scrapy爬虫框架调用百度地图api数据存入数据库
scrapy安装配置不在本文 提及,
1.在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令
scrapy startproject mySpider
- 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
mySpider/spiders/__init__.py :爬虫主要处理逻辑
2. 今天通过爬虫调用 百度地图api来获取 全国学校的经纬度信息 并入库。
百度地图接口api :http://api.map.baidu.com/place/v2/search?query=小学、中学或者大学®ion=地市名字&output=json&ak=你的开发者ak&page_num=页码
1)打开mySpider目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据,也是爬取数据后导出的字段,有点像Python中的dict字典,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item。
items.py
1 import scrapy
2
3
4 class GetpointItem(scrapy.Item):
5 # define the fields for your item here like:
6 # name = scrapy.Field()
7 name = scrapy.Field() #学校名称
8 lat = scrapy.Field() #纬度
9 lng = scrapy.Field() #经度11 city = scrapy.Field() #地市
12 area = scrapy.Field() #区县
13 address = scrapy.Field() #地址
14 types = scrapy.Field() #学校类型(小学,中学,大学)
2) 打开 mySpider/spiders目录里的 __init__.py写逻辑 ,直接上代码,有注释
1 import scrapy
2 import json
3 from urllib.parse import urlencode
4 from .. import items
5 class DmozSpider(scrapy.Spider):
6 name = "map"
7 allowed_domains = []
8 #三层循环数组分别请求api,由于百度api返回的数据不是所有,所以必须传入页码,来爬取更多数据。
10 def start_requests(self):
11 cities = ['北京','上海','深圳']14 types =['小学','中学','大学']
15 for city in cities:
16 for page in range(1, 16):
17 for type_one in types:
18 base_url = 'http://api.map.baidu.com/place/v2/search?'
19 params = {
20 'query': type_one,
21 'region': city,
22 'output':'json',
23 'ak': '你的ak',
25 'page_num': page
26 }
27 url = base_url + urlencode(params)
28 yield scrapy.Request(url, callback=self.parse,meta={"types":type_one})
29
30 def parse(self, response):
31 res = json.loads(response.text) #请求回来数据需转成json
32 result= res.get('results')
33 types = response.meta["types"] #由于api返回来数据没有学校type的数据,这里需要自己接一下 传参时的type参数
34 #print(types)
35 if result:
36 for result_one in result:
37 item = items.GetpointItem() #调用item的GetpointItem类,导出item
38 item['name'] = result_one.get('name')
39 item['lat'] = result_one.get('location').get('lat')
40 item['lng'] = result_one.get('location').get('lng')42 item['city'] = result_one.get('city')
43 item['area'] = result_one.get('area')
44 item['types'] = types
45 item['address'] = result_one.get('address')
46 yield item
47 else:
48 print('网络请求错误')
3)item导出来了,数据获取到了,然后 入库,打开pipelines.py ,代码如下:
from itemadapter import ItemAdapter
import pymysql
import json class DBPipeline(object):
def __init__(self):
# 连接MySQL数据库
self.connect=pymysql.connect(host='localhost',user='root',password='1q2w3e',db='mapspider',port=3306)
self.cursor=self.connect.cursor()
def process_item(self, item, spider):
# 往数据库里面写入数据
try:
self.cursor.execute("""select * from school where name = %s""", item['name'])
ret = self.cursor.fetchone()
if ret:
print(item['name']+'***********数据重复!***************')
else:
self.cursor.execute(
"""insert into school(name, lng, lat, type,city,county,address)
value (%s, %s, %s, %s, %s, %s, %s)""",
(
item['name'],
json.dumps(item['lng']),
json.dumps(item['lat']),
item['types'],
item['city'],
item['area'],
item['address']
))
self.connect.commit()
return item
except Exception as eror:
print('错误')
# 关闭数据库
def close_spider(self,spider):
self.cursor.close()
self.connect.close()
重复数据的话,fecthOne直接排除 ,入库。。。。,
4)执行脚本 scray crawl map
scrapy crawl map
name 要写对哦

回车 ,开始 唰唰唰
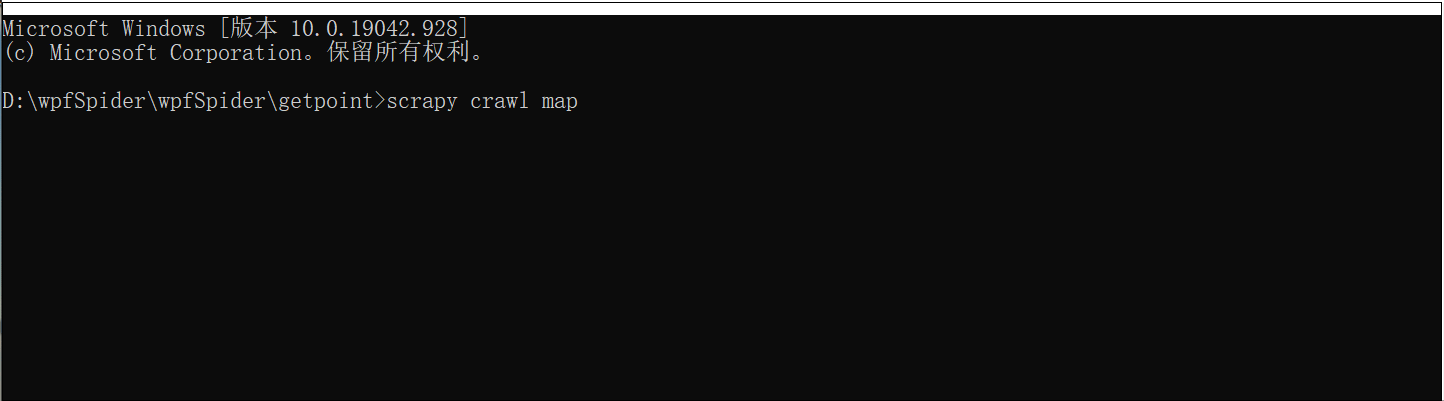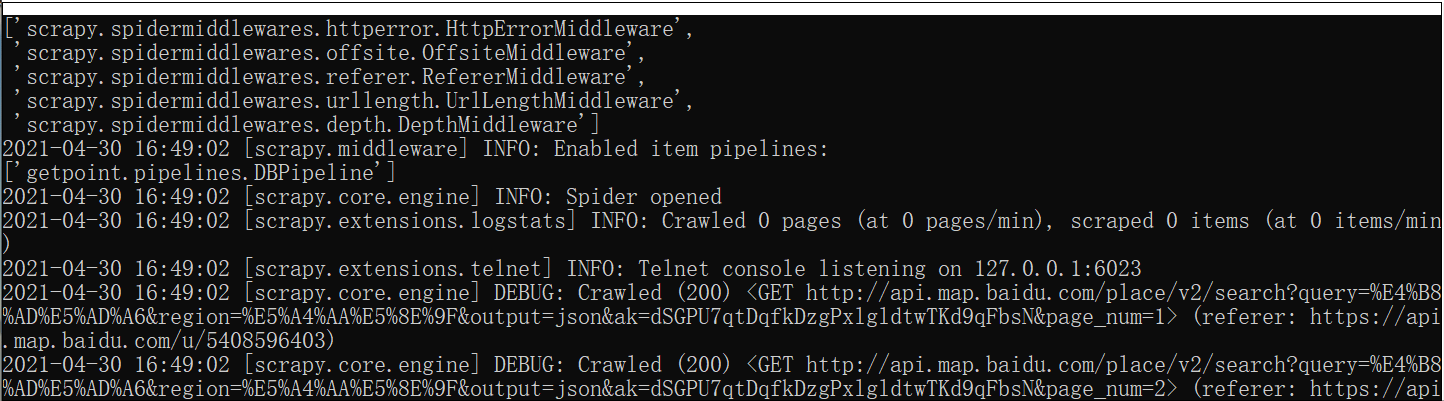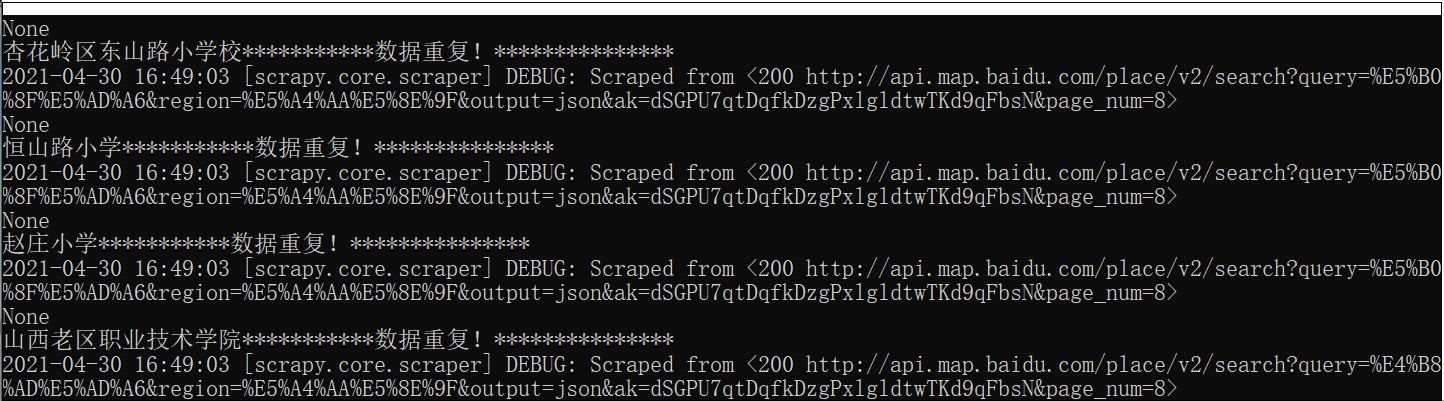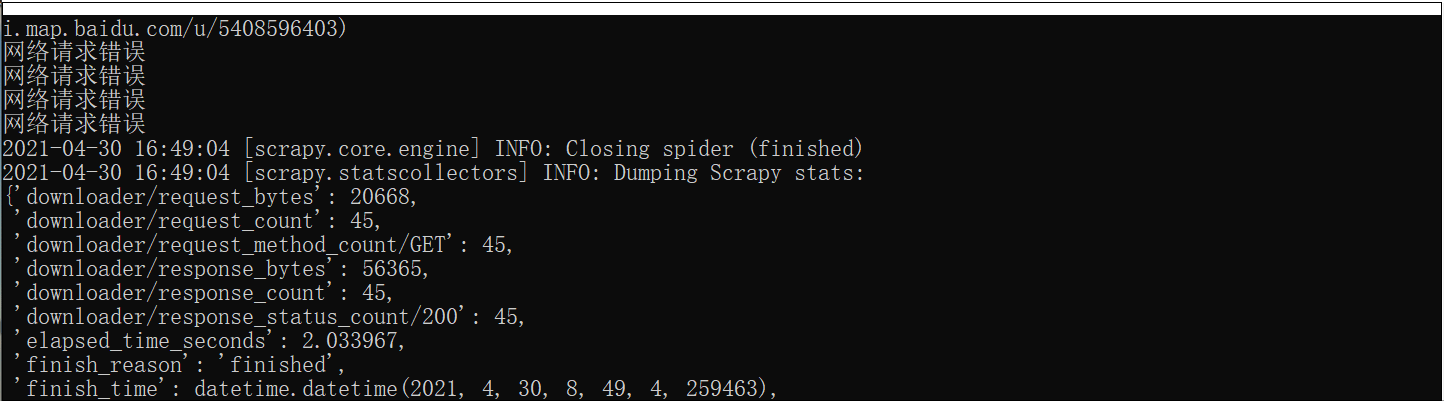
成果如下:
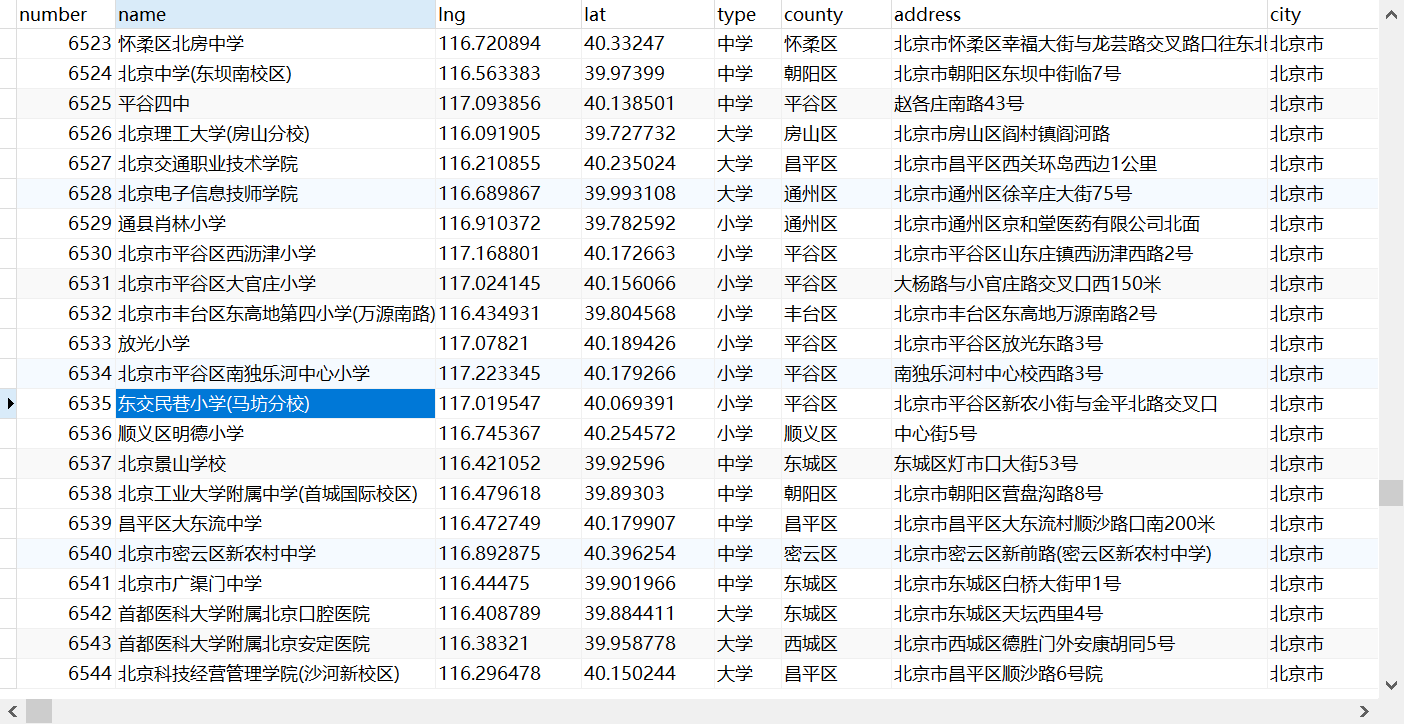
期间 ,百度地图 api 多次并发,不让访问了,多爬几次就好了,程序逻辑 晓得就好了。
接口api爬完了,下次爬一爬 页面xpath上的内容。
scrapy爬虫框架调用百度地图api数据存入数据库的更多相关文章
- Python调用百度地图API实现批量经纬度转换为实际省市地点(api调用,json解析,excel读取与写入)
1.获取秘钥 调用百度地图API实现得申请百度账号或者登陆百度账号,然后申请自己的ak秘钥.链接如下:http://lbsyun.baidu.com/apiconsole/key?applicatio ...
- 调用百度地图Api实现的查看地图功能的小插件
1. 功能 bMap.js 可根据地理位置调用出百度地图,采用弹出框形式 2.用法 var city = '青岛市'; var address = '香港中路'; bMap.init({ city : ...
- 【c#】Form调用百度地图api攻略及常见问题
首先,在Form中调用百度地图api,我们需要使用webbrowser控件,这个在前面的文章中已经讲过了,可以参照(http://blog.csdn.net/buptgshengod/article/ ...
- HTML5调用百度地图API获取当前位置并直接导航目的地的方法
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <meta charset="UTF-8&quo ...
- HTML5 调用百度地图API地理定位
<!DOCTYPE html> <html> <title>HTML5 HTML5 调用百度地图API地理定位实例</title> <head&g ...
- 跨平台移动开发_PhoneGap 使用Geolocation基于所在地理位置坐标调用百度地图API
使用Geolocation基于所在地理位置坐标调用百度地图API 效果图 示例代码 <!DOCTYPE html> <html> <head> <title& ...
- HTML5调用百度地图API进行地理定位实例
自从HTML5的标准确定以后,越来越多的网站使用HTML5来进行开发.虽然对HTML5支持的浏览器不是很多,但是依然抵挡不了大伙对HTML5开发的热情.今天为大家带来的是使用HTML5调用百度地图AP ...
- HTML5页面直接调用百度地图API,获取当前位置,直接导航目的地
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <meta charset="UTF-8"&g ...
- 调用百度地图API的总结
因为项目要用到百度地图,所以先摸索了一下,各种功能官方都有文档,点击可查看,文章的话我就直接写我用到的功能例子了,要用可以直接复制粘贴~ 一.主要涉及到的几个接口(先申请密钥): 1.技术一:坐标转换 ...
随机推荐
- 力扣496. 下一个更大元素 I
原题 1 class Solution: 2 def nextGreaterElement(self, nums1: List[int], nums2: List[int]) -> List[i ...
- Java练习——抽象类
需求: 2辆宝马,1辆别克商务舱,1辆金龙(34)座,租5天共多少租金. 轿车 客车(金杯.金龙) 车型 别克商务舱GL8 宝马550i 别克林荫大道 <=16座 >16座 日租费(元 ...
- java基础知识 + 常见面试题
准备校招面试之Java篇 一. Java SE 部分 1.1 Java基础 1. 请你解释Object若不重写hashCode()的话,hashCode()如何计算出来的? Object 的 hash ...
- POJ-3159(差分约束+Dijikstra算法+Vector优化+向前星优化+java快速输入输出)
Candies POJ-3159 这里是图论的一个应用,也就是差分约束.通过差分约束变换出一个图,再使用Dijikstra算法的链表优化形式而不是vector形式(否则超时). #include< ...
- [源码分析] 消息队列 Kombu 之 启动过程
[源码分析] 消息队列 Kombu 之 启动过程 0x00 摘要 本系列我们介绍消息队列 Kombu.Kombu 的定位是一个兼容 AMQP 协议的消息队列抽象.通过本文,大家可以了解 Kombu 是 ...
- FreeBSD WIFI 配置
ee /boot/ loader.conf ee是个编辑器 中写入 rtwn_usb_load="YES" legal.realtek.license_ack=1 在 /etc/ ...
- ListView解析
ListView通过一个Adapter来完成数据和组件的绑定.以ListActivity为例,它集成自Activity,里面包含有一个ListAdapter和一个ListView.绑定的操作通过set ...
- LeetCode 175. Combine Two Tables 【MySQL中连接查询on和where的区别】
一.题目 175. Combine Two Tables 二.分析 连接查询的时候要考虑where和on的区别 where : 查询时,连接的时候是必须严格满足条件的,满足了才会加入到临时表中. on ...
- java注解基础入门
前言 这篇博客主要是对java注解相关的知识进行入门级的讲解,包括**,核心内容主要体现在对java注解的理解以及如何使用.希望通过写这篇博客的过程中让自己对java注解有更深入的理解,在工作中可以巧 ...
- 基金 A 类和 C 类、ETF、LOF、QDII 到底是啥?
ETF 对于初入股市的新手来说,买了一只公司股票容易,想买一个行业的股票就不是很容易了. 比如你要懂得行业里都有谁,每个公司分配多少钱,最主要股票交易最少要交易 1 手也就是 100 股,要是想配置一 ...