PGSQL存储过程学习
一、存储过程定义:
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。在数据量特别庞大的情况下利用存储过程能达到倍速的效率提升。
二、存储过程的结构
案例: 创建一个求长方形面积的存储过程。
create or replace function area_of_rectangle(lenth integer,height integer) --存储过程名称与参数【参数格式:(变量名1 变量类型 , 变量名2 变量类型,…)
returns integer as --有“s”
$$
declare --declare表示声明变量,可以声明多个变量
area integer := 0; --定义面积变量数据类型
begin
area := lenth * height; --主逻辑与返回值
return area; --返回值
end $$ language 'plpgsql';
注意:两个 $$ 符中间可以填入符合命名规则的任意字符,如$body$、$aaaa$。但是下方的美元符必须与这里的保持一致。
调用存储过程:
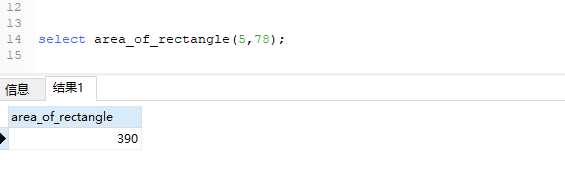
二、变量使用
1.变量类型:存储过程中,对变量赋值需要两个值类型一致;

注意:record类型变量是“记录类型”的变量,用于存储多行多列的值。
按官方文档的说明,record类型的变量并不是真正的变量,该类型变量在第一次赋值前,它有多少列、每一列是什么类型都是不确定的。在第一次赋值后,该变量就根据值自动确定列的数量和各列的类型。
三、赋值
3.1、静态赋值:
student_name := '张静';
3.2、动态赋值:
select name into student_name from class where stu_No = 1;
--或者
execute 'select name from class where stu_No = 1' into student_name;
四、基本流程语句:存储过程中,使用RAISE NOTICE可以在运行时将变量输出显示
4.1、if语句
IF ... THEN ... END IF;
IF ... THEN ... ELSE ... END IF;
IF ... THEN ... ELSE ... THEN ... ELSE ... END IF;
--例:
if student_name = '张静' then
RAISE NOTICE '我是张静';
else if student_name like '%李%' then
RAISE NOTICE '我姓李';
else
RAISE NOTICE '我不是张静,也不姓李';
4.2、case语句
CASE ... WHEN ... THEN ... ELSE ... END CASE;
CASE WHEN ... THEN ... ELSE ... END CASE;
--例:
case student_name when '张静','晓静' then
RAISE NOTICE '张静和晓静都是我的名称';
else
RAISE NOTICE '你叫错名字了';
end case;
--例:
case when student_name = '张静' or student_name = '晓静' then
RAISE NOTICE '张静和晓静都是我的名称';
else
RAISE NOTICE '你叫错名字了';
end case;
4.3、循环
[ <<label>> ]
LOOP
循环体语句;
EXIT [ label ] [ WHEN 判断条件表达式 ];
END LOOP [ label ]; --例-计算1到100的和:
sum := 0;
i := 0;
loop
i := i + 1;
sum := sum + i;
exit when i = 100 ;
end loop;
RAISE NOTOCE '1到100的和为:%',sum;
[ <<label>> ]
WHILE 判断条件表达式 LOOP
循环体语句;
END LOOP [ label ]; --例 - 计算1到100的和:
sum := 0;
i := 1;
while i<=100 loop
sum := sum + i;
i := i + 1;
end loop
RAISE NOTOCE '1到100的和为:%',sum;
[ <<label>> ]
FOR 循环控制变量 IN [ REVERSE ] 循环范围 [ BY expression ] LOOP
循环体语句;
END LOOP [ label ]; --计算1到100的和:
--例1 - 循环执行过程类似于:for(i=1;i<=100;i++){}
sum := 0;
for i in 1..100 loop
sum := sum + i;
end loop;
RAISE NOTOCE '1到100的和为:%',sum; --例2 - 循环执行过程类似于:for(i=100;i>=1;i--){}
sum := 0;
for i in REVERSE 100..1 loop
sum := sum + i;
end loop;
RAISE NOTOCE '1到100的和为:%',sum; --计算1到100之间所有奇数的和
--例3 - 循环执行过程类似于:for(i=1;i<=100;i=i+2){}
sum := 0;
for i in 1..100 by 2 loop
sum := sum + i;
end loop;
RAISE NOTOCE '1到100的和为:%',sum;
[ <<label>> ]
FOR 变量 IN 查询语句 LOOP
循环体语句;
END LOOP [ label ]; --例 - 遍历班级中每个人的名字:
for student_name in select name from class loop
RAISE NOTICE '姓名:%',student_name;
end loop;
四、查询并返回多条记录
案例1:
create or replace function f_get_member_info(id integer)
returns setof record as --setof是关键字,暂时不清楚其作用;record是返回的数据类型,即记录类型数据;
$$ --两个美元符必须存在,中间可以填入符合命名规则的字符(如$body$,$abc$),但必须与下方的两个美元符相统一
declare
rec record; --定义记录类型的变量,用于存储查询的结果
begin
--开始for循环,执行SELECT语句。注意,loop后没有分号!
for rec in EXECUTE 'SELECT id,real_name FROM a_account_all' loop
return next rec; --将查询结果依次追加到rec变量中
end loop; --for循环结束
return;
end
$$
language 'plpgsql'; --调用存储过程f_get_member_info示例
-- a_account_all 为存储过程中被查询的表,id和real_name是表中的字段,也是在存储过程中被查询的字段
SELECT * FROM f_get_member_info(1568) as a_account_all(id integer,real_name character varying(50));
CREATE OR REPLACE FUNCTION public.test()
RETURNS SETOF record
LANGUAGE 'plpgsql' --这三句话我也还没搞懂其含义,但加上不会报错
COST 100
VOLATILE
ROWS 1000 AS $BODY$
DECLARE
temp_rec record ;--第一个记录集
rec record ;--第二个记录集
BEGIN
--给第一个结果集赋值
for temp_rec in execute 'SELECT 1,2,3' loop
return next temp_rec;
RAISE NOTICE 'temp_rec:%',temp_rec;
end loop; --给第二个结果集赋值
for rec in execute 'SELECT 4,5,6' loop
return next rec;
RAISE NOTICE 'rec:%',rec;
end loop; --给第二个结果集追加值
rec := (9,8,7);
return next rec; --将两个结果集一起返回
return ;
END
$BODY$; ALTER FUNCTION public.test()
OWNER TO postgres; -- 调用示例:
SELECT * FROM test() as temp1(num_1 integer,num_2 integer,num_3 integer);
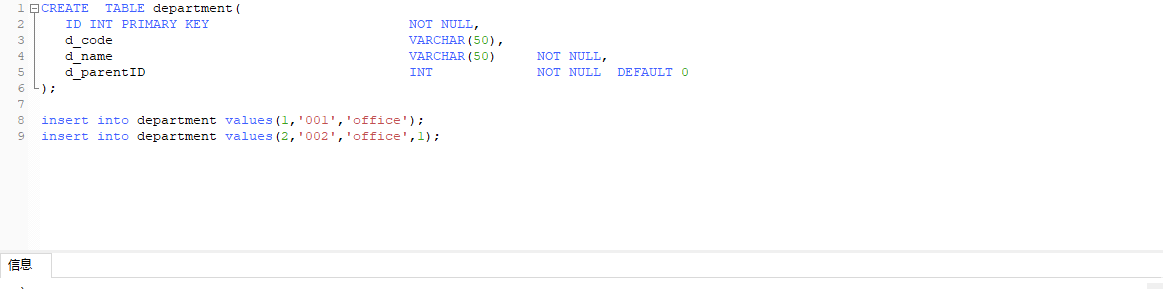
实战案例:获取数据表中ID最大值:
CREATE TABLE department(
ID INT PRIMARY KEY NOT NULL,
d_code VARCHAR(50),
d_name VARCHAR(50) NOT NULL,
d_parentID INT NOT NULL DEFAULT 0
); insert into department values(1,'001','office');
insert into department values(2,'002','office',1);
create or replace function f_getNewID(myTableName text,myFeildName text) returns integer as $$
declare
mysql text;
myID integer;
begin
mysql:='select max('
|| quote_ident(myFeildName)
||') from '
|| quote_ident(myTableName);
execute mysql into myID;
--using myTableName,myFeildName; if myID is null or myID=0 then return 1;
else return myID+1;
end if;
end;
$$ language plpgsql;
调用:
select f_getnewid('department','id');
总结一下:
1、存储过程(FUNCITON)变量可以直接用 || 拼接。上面没有列出,下面给个栗子;
create or replace function f_getNewID(myTableName text,myFeildName text) returns integer as $$
declare
mysql text;
myID integer;
begin
mysql:='select max('|| $2 || ' ) from '||$1;
execute mysql into myID using myFeildName,myTableName;
if myID is null or myID=0 then return 1;
else return myID+1;
end if;
end;
$$ language plpgsql;
2、存储过程的对象不可以直接用变量,要用 quote_ident(objVar)
3、$1 $2是 FUNCTION 参数的顺序,如1中的 $1 $2交换,USING 后面的不换 结果 :select max(myTableName) from myFeildname
4、注意:SQL语句中的大写全部会变成小写,要想大写存大,必须要用双引号。
总结:
1. 运行速度:对于很简单的 sql ,存储过程没有什么优势。对于复杂的业务逻辑,因为在存储过程创建的时候,数据库已经对其进行了一次解析和优化。存储过程一旦执行,在内存中就会保留一份这个存储过程,这样下次再执行同样的存储过程时,可以从内存中直接调用,所以执行速度会比普通 s ql 快。
2. 减少网络传输:存储过程直接就在数据库服务器上跑,所有的数据访问都在数据库服务器内部进行,不需要传输数据到其它服务器,所以会减少一定的网络传输。但是在存储过程中没有多次数据交互,那么实际上网络传输量和直接 sql 是一样的。而且我们的应用服务器通常与数据库是在同一内网,大数据的访问的瓶颈会是硬盘的速度,而不是网速。
3. 可 维护性:的存储过程有些时候比程序更容易维护,这是因为可以实时更新 DB 端的存储过程 。 有些 bug ,直接改存储过程里的业务逻辑,就搞定了。
4. 增强安全性:提高代码安全,防止 SQL 注入 。这一点 sql 语句也可以做到。
5. 可扩展性:应用程序和数据库操作分开,独立进行,而不是相互在一起。方便以后的扩展和 DBA 维护优化。
https://blog.csdn.net/Mr_Door/article/details/102527225
PGSQL存储过程学习的更多相关文章
- SQL server存储过程学习
由于之前使用 Linq to Sql来操作数据库,对于数据库的存储过程.函数等比较薄弱.乘着自己闲着的时候,就百度自学了一点存储过程,以防以后要用. 基础通俗易懂的存储过程通过 存储过程学习 ,然后自 ...
- mysql 5.0存储过程学习总结
mysql存储过程的创建,删除,调用及其他常用命令 本人qq群也有许多的技术文档,希望可以为你提供一些帮助(非技术的勿加). QQ群: 281442983 (点击链接加入群:http://jq.q ...
- Oracle存储过程学习使用
存储过程创建语法: create or replace procedure 存储过程名(param1 in type,param2 out type) as 变量1 类型(值范围); 变量2 类型(值 ...
- MySQL存储过程学习笔记
MySQL在5.0以前并不支持存储过程,这使得MySQL在应用上大打折扣.MySQL 5.0终于开始支持存储过程了. MySQL的关键字大小写通用.该学习笔记对关键字使用大写:变量名,表名使用小写. ...
- mySql-数据库之存储过程学习总结
之前在工作中总是听别人提到存储过程,觉得是个很高深的东西,利用工作之余,看了下相关的知识,现将学习知识总结如下,希望可以为刚学习的人提供些许帮助. 开发环境:Navicat For Mysql. My ...
- postgresql PL/pgSQL—存储过程结构和变量声明
ref: https://www.postgresql.org/docs/9.6/static/plpgsql-structure.html 一. 函数结构 CREATE FUNCTION somef ...
- sqlsever存储过程学习笔记
1,创建数据表 use test create table money( id ,) primary key, money int, monetary_unity char ); 2,考虑到货币单位的 ...
- mysql存储过程学习
一.存储过程的创建 语法: CREATE PROCEDURE sp_name (参数)合法的SQL语句 mysql> delimiter // mysql> CREATE PROCEDUR ...
- ORACLE存储过程学习
存储过程 1 CREATE OR REPLACE PROCEDURE 存储过程名 2 IS 3 BEGIN 4 NULL; 5 END; 行1: CREATE OR REPLACE PROCEDURE ...
随机推荐
- 「题解」agc031_c Differ by 1 Bit
本文将同步发布于: 洛谷博客: csdn: 博客园: 简书: 题目 题目链接:洛谷 AT4693.AtCoder agc031_c. 题意概述 给定三个数 \(n,a,b\),求一个 \(0\sim ...
- 一、DNS服务器的搭建
一.介绍 DNS服务:域名解析 将域名解析ip地址 DNS服务器的功能– 正向解析:根据注册的域名查找其对应的IP地址– 反向解析:根据IP地址查找对应的注册域名,不常用 所有完整的域名都要以点结 ...
- ld-linux-x86-64消耗大量的CPU
1.现象: 服务器CPU使用率很高 top查看cpu使用进程: 2.进程用户是oracle,根据spid查看是否是数据库进程,经过查询发现:不是数据库内部的进程 select a.sql_id,a.s ...
- qemu-ga windows下的安装及监控开发
windows安装qemu-ga 虚拟机配置里添加virtio serial端口 #virsh edit instance-name devices里添加下面这段配置, 1 <channel t ...
- Mysql的5种索引添加类型
1.添加普通索引: alter table 'table_name' add index index_name('column') 2.添加主键索引 alter table 'table_name' ...
- kafka高性能吞吐原因
1. 简单回顾 Kafka作为时下最流行的开源消息系统,被广泛地应用在数据缓冲.异步通信.汇集日志.系统解耦等方面.相比较于RocketMQ等其他常见消息系统,Kafka在保障了大部分功能特性的同时, ...
- android studio开发小笔记1
1.点击空白处隐藏软键盘 /* 隐藏软键盘 * */ public boolean dispatchTouchEvent(MotionEvent ev) { if (ev.getAction() == ...
- AcWing 90. 64位整数乘法
求a*b%p的值. 0<a,b,p<1e18; 原题链接 #include<bits/stdc++.h> #define ull unsigned long long usin ...
- 暑假自学java第七天
1,Object类: 任何类的父类都是Object 任何子类的对象都可以赋值给父类的引用.任何类的所有实例都可以用Object来代替 (3条消息) java中的Object类_iqqcode-CSDN ...
- Python 类与对象 __init__()参数
创建类Person 1 class Person: 2 def __init__(self, name, age): 3 self.name = name 4 self.age = age 5 pas ...