「Python实用秘技01」复杂zip文件的解压
本文完整示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/PythonPracticalSkills
这是我的新系列文章「Python实用秘技」的第1期,本系列立足于笔者日常工作中使用Python辅助办公的心得体会,每一期为大家带来一个3分钟即可学会的简单小技巧。
作为系列第1期,我们即将学习的是:复杂zip文件的解压。

废话不多说,直接看问题,使用过Python中的标准库zipfile解压过zip格式压缩包的朋友们,可能遇到过,当压缩文件中的目录或文件名中包含中文等常见unicode字符时,典型如下面的例子:
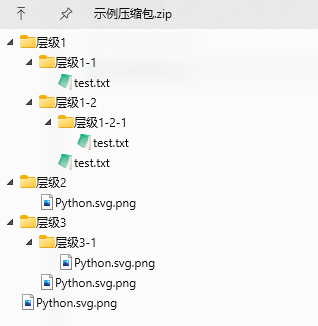
使用zipfile的extract()或extractall()方法直接解压时,产生的解压结果名充斥着乱码,这一点我们通过调用namelist()方法就可以看出来:
from zipfile import ZipFile
# 读入压缩包文件
file = ZipFile('示例压缩包.zip')
# 查看压缩包内目录、文件名称
file.namelist()

这是因为zipfile中针对压缩包内容的编码兼容性差,但我们可以通过下面的函数自行矫正:
def recode(raw: str) -> str:
'''
编码修正
'''
try:
return raw.encode('cp437').decode('gbk')
except:
return raw.encode('utf-8').decode('utf-8')
for file_or_path in file.namelist():
print(file_or_path, ' -------> ' , recode(file_or_path))
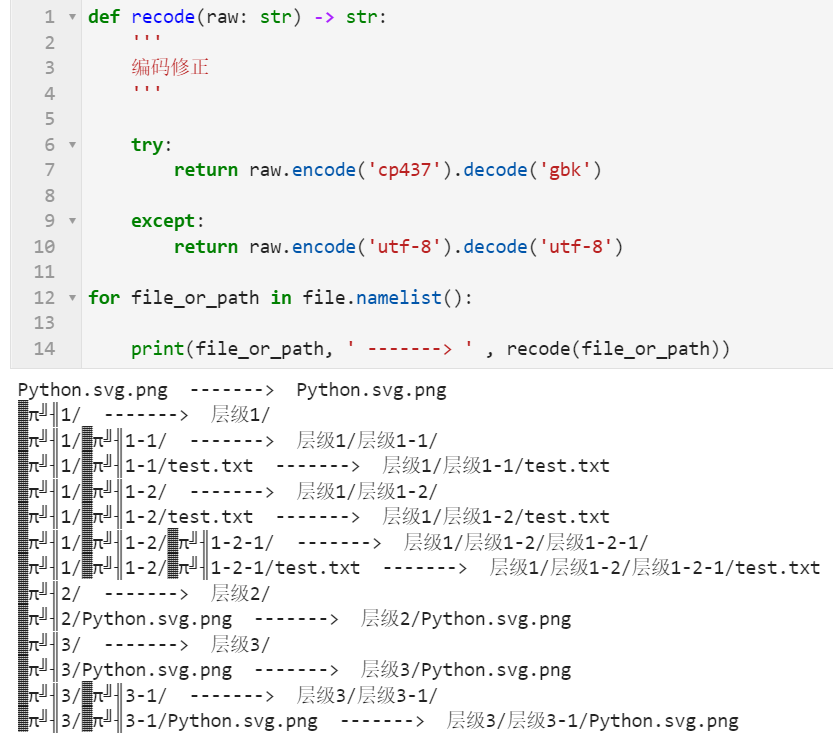
解决了文件名乱码的问题后,接下来我们就可以配合shutil与os标准库中的相关功能,实现将指定任意zip压缩包,完好地解压到指定的目录中,代码如下:
def zip_extract_all(src_zip_file: ZipFile, target_path: str) -> None:
# 遍历压缩包内所有内容
for file_or_path in file.namelist():
# 若当前节点是文件夹
if file_or_path.endswith('/'):
try:
# 基于当前文件夹节点创建多层文件夹
os.makedirs(os.path.join(target_path, recode(file_or_path)))
except FileExistsError:
# 若已存在则跳过创建过程
pass
# 否则视作文件进行写出
else:
# 利用shutil.copyfileobj,从压缩包io流中提取目标文件内容写出到目标路径
with open(os.path.join(target_path, recode(file_or_path)), 'wb') as z:
# 这里基于Zipfile.open()提取文件内容时需要使用原始的乱码文件名
shutil.copyfileobj(src_zip_file.open(file_or_path), z)
# 向已存在的指定文件夹完整解压当前读入的zip文件
zip_extract_all(file, '解压测试')
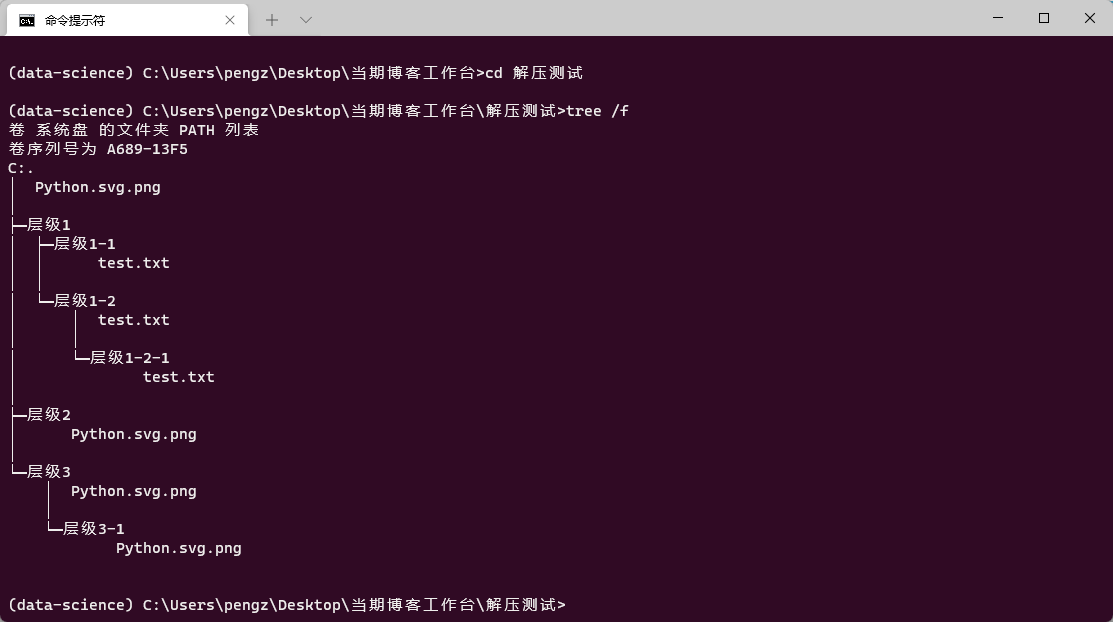
可以看到,效果完美:
本期分享结束,咱们下回见~
「Python实用秘技01」复杂zip文件的解压的更多相关文章
- 「Python实用秘技04」为pdf文件批量添加文字水印
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第4期 ...
- 「Python实用秘技02」给Python函数定“闹钟”
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第2期 ...
- 「Python实用秘技03」导出项目的极简环境依赖
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第3期 ...
- 「Python实用秘技05」在Python中妙用短路机制
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第5期 ...
- 「Python实用秘技06」逐行监听Python程序的内存消耗
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第6期 ...
- 「Python实用秘技07」pandas中鲜为人知的隐藏排序技巧
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第7期 ...
- 「Python实用秘技08」一行代码解析地址信息
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第8期 ...
- 「Python实用秘技09」更好用的函数运算缓存
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第9期 ...
- 「Python实用秘技10」深度比较Python对象间差异
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第10 ...
随机推荐
- jsonpath解析淘票票,所有购票的城市
解决一些反爬,校验. 复制所有请求头 import urllib.request # 请求url url = 'https://dianying.taobao.com/cityAction.json? ...
- Spring Boot核心注解
(1)@SpringBootApplication 代表SpringBoot的启动类 (2)@SpringBootConfiguration 通过bean对象来获取配置信息 (3)@Configura ...
- [atARC075F]Mirrored
假设$n=\sum_{i=0}^{k}a_{i}10^{i}$(其中$a_{k}>0$),则有$d=f(n)-n=\sum_{i=0}^{k}(10^{k-i}-10^{i})a_{i}$,考虑 ...
- 『与善仁』Appium基础 — 12、Appium的安装详解
目录 (一)Appium server安装 方式一:(桌面方式:推荐) 1.Appium Desktop下载 2.Appium Desktop安装 3.Appium Desktop使用 方式二:(No ...
- Codeforces 878D - Magic Breeding(bitset,思维题)
题面传送门 很容易发现一件事情,那就是数组的每一位都是独立的,但由于这题数组长度 \(n\) 很大,我们不能每次修改都枚举每一位更新其对答案的贡献,这样复杂度必炸无疑.但是这题有个显然的突破口,那就是 ...
- Codeforces 1010F - Tree(分治 NTT+树剖)
Codeforces 题面传送门 & 洛谷题面传送门 神仙题. 首先我们考虑按照这题的套路,记 \(t_i\) 表示 \(i\) 上的果子数量减去其儿子果子数量之和,那么对于一个合法的放置果子 ...
- Anaconda 安装与卸载
Anaconda是一个免费开源的Python和R语言的发行版本,用于计算科学(数据科学.机器学习.大数据处理和预测分析),Anaconda致力于简化软件包管理系统和部署.Anaconda的包使用软件包 ...
- Boussinesq 近似及静压假定,内外模分离方法(附录A)
0.Formulation of the RANS equations [1] 不可压缩流体控制方程 \[\begin{array}{l l} \frac{\partial u}{\partial x ...
- plyr包使用
#-------------------------------- # plyr包使用# 建议直接保存为R文件到Rstudio中运行 #-------------------------------- ...
- Browse Code Answers
一个记录各种语言可能遇到的问题的论坛 :https://www.codegrepper.com/code-examples/