python爬取ip地址
ip查询,异步get请求
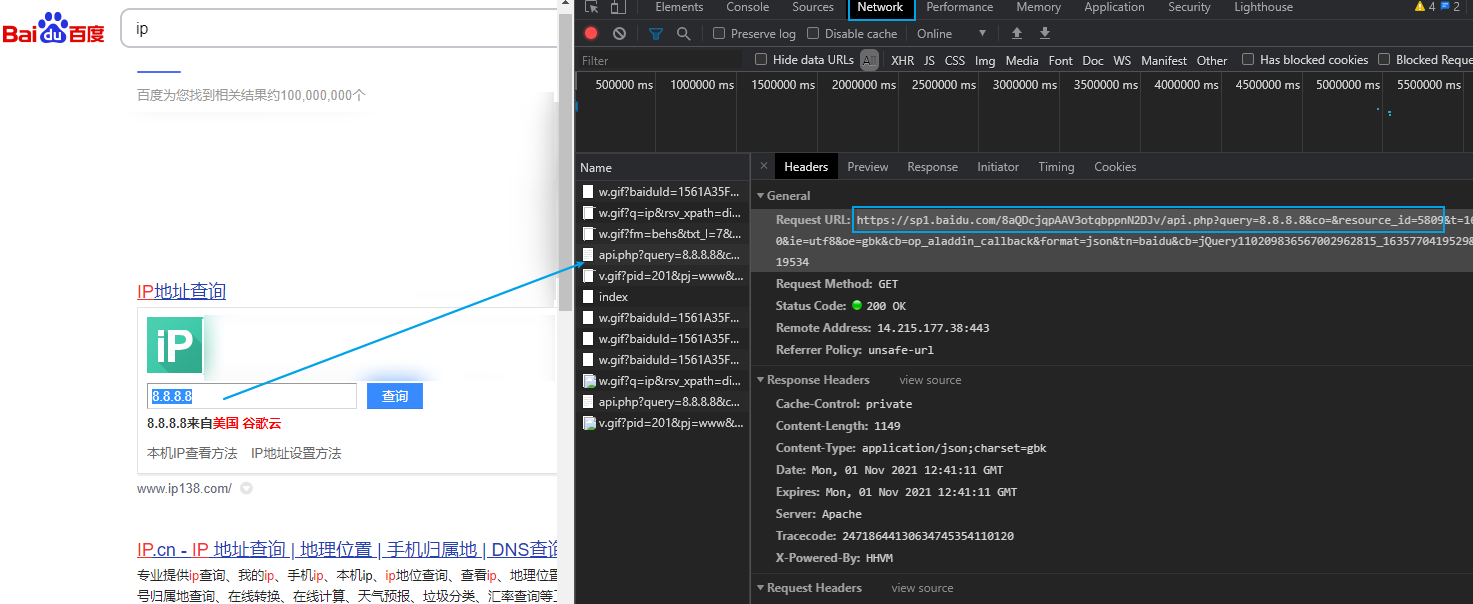
分析接口,请求接口响应json

发现可以data中获取 result.json()['data'][0]['location']
# _*_ coding : utf-8 _*_
# @Time : 2021/11/1 20:29
# @Author : 秋泊酱
# @File : ip抓取 import requests
ips = ['8.8.8.8']
result = requests.get('https://sp1.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='+ips[0]+'&co=&resource_id=5809',verify = False)
print(result.json()['data'][0]['location'])

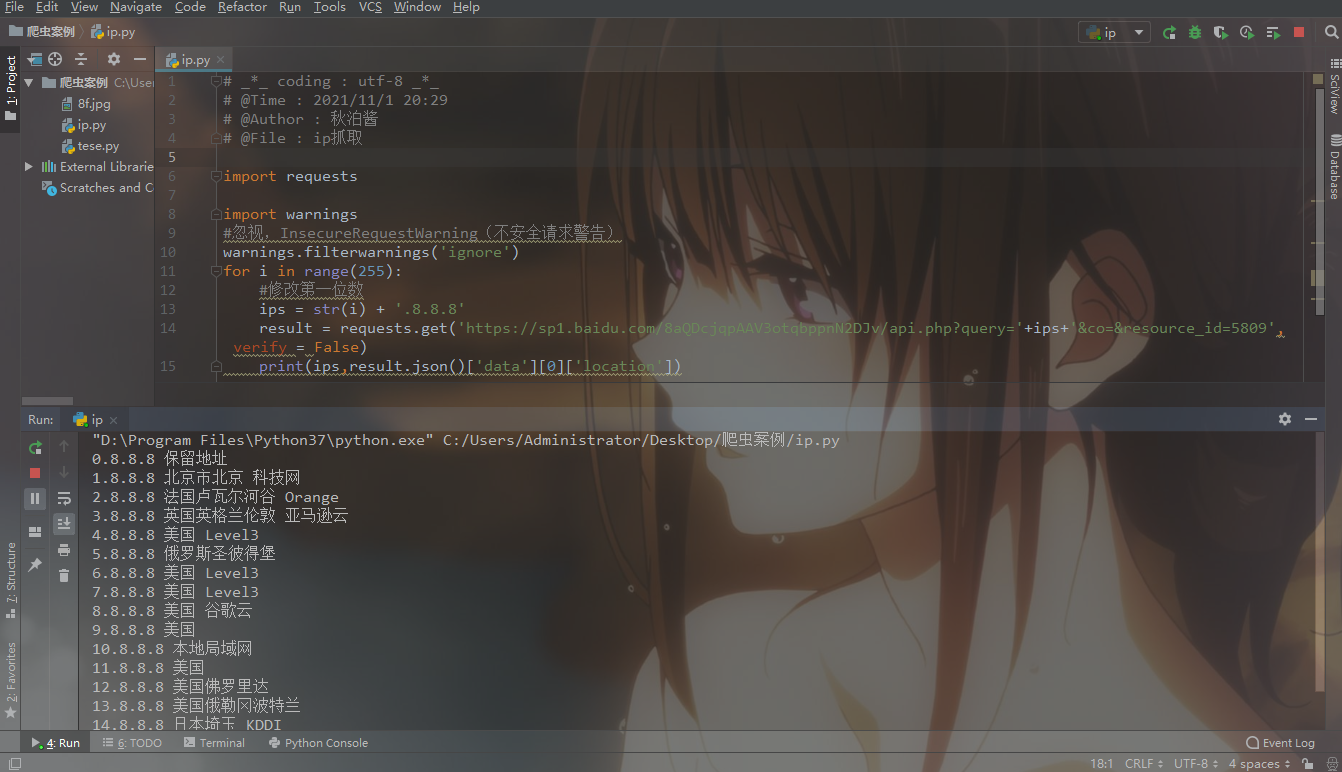
for构造255个ip池演示
# _*_ coding : utf-8 _*_
# @Time : 2021/11/1 20:29
# @Author : 秋泊酱
# @File : ip抓取 import requests import warnings
#忽视,InsecureRequestWarning(不安全请求警告)
warnings.filterwarnings('ignore')
for i in range(255):
#修改第一位数
ips = str(i) + '.8.8.8'
result = requests.get('https://sp1.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='+ips+'&co=&resource_id=5809',verify = False)
print(ips,result.json()['data'][0]['location'])
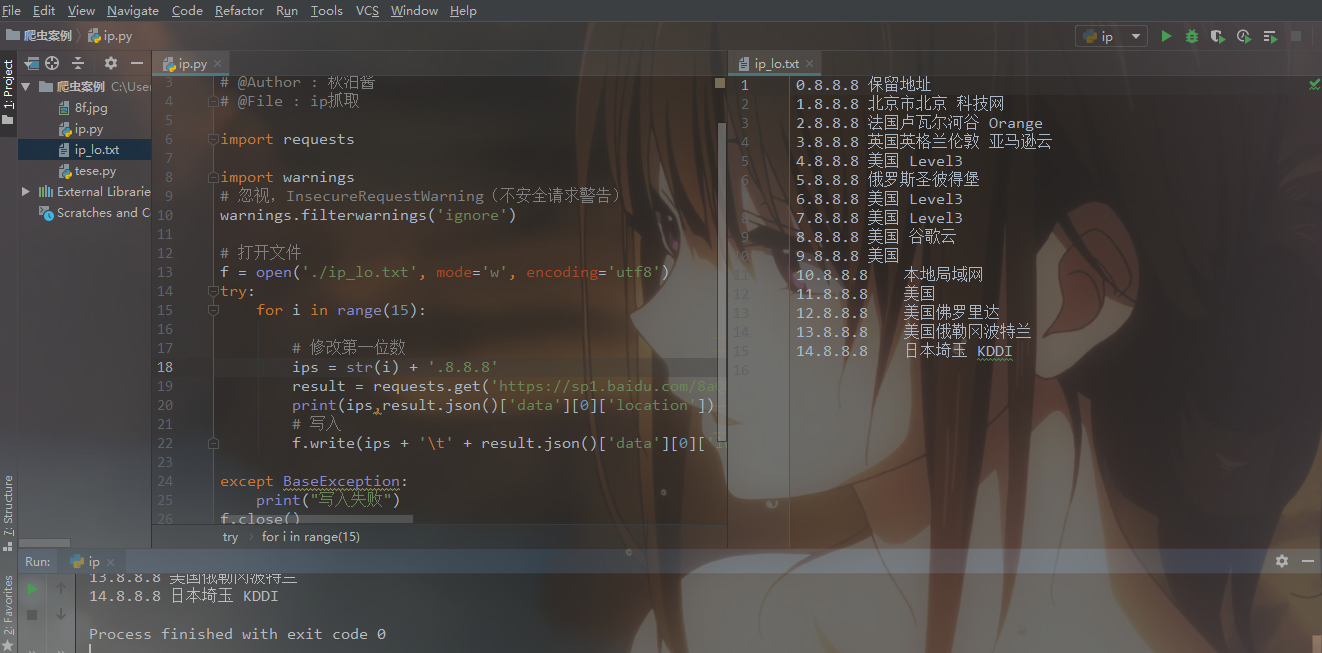
写入txt中
# _*_ coding : utf-8 _*_
# @Time : 2021/11/1 20:29
# @Author : 秋泊酱
# @File : ip爬取 import requests import warnings
# 忽视,InsecureRequestWarning(不安全请求警告)
warnings.filterwarnings('ignore') # 打开文件
f = open('./ip_lo.txt', mode='w', encoding='utf8')
try:
for i in range(15): # 修改第一位数
ips = str(i) + '.8.8.8'
result = requests.get('https://sp1.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query='+ips+'&co=&resource_id=5809',verify = False)
print(ips,result.json()['data'][0]['location'])
# 写入
f.write(ips + '\t' + result.json()['data'][0]['location'] + '\n') except BaseException:
print("写入失败")
f.close()
python爬取ip地址的更多相关文章
- python Requests库网络爬取IP地址归属地的自动查询
#IP地址查询全代码import requestsurl = "http://m.ip138.com/ip.asp?ip="try: r = requests.get(url + ...
- Python练习:爬虫练习,从一个提供免费代理的网站中爬取IP地址信息
西刺代理,http://www.xicidaili.com/,提供免费代理的IP,是爬虫程序的目标网站. 开始写程序 import urllib.requestimport re def open_u ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
随机推荐
- 提问式复习:图文回顾 redo log 相关知识
原文链接:提问式复习:图文回顾 redo log 相关知识 1.如何提升 redo日志 的写性能? 为了保证 redo日志 不丢失,会在磁盘中开辟一块空间将日志保存起来.但是这样会有一个问题,磁盘的读 ...
- webRTC中语音降噪模块ANS细节详解(一)
ANS(adaptive noise suppression) 是webRTC中音频相关的核心模块之一,为众多公司所使用.从2015年开始,我在几个产品中使用了webRTC的3A(AEC/ANS/AG ...
- Django实现用户登录注册
本文将会介绍小白如何完成一个用户登录注册系统 新建一个Django项目,名字为login_register,并且使用命令manage.py startapp.User(名字自己随便起) 最终djang ...
- 洛谷3628 APIO2010特别行动队(斜率优化)
考虑最普通的\(dp\) \[dp[i]=max(dp[j]+a*(sum[i]-sum[j])^2+b*(sum[i]-sum[j])+c \] qwq 由于演算纸扔掉了 qwq 所以直接给出最后的 ...
- 2021.3.10--vj补题
B - Saving the City cf--1443B Bertown is a city with nn buildings in a straight line. The city's sec ...
- 实战-快手H5字体反爬
实战-快手H5字体反爬 前言 快手H5端的粉丝数是字体反爬,抓到的html文本是乱码 <SPAN STYLE='FONT-FAMILY: kwaiFont;'></SPA ...
- OutOfMemoryException异常解析
一.概述 在国庆休假快结束的最后一天晚上接到了部门老大的电话,某省的服务会出现崩溃问题.需要赶紧修复,没错这次的主角依旧是上次的"远古项目"没有办法同事都在休假没有人能帮忙开电脑远 ...
- 利用python爬取全国水雨情信息
分析 我们没有找到接口,所以打算利用selenium来爬取. 代码 import datetime import pandas as pd from bs4 import BeautifulSoup ...
- 电脑日常使用bug记录
1.由于电脑太卡了,于是决定关一点服务,一不小心,电脑无线无法使用了.启动无线服务时提示"windows无法启动wlan autoconfig服务错误1068依赖服务" 启动 Ex ...
- 【UE4 设计模式】外观模式 Facade Pattern
概述 描述 外部与一个子系统的通信必须通过一个统一的外观对象进行,为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用.外观模式又称为门面模式,它是一 ...