap的意思接近于bias。和“二八定律”有点类似,少量的热门物品因为点击关注率很高,往往占据了整个训练数据集的大部分数据样本。因此模型学习embedding 向量的时候,会对热门物品的学习效果好,能学到很多热门物品的知识,但冷启动的物品因为缺乏足够量的data,训练出来的向量就会效果不好。 |
1.提出MWUF(Meta Warm Up Framework)网络去warm up cold ID embedding,其实本质上就是做个映射,把cold start embedding 映射到warm up空间里. MWUF框架包含一种公共初始化ID embedding以及两个meta networks。对于任何新来的物品,我们使用现有的物品embedding的均值来作为初始化。另外,Meta Scaling Network使用物品的特征作为输入,生成一个定制化的拉伸函数将冷启动ID embedding转化为warmer embedding。 |
|
Cold ID embedding 会被噪音的interaction数据影响。Cold ID embedding本来就缺乏足够的数据量来训练和学习,如果这个时候用户有一些错误的点击,即使是很小的噪声,也会对整个embedding的学习造成很严重的影响,bias会比较大。 |
Meta Shifting Network使用全局的交互过的用户作为输入,来生成一个偏移函数,来加强物品表示。 |
(ii)具体的算法流程和思路:
1.MWUF架构主要做的两点工作
第一个改变了初始化ID embedding的方法,原来对于新物品,都是采用随机初始化(randomly initialize),现在改为由MWUF初始化ID embedding。其实这个方法的本质就是采用元学习(meta learning)的思想,通过公共初始化ID embedding来生成common initial ID embedding。元学习的思想和迁移学习有点类似,就是通过把模型对已知任务的训练学到的经验和知识能在新任务上应用。在本文里面,就是通过对所有现有已知物品学习到的通识(common knowledge)应用于新物品的ID embedding初始化。啊再说的low一点,它就是把现有所有物品学到的ID embedding做个算数平均值作为新物品的初始化ID embedding。其实吹了这么多····· 什么元学习,高大上,冷启动,warm up,common knowledge,就是把随机赋值变成算个算数平均数再赋值而已··
第二个就是训练了两个meta network(Meta Shifting Network , Meta Scaling)并且加入了拉伸函数(Scaling Function)。本质上就是训练了一个映射函数,然后把Cold ID embedding 映射成一个新的 ID embedding,他把这个叫做warmer embedding,咋一看很高大上,其实就是训练了一个映射函数罢了··,相当于再加了一层预处理或者说数学变换。
2.模型框架
话不多说,上图:
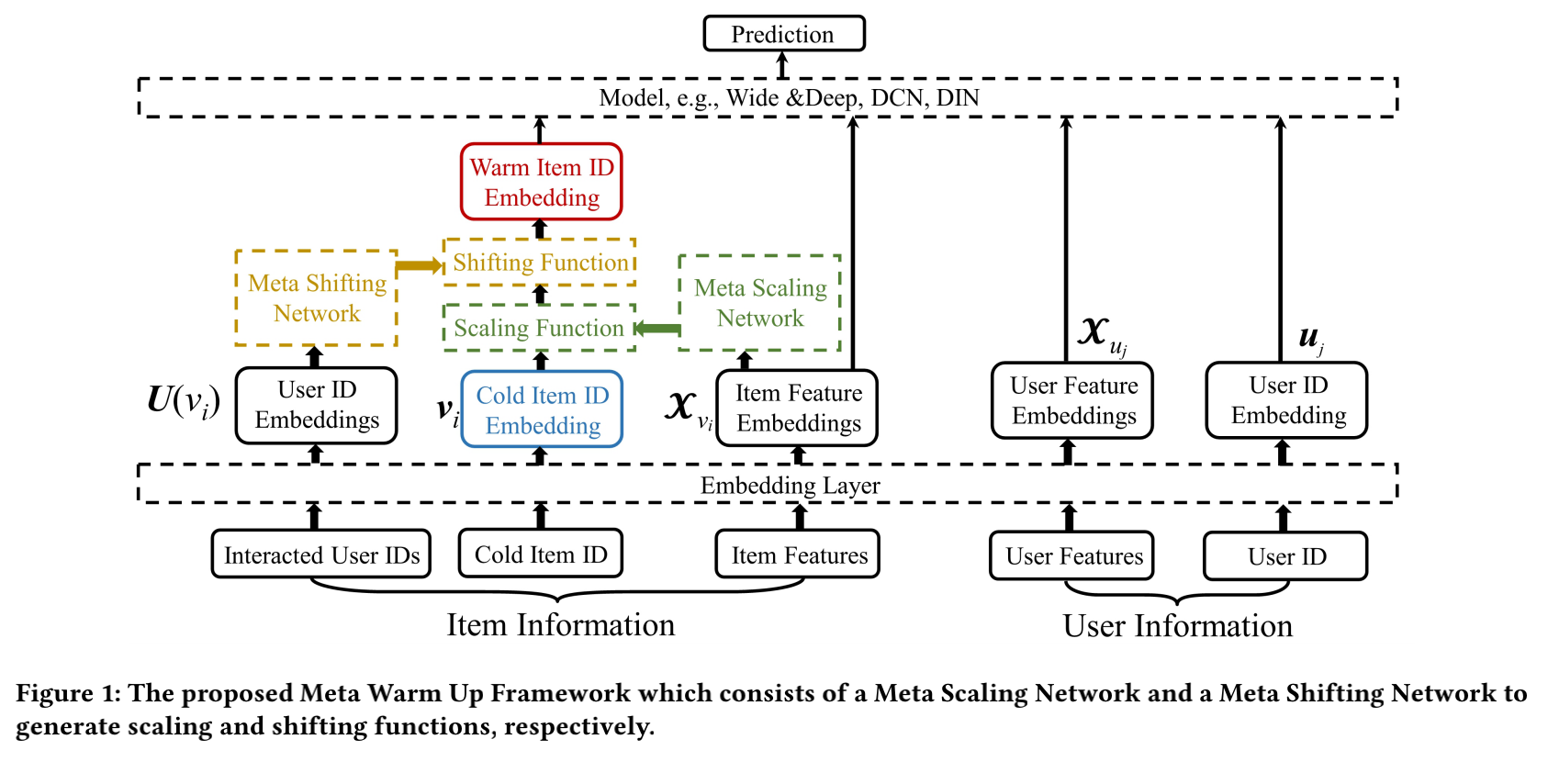
整体框架如上所示,深度模型的输入包含4个部分,物品ID embedding,物品其他特征embedding,用户ID embedding,用户其他特征embedding:
Common Initial Embeddings: 提出了一种公共初始化embedding,使用现有的所有物品的ID embedding均值作为新加入的物品的初始化embedding。
Meta Scaling Network:希望将冷启动物品ID embedding转换到一个更好的特征空间,能更好地拟合深度模型。对于每一个物品,冷启动ID embedding和warm ID embedding之间存在一定的联系,认为相似的物品,这个联系也应该相似,因此Meta Scaling Network以物品的其他特征做为输入,输出一个拉伸函数:
Meta Shifting Network: 所有交互过的用户均值可以有效的减轻异常用户的影响,因此Meta Shifting Network以交互过的用户的均值表示作为输入,输出一个偏移函数
3.算法流程:

这里假设是一个推荐系统的二分类问题,比如CTR预估。每个样本包括一个user,一个item和一个对应的label(0或者1).
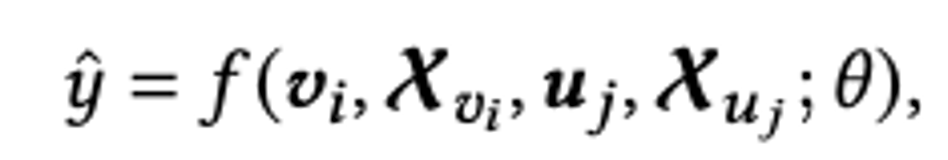
第i个物品的Item ID embedding 就是。各种item的feature做embedding 就是。同理可得第j个用户的User ID embedding为。各种user的feature做embedding为 。y是模型预测的结果。θ是整个模型网络的参数集合。损失函数采用对数损失的形式,为:
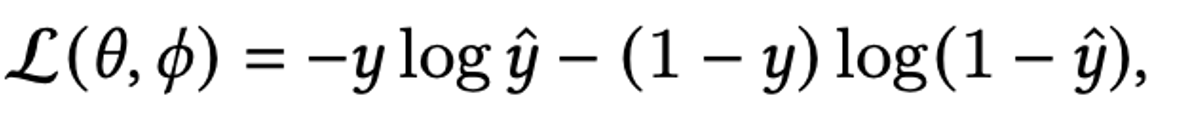
Φ 为embedding层的参数集合。
Overall Procedure:
整个算法流程分两步走,第一步先用已有的数据进行线上训练,学习整个模型的参数集合和。第二步固定参数和迭代采样训练两个meta network。生成Shift function和Scaling Function来解决gap和噪音的问题。
其实整个模型主要就是解决冷启动里面gap的问题,之后可能会魔改我们现有的model,引入本文的idea,看能不能改善线上模型的gap问题。如果之后确实用到,会接下来会把相关的coding部分也贴出来。
《Learning to warm up cold Item Embeddings for Cold-start Recommendation with Meta Scaling and Shifting Networks》论文阅读的更多相关文章
- 《Deep Learning of Graph Matching》论文阅读
1. 论文概述 论文首次将深度学习同图匹配(Graph matching)结合,设计了end-to-end网络去学习图匹配过程. 1.1 网络学习的目标(输出) 是两个图(Graph)之间的相似度矩阵 ...
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- Deep Learning 33:读论文“Densely Connected Convolutional Networks”-------DenseNet 简单理解
一.读前说明 1.论文"Densely Connected Convolutional Networks"是现在为止效果最好的CNN架构,比Resnet还好,有必要学习一下它为什么 ...
- Deep Learning 26:读论文“Maxout Networks”——ICML 2013
论文Maxout Networks实际上非常简单,只是发现一种新的激活函数(叫maxout)而已,跟relu有点类似,relu使用的max(x,0)是对每个通道的特征图的每一个单元执行的与0比较最大化 ...
- Discriminative Learning of Deep Convolutional Feature Point Descriptors 论文阅读笔记
介绍 该文提出一种基于深度学习的特征描述方法,并且对尺度变化.图像旋转.透射变换.非刚性变形.光照变化等具有很好的鲁棒性.该算法的整体思想并不复杂,使用孪生网络从图块中提取特征信息(得到一个128维的 ...
- Sequence to Sequence Learning with Neural Networks论文阅读
论文下载 作者(三位Google大佬)一开始提出DNN的缺点,DNN不能用于将序列映射到序列.此论文以机器翻译为例,核心模型是长短期记忆神经网络(LSTM),首先通过一个多层的LSTM将输入的语言序列 ...
- Deep Learning 24:读论文“Batch-normalized Maxout Network in Network”——mnist错误率为0.24%
读本篇论文“Batch-normalized Maxout Network in Network”的原因在它的mnist错误率为0.24%,世界排名第4.并且代码是用matlab写的,本人还没装caf ...
- Deep Learning 25:读论文“Network in Network”——ICLR 2014
论文Network in network (ICLR 2014)是对传统CNN的改进,传统的CNN就交替的卷积层和池化层的叠加,其中卷积层就是把上一层的输出与卷积核(即滤波器)卷积,是线性变换,然后再 ...
- Deep Learning 28:读论文“Multi Column Deep Neural Network for Traffic Sign Classification”-------MCDNN 简单理解
读这篇论文“ Multi Column Deep Neural Network for Traffic Sign Classification”是为了更加理解,论文“Multi-column Deep ...
随机推荐
- spring boot pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- windows 7系统封装总结
win7系统封装总结 需求:对于个人家庭用户,网上下载原版镜像或者下载好别人封装好的系统都无所谓,但是在公司办公的特殊环境下, 有时需要经常装一些特殊的软件,根据实际情况,封装一个适合本公司使用环境的 ...
- 读HikariCP源码学Java(一)-- 通过ConcurrentBag类学习并发编程思想
前言 ConcurrentBag是HikariCP中实现的一个池化资源的并发管理类.它是一个高性能的生产者-消费者队列. ConcurrentBag的并发性能优于LinkedBlockingQueue ...
- 华为eNSP模拟器— telnet实验
华为eNSP模拟器-telnet实验 一.实验一 路由交换之间实现telnet登陆 实验拓扑 实验目的: 路由器作为 telnet 服务器 交换机作为客户端去连接路由器 实验步骤: 路由器配置 < ...
- Linux学习之路-Linux-at及cron命令【7】---20171215
Linux学习之路-Linux-at及cron命令[7]---20171215 DannyExia000人评论986人阅读2017-12-24 17:28:03 ntpdate 命令 [root@ ...
- SSH自动断开连接的原因-20200323
SSH自动断开连接的原因 方法一: 用putty/SecureCRT连续3分钟左右没有输入, 就自动断开, 然后必须重新登陆, 很麻烦. 在网上查了很多资料, 发现原因有多种, 环境变量TMOUT ...
- 049.Python前端javascript
一 JavaScript概述 1.1 JavaScript的历史 1992年Nombas开发出C-minus-minus(C--)的嵌入式脚本语言(最初绑定在CEnvi软件中).后将其改名Script ...
- win10家庭版升级 到win10企业版
成功升级3小时 20200124 拿到电脑 win10家庭版 不会用 找admin都找不到只能用企业版 升级win10家庭版 到win10企业版 在msdn下载win10企业版iso iso 文件管 ...
- Python判断身份证是否合法
利用正则表达式实现对身份证合法程度的判断 1 # !usr/bin/env python3 2 # coding:utf-8 3 """ 4 @ Copyright (c ...
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...