HDFS的操作SHELL和API
HDFS的shell操作和JavaAPI的使用:
WEB
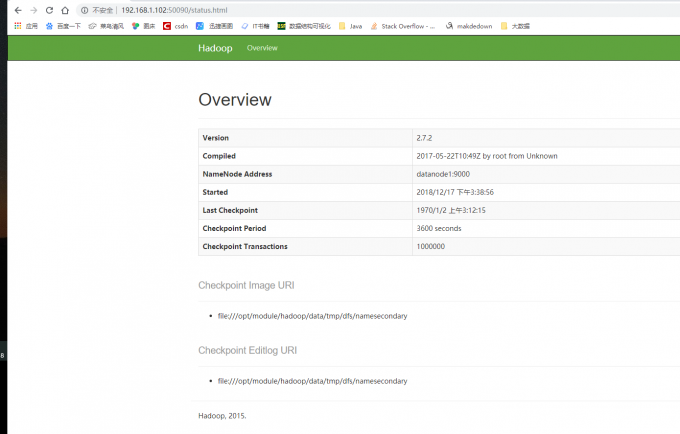
WEB端口50090查看SecondaryNameNode信息。可以查看Hadoop的版本,NameNode的IP,Checkpoint等信息。
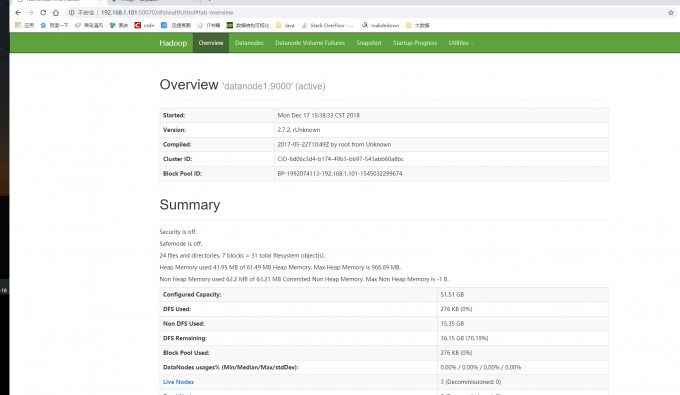
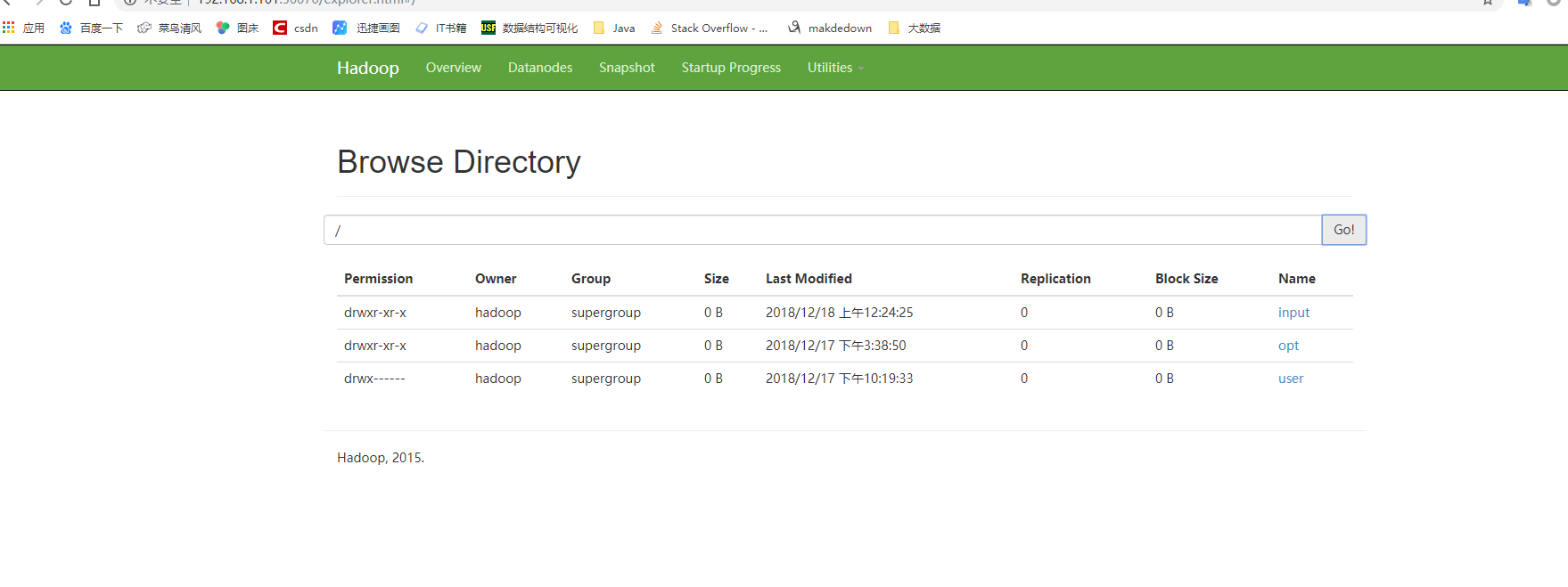
WEB端口50070可以查看HDFS的信息和目录结构
SHELL
查看
hdfs dfs -ls [-d][-h][-R] <paths>
[-d]:返回path
[-h]:按照KMG数据大小单位显示文件大小,默认B
[-R]:级联显示paths下文件
创建文件夹
hdfs dfs -mkdir [-p]<paths>
新建文件
hdfs dfs -touchz<paths>
查看文件
hdfs dfs -cat/[-ignoreCrc] [src]
hdfs dfs -text -ignoreCrc /input/test #忽略校验
hdfs dfs -cat -ignoreCrc /input/test
追写文件
hdfs dfs --appendToFile <localsrc> <dst>
如果localsrc为"-"表示数据来自键盘输入用"Ctrc+C"取消输入
上传下载
hdfs dfs -put [-f][-p]<localsrc> <dst> # 上传到指定目录
hdfs dfs -get [-p]<src> <localhost> # 现在到本地
删除文件
hdfs dfs -rm [-f] [-r] <src>
-f 如果要删除的文件不存在,不显示错误信息
-r/R 级联删除目录下所有文件和子目录文件
磁盘空间
hdfs dfs -du[-s][-h]<path>
[-s]显示指定目录所占空间大小
[-h]按照K M G 数据显示文件大小
JAVA API
步骤
- 实例化Configuration
Configuration封装了客户端或服务器的配置,Confiuration实例会自动加载HDFS的配置文件core-site.xml,从中获取Hadoop集群中的配置信息。因此我们要把集群的配置core-site.xml放在Maven项目的resources目录下。
Configuration conf = new Configuration();
- 实例化FileSystem
FileSystem类是客户端访问文件系统的入口,是一个抽象的文件系统。DistributedFileSystem类是FileSystem的一个具体实现。实例化FileSystem并发挥默认的文件系统代码如下:
FileSystem fs = FileSystem.get(conf);
- 设置目标对象的路径
HDFS API 提供了Path类来封装文件路径。PATH类位于org.apache.hadoop.fs.Path包中,代码如下:
Path path = new Path("/input/write.txt");
执行文件操作
得到Filesystem实例后,就可以使用该实例提供的方法成员执行相应的操作。如果:打开文件,创建文件、重命名文件、删除文件。
FileSystem类常用成员函数
| 方法名称及参数 | 返回值 | 功能 |
|---|---|---|
| create(Path f) | FSDataOutputStream | 创建一个文件 |
| open(Path f) | FSDatatInputStream | 打开指定的文件 |
| delete(Path f) | boolean | 删除指定文件 |
| exsits(Path f) | boolean | 检查文件是否存在 |
| getBlockSize(Path f) | long | 返回指定的数据块的大小 |
| getLength(Path f) | long | 返回文件长度 |
| mkdir(Path f) | boolean | 检查文件是否存在 |
| copyFromLocalFile(Path src, Path dst) | void | 从本地磁盘复制文件到HDFS |
| copyToLocalFile(Path src, Path dst) | void | 从HDFS复制文件到本地磁盘 |
| ……….. | ………. | ……………. |
上传文件
package hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.net.URI; public class PutFile {
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"),conf,"hadoop"); //本地文件
Path src = new Path("D:\\上传文件.txt"); //HDFS 路径
Path dst = new Path("/input/上传文件.txt"); fs.copyFromLocalFile(src, dst);
fs.close();
System.out.println("文件上传成功");
}
}
创建文件
package hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.net.URI; public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop");
Path dfs = new Path("/input/上传文件.txt");
FSDataOutputStream newFile = fs.create(dfs, true); //是否覆盖文件 true 覆盖 false 追加
newFile.writeBytes("this is a create file tes");
System.out.println("创建文件成功"); }
}
文件详情
package hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.Date; public class SeeInfo {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop"); // HDFS文件
Path fpath = new Path("/input/上传文件.txt"); FileStatus fileLinkStatus = fs.getFileLinkStatus(fpath);
//获得块大小
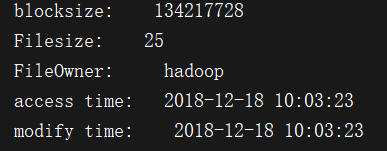
long blockSize = fileLinkStatus.getBlockSize();
System.out.println("blocksize: " + blockSize); //获得文件大小
long len = fileLinkStatus.getLen();
System.out.println("Filesize: " + len); //获得文件所有者
String owner = fileLinkStatus.getOwner();
System.out.println("FileOwner: " + owner); //获得创建时间
SimpleDateFormat formater = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
long accessTime = fileLinkStatus.getAccessTime();
System.out.println("access time: " + formater.format(new Date(accessTime))); //获得修改时间
long modificationTime = fileLinkStatus.getModificationTime();
System.out.println("modify time: " + formater.format(new Date(modificationTime))); }
}
下载文件
package hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI; public class GetFIle {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop");
// HDFS 文件
InputStream in = fs.open(new Path("/input/上传文件.txt")); //保存到本地位置
OutputStream out = new FileOutputStream("D://下载文件.txt");
IOUtils.copyBytes(in, out, 4096, true); System.out.println("下载文件成功");
fs.close(); }
}
删除文件
package hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import java.net.URI; public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop"); Path path = new Path("/input/上传文件.txt");
fs.delete(path);
System.out.println("删除成功");
}
}
HDFS的操作SHELL和API的更多相关文章
- HDFS的基本shell操作,hadoop fs操作命令
(1)分布式文件系统 随着数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管 ...
- JAVA API 实现hdfs文件操作
java api 实现hdfs 文件操作会出现错误提示: Permission denied: user=hp, access=WRITE, inode="/":hdfs:supe ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs简单的shell命令
实验目的 了解bin/hadoop脚本的原理 学会使用fs shell脚本进行基本操作 学习使用hadoop shell进行简单的统计计算 实验原理 1.hadoop的shell脚本 当hadoop集 ...
- HDFS简单介绍及用C语言訪问HDFS接口操作实践
一.概述 近年来,大数据技术如火如荼,怎样存储海量数据也成了当今的热点和难点问题,而HDFS分布式文件系统作为Hadoop项目的分布式存储基础,也为HBASE提供数据持久化功能,它在大数据项目中有很广 ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- hadoop的hdfs文件操作实现上传文件到hdfs
这篇文章主要介绍了使用hadoop的API对HDFS上的文件访问,其中包括上传文件到HDFS上.从HDFS上下载文件和删除HDFS上的文件,需要的朋友可以参考下hdfs文件操作操作示例,包括上传文件到 ...
- Hadoop---Java-API对HDFS的操作
Java-API对HDFS的操作 哈哈哈哈,深夜来一波干货哦!!! Java-PAI对hdfs的操作,首先我们建一个maven项目,我主要说,我们可以通过Java代码来对HDFS的具体信息的打印,然后 ...
- Hadoop JAVA HDFS客户端操作
JAVA HDFS客户端操作 通过API操作HDFS org.apache.logging.log4jlog4j-core2.8.2org.apache.hadoophadoop-common${ha ...
- 通过流的方式操作hadoop的API
通过流的方式操作hadoop的API 功能: 可以直接用来操作hadoop的文件系统 可以用在mapreduce的outputformat中设置RecordWrite 参考: 概念理解 http:// ...
随机推荐
- jsp与servlet的区别与联系
jsp和servlet的区别和联系:1.jsp经编译后就变成了Servlet.(JSP的本质就是Servlet,JVM只能识别java的类,不能识别JSP的代码,Web容器将JSP的代码编译成JVM能 ...
- Python正则表达式学习记录
常用的命令: http://www.runoob.com/python/python-reg-expressions.html 使用中相关注意问题: 1. 中括号里的表示从N到M需要用横线‘-’, 而 ...
- mysql 严格模式 Strict Mode说明(转)
转自https://www.cnblogs.com/jhcelue/p/7290243.html 1.开启与关闭Strict Mode方法 找到mysql安装文件夹下的my.cnf(windows系统 ...
- egg 官方文档之:框架扩展(Application、Context、Request、Response、Helper的访问方式及扩展)
地址:https://eggjs.org/zh-cn/basics/extend.html Application app 对象指的是 Koa 的全局应用对象,全局只有一个,在应用启动时被创建. 访问 ...
- 简单的user-based协同过滤算法示例代码
#构造一份打分数据集1 users = {"小明": {"中国合伙人": 5.0, "太平轮": 3.0, "荒野猎人" ...
- 【python】多线程详解
一.进程与线程关系 一个进程至少包含一个线程. 二.线程基础 1.线程的状态 线程有5种状态,状态转换的过程如下图所示: 2.线程同步(锁) 多线程的优势在于可以同时运行多个任务(至少感觉起来是这样) ...
- @media 响应式布局
能根据宽 高 屏幕等一些标签的变化来应用不同的样式叫响应式,如: <!DOCTYPE html> <html lang="en"> <head> ...
- Python 简说 list,tuple,dict,set
python 是按缩进来识别代码块的 . 缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误. list 有序集合 访问不 ...
- 接口文档管理系统mindoc安装手册
硬件: centos6.9-64 mysql5.6 首先确保系统安装gcc套件 yum -y gcc 第一步,安装mysql(如果不会在Linux安装mysql,请看下面文章) http://www. ...
- 峰Redis学习(1)Redis简介和安装
是从博客:http://blog.java1234.com/blog/articles/310.html参考过来的: 第一节:Redis 简介 为什么需要NoSQL,主要应对以下问题,传统关系型数据库 ...