HDFS【概述、数据流】
概述
定义
HDFS是一个分布式文件管理系统
优缺点
优点
(1)高容错
多副本提高容错、某个副本丢失可以自动恢复
(2)适合处理大数据
能处理PB级别数据、能处理百万的文件数据量
(3)可构建在廉价机器上
缺点
(1)不适合低时延数据访问
(2)无法高效存储小文件
(3)不支持并发写入和文件修改
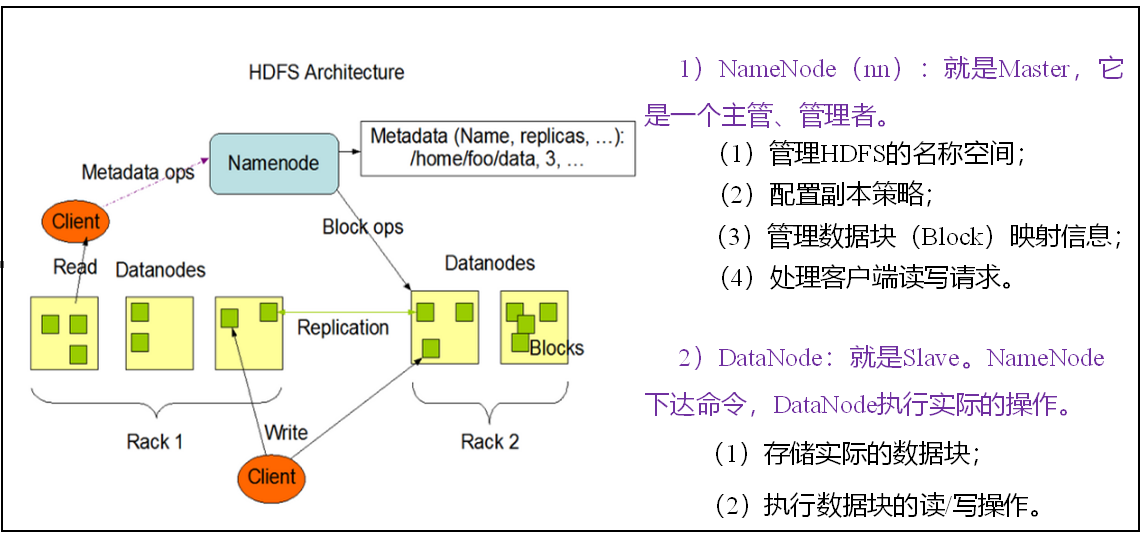
HDFS组成架构

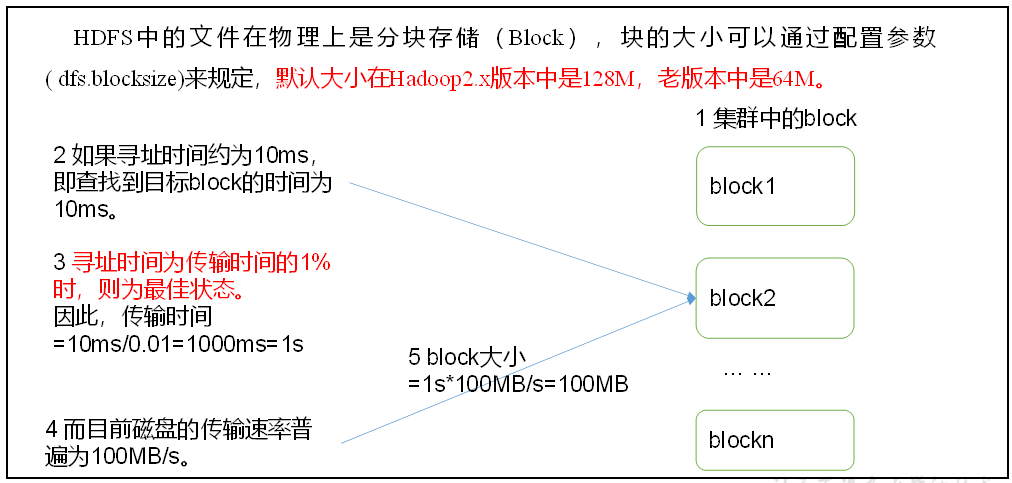
HDFS文件块大小

HDFS数据流
写数据
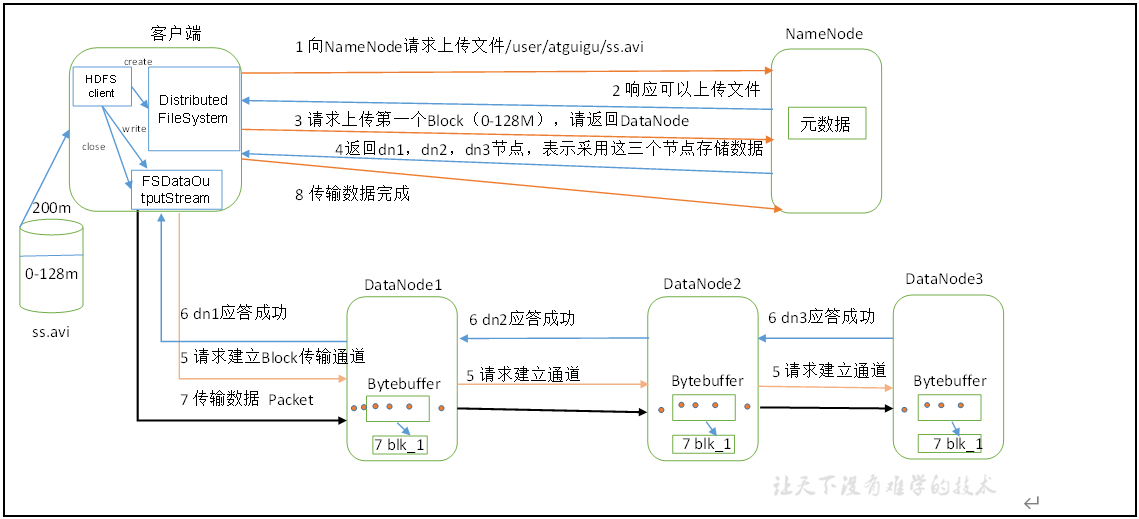
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
读数据
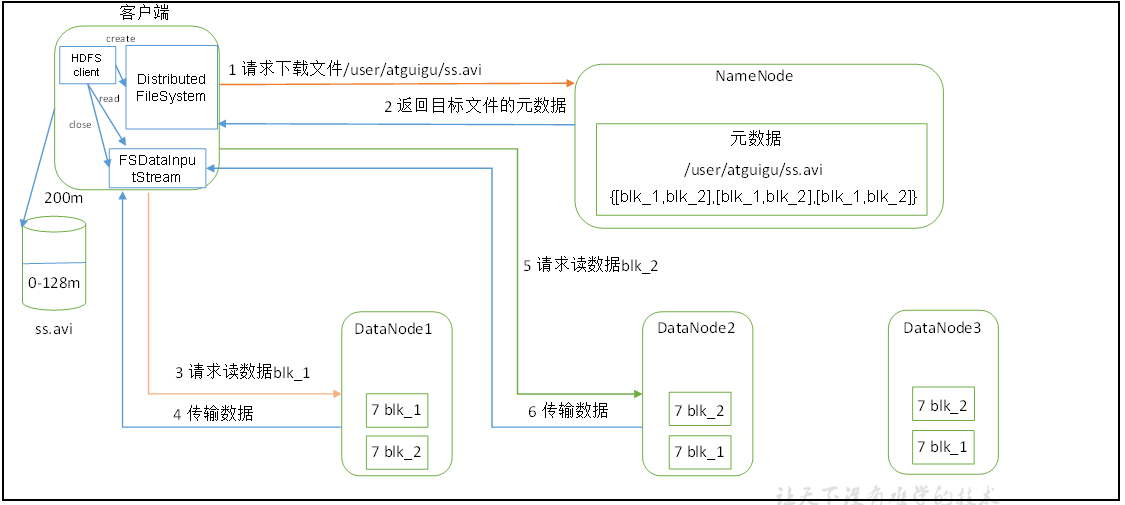
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
网络拓扑-节点距离计算
节点距离:两个节点到达最近的共同祖先的距离总和
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
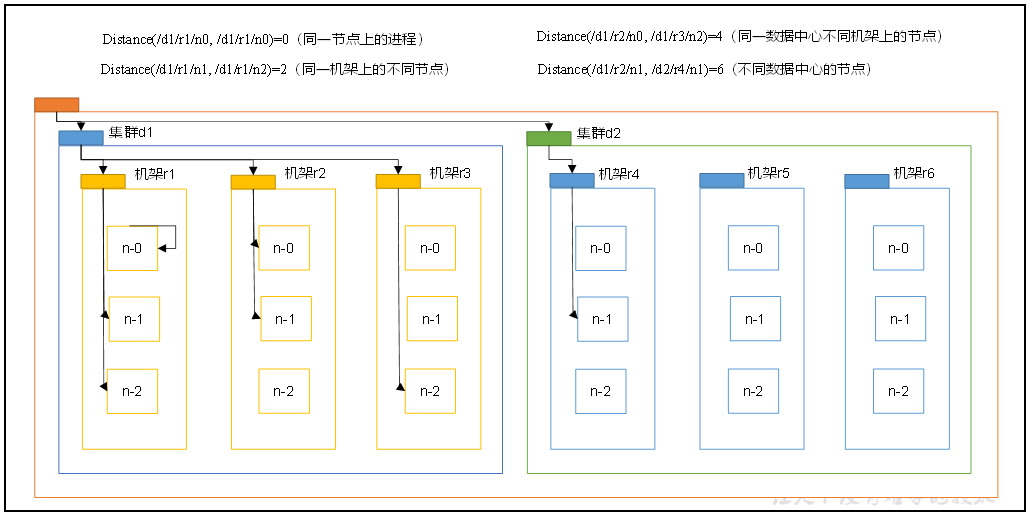
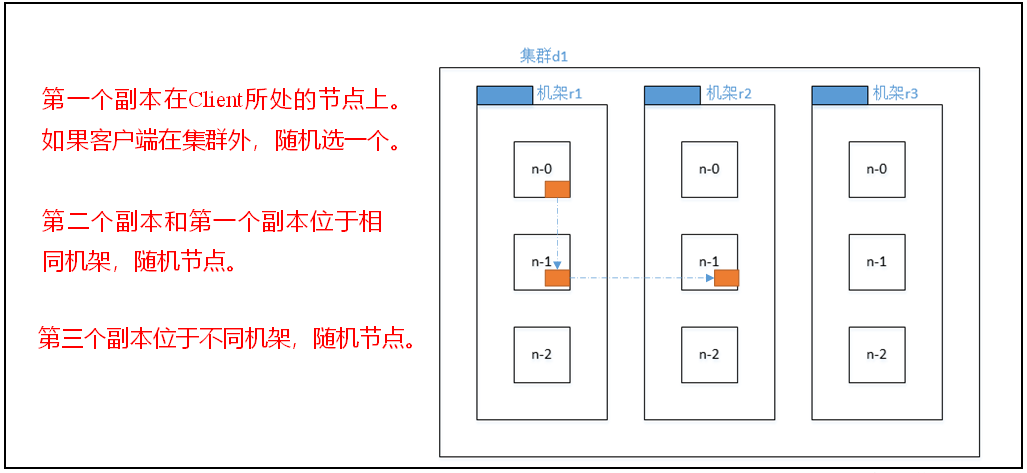
机架感知(写数据的副本存储节点选择)
官网介绍(2.X和3.X策略不同)
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
- hadoop2.7.2版本(2-1)
- hadoop3.1.3版本(1-2)
HDFS【概述、数据流】的更多相关文章
- HDFS概述
HDFS概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS产出背景及定义 1>.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配 ...
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- HDFS概述和Shell操作
大数据技术之Hadoop(HDFS) 第一章 HDFS概述 HDFS组成架构 HDFS文件块大小 第二章 HDFS的Shell操作(开发重点) 1.基本语法 bin/hadoop fs 具体命令 ...
- HDFS概述(6)————用户手册
目的 本文档是使用Hadoop分布式文件系统(HDFS)作为Hadoop集群或独立通用分布式文件系统的一部分的用户的起点.虽然HDFS旨在在许多环境中"正常工作",但HDFS的工作 ...
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- HDFS概述(4)————HDFS权限
概述 Hadoop分布式文件系统(HDFS)的权限模型与POSIX模型的文件和目录权限模型一致.每个文件和目录与所有者和组相关联.该文件或目录将权限划分为所有者的权限,作为该组成员的其他用户的权限.以 ...
- HDFS概述(3)————HDFS Federation
本指南概述了HDFS Federation功能以及如何配置和管理联合集群. 当前HDFS背景 HDFS主要有两层: 1.Namespace (1)包含目录,文件和块. (2)它支持所有命名空间相关的文 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- HDFS概述(2)————Block块大小设置
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=ref ...
- Hadoop之HDFS概述
一.HDFS产生背景及定义 1.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文 ...
随机推荐
- Ubuntu virtualenv 创建 python2 虚拟环境 激活 退出
首先默认安装了virtualenv 创建python2虚拟环境 your-name@node-name:~/virtual_env$ virtualenv -p /usr/bin/python2 py ...
- cf16C Monitor(额,,,,水数学,,)
题意: 一块镜子长宽是a*b.现在要调整(切割)成x:y的比例. 问调整完的最大面积是多少. 思路: 先将x,y弄成最简比例,然后放大到不超过min(a,b)即可. 代码: ll a,b,x,y; l ...
- 记一次 Java 导出大批量 Excel 优化
常用的excel导出方案,详情见Spring Boot 入门(十二):报表导出,对比poi.jxl和esayExcel的效率,其中jxl.esayEscel 底层都是基于 poi,它们仅仅是对 poi ...
- Linux&c 文件操作,线程进程控制,网络编程,简单知识点梳理
一:文件操作 在linux下,一切皆文件,目录是文件,称为目录文件,内容是该目录的目录项(但是目录只有内核可以编辑,超级用户也不可以编辑),设备也是设备文件,在/dev存放的就是一些设备文件,linu ...
- python编写脚本,登录Github通过指定仓库指定敏感关键字搜索自动化截图生成文件【完美截图】
前言:为了避免开发人员将敏感信息写入文件传到github,所以测试人员需要检查每个仓库是否有写入,人工搜索审核比较繁琐,所以写一个脚本通过配置 配置文件,指定需要搜索的仓库和每个仓库需要搜索的关键字, ...
- rz安装
rpm -ivh http://www.rpmfind.net/linux/centos/6.10/os/x86_64/Packages/lrzsz-0.12.20-27.1.el6.x86_64.r ...
- maven中的distributionManagement的作用
mvn install 会将项目生成的构件安装到本地Maven仓库,mvn deploy 用来将项目生成的构件分发到远程Maven仓库. 本地Maven仓库的构件只能供当前用户使用,在分发到远程Ma ...
- 浅谈web前端优化
开篇 优化网站是一个系统性和持续性的过程.很多人认为优化网站的性能只需要合并图片啦,减小HTTP请求啦,部署CDN啦就行,实际上这都是见木不见林的做法.以上的做法经常会被面试者提起,在被问到自己在网页 ...
- 让textarea根据文本的长度自动调整它的高度
... <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR ...
- Apache Kyuubi 助力 CDH 解锁 Spark SQL
Apache Kyuubi(Incubating)(下文简称Kyuubi)是⼀个构建在Spark SQL之上的企业级JDBC网关,兼容HiveServer2通信协议,提供高可用.多租户能力.Kyuub ...