算法学习记录-图——最小生成树之prim算法
一个连通图的生成树是一个极小的连通子图,它包含图中全部的顶点(n个顶点),但只有n-1条边。
最小生成树:构造连通网的最小代价(最小权值)生成树。
prim算法在严蔚敏树上有解释,但是都是数学语言,很深奥。
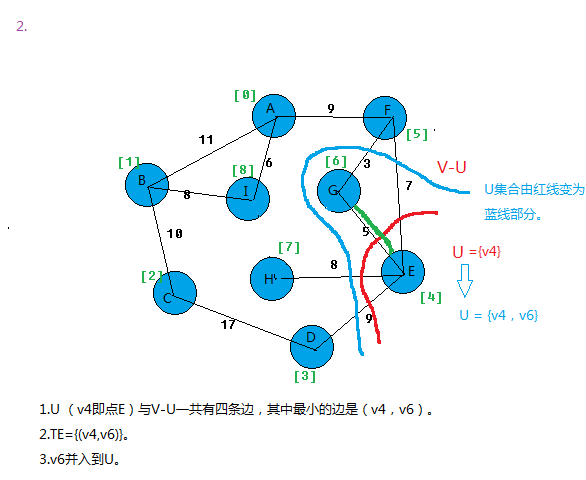
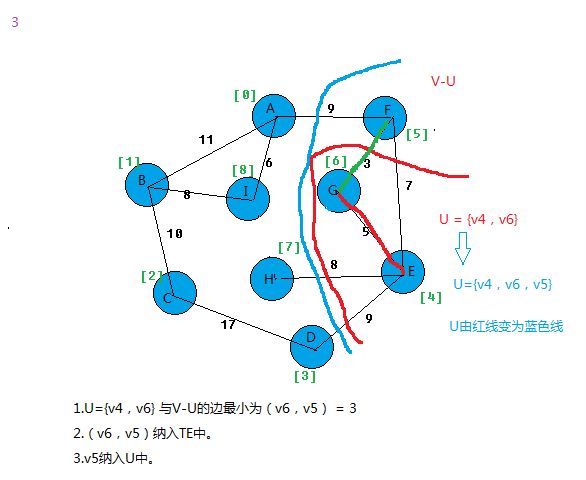
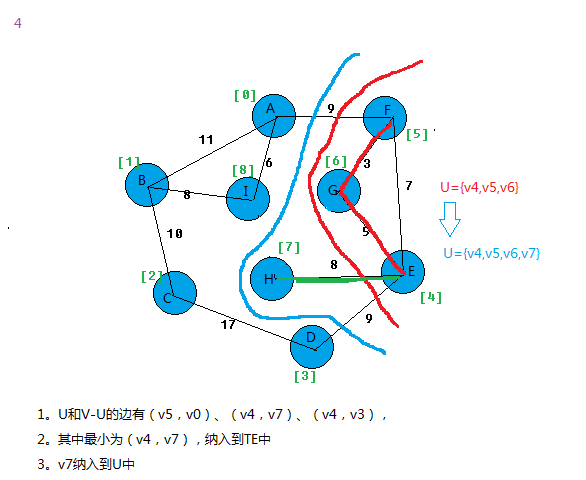
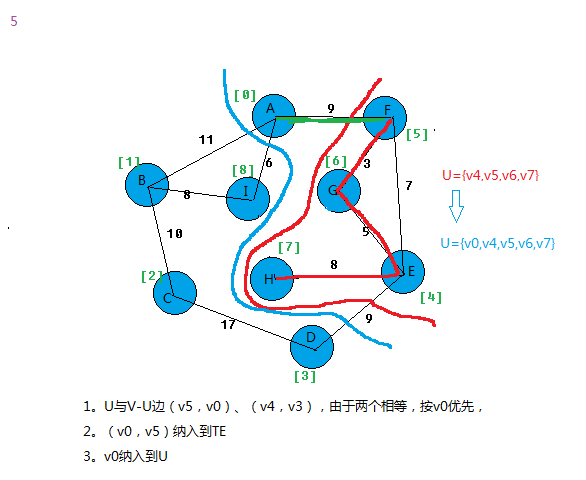
最小生成树MST性质:假设N=(V,{E})是一个连通网,U是顶点集V的一个非空子集。若(u,v)是一条具有最小权值(代价)的边,
其中u∈U,v∈V-U,则必存在一颗包含边(u,v)的最小生成树。
prim算法过程为:
假设N=(V,{E})是连通图,TE是N上最小生成树中边的集合。算法从U={u0}(u0∈V),TE={}开始,
重复执行下述操作:
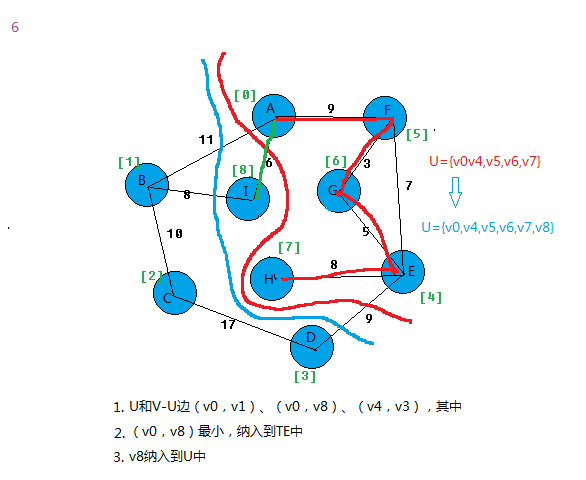
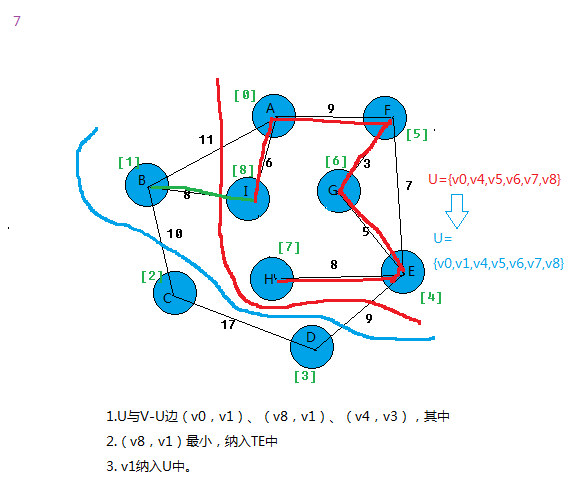
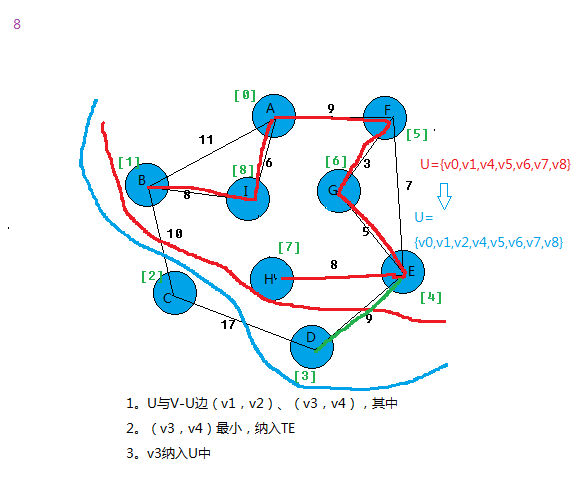
在所有u∈U,v∈V-U的边(u,v)∈E中找一条代价最小的边(u0,v0)并入集合TE,同时v0 并入U,直至U=V为止。
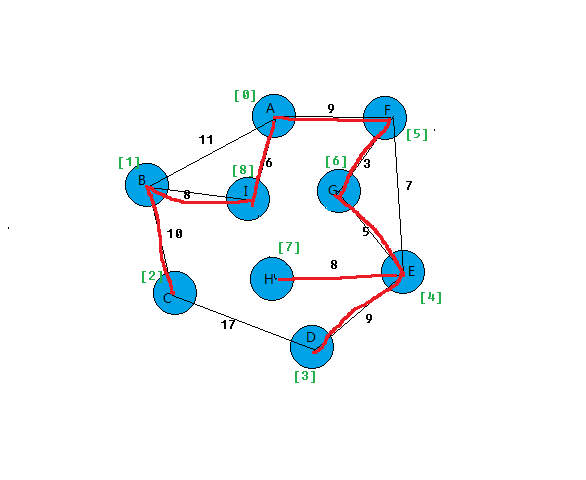
此时TE中必有n-1条边,则T=(V,{TE})为N的最小生成树。
我以图为例,看看算法过程。


上面基本就把prim算法思想给表达出来。
代码部分:
这里我使用的是邻接矩阵来表示图,其中边的值就是权值。
#define MAXVEX 100
#define IFY 65535 typedef char VertexType;
typedef int EdgeType;
//静态图-邻接矩阵
typedef struct {
VertexType vexs[MAXVEX];
EdgeType Mat[MAXVEX][MAXVEX];
int numVexs,numEdges;
}MGraph;
VertexType g_init_vexs[MAXVEX] = {'A','B','C','D','E','F','G','H','I'};
EdgeType g_init_edges[MAXVEX][MAXVEX] = {
{,,IFY,IFY,IFY,,IFY,IFY,}, //'A'
{,,,IFY,IFY,IFY,IFY,IFY,}, //'B'
{IFY,,,,IFY,IFY,IFY,IFY,IFY},//'C'
{IFY,IFY,,,,IFY,IFY,IFY,IFY},//'D'
{IFY,IFY,IFY,,,,,,IFY}, //'E'
{,IFY,IFY,IFY,,,,IFY,IFY}, //'F'
{IFY,IFY,IFY,IFY,,,,IFY,IFY}, //'G'
{IFY,IFY,IFY,IFY,,IFY,IFY,,IFY}, //'H'
{,,IFY,IFY,IFY,IFY,IFY,IFY,}, //'I'
};
prim算法代码:
void prim(MGraph G,int num)
{
int sum=;
int min,i,j,k;
int adjvex[MAXVEX];
int lowcost[MAXVEX]; lowcost[num] = ;
adjvex[num] = ; for (i = ; i < G.numVexs;i++ )
{
if (num == i)
{
continue;
}
lowcost[i]=G.Mat[num][i]; //存放起始顶点到各个顶点的权值。
adjvex[i] = num;
} for (i=;i<G.numVexs;i++)
{
//1.找权最短路径
//2.把权最短路径的顶点纳入已找到的顶点集合中,重新查看新集合中最短路径
if(num == i)
{
continue;
}
min = IFY;
j=;k=;
while (j<G.numVexs)
{
if (lowcost[j] != && lowcost[j] < min)
{
min = lowcost[j];
k = j; }
j++;
}
printf(" (%d,%d) --> ",adjvex[k],k);
sum += G.Mat[adjvex[k]][k];
lowcost[k]=;
for (j=;j<G.numVexs;j++)
{
if (j == num)
{
continue;
}
if (lowcost[j] != && G.Mat[k][j] < lowcost[j])
{
lowcost[j] = G.Mat[k][j];
adjvex[j]=k;
}
}
}
printf("\ntotal:sum=%d",sum);
}
我写的是一个可以指定入口的(即从哪个点)开始进行。测试每个入口,得到的路径应该是一样,且值也应该一样大。
其中两个辅助数组:
lowcost[]:用来存放 非U集合的点与U集合点的权值的最小值。其【x】里面的数字x,表示U中到V中顶点Vx的最小权值。(每次都会更新比较,保证其最小。)
而归入到U集合的点,对应的lowcost中的元素是为0;之后就不再做比较。
adjvex[]:在每次归入新顶点后,都要对U与非U集合中权值比较,保持lowcost中的值为最小。此时改变的lowcost中的某个元素(即新纳入的顶点到非U集合的权值更小)
此时,将改变的lowcost中序号x,将新纳入的顶点Vt与原先U集合中与之相连的点的序号存入adjvex【x】。这样 adjvex【x】中,x就是那些个要更新的
lowcost【x】,adjvex【x】存放就是原先点。
这也方便查找新加入的边(adjvex【k】,k)。

基本上可以看出,adjvex【】作用:
实质上lowcost[x] 是 边(x,adjvex[x])的权值。明白这一点,程序就非常好理解了。
完整程序:
// grp-mat-bfs-self.cpp : 定义控制台应用程序的入口点。
// #include "stdafx.h"
#include <stdlib.h> #define MAXVEX 100
#define IFY 65535 typedef char VertexType;
typedef int EdgeType; bool g_visited[MAXVEX]; VertexType g_init_vexs[MAXVEX] = {'A','B','C','D','E','F','G','H','I'}; EdgeType g_init_edges[MAXVEX][MAXVEX] = {
{,,IFY,IFY,IFY,,IFY,IFY,}, //'A'
{,,,IFY,IFY,IFY,IFY,IFY,}, //'B'
{IFY,,,,IFY,IFY,IFY,IFY,IFY},//'C'
{IFY,IFY,,,,IFY,IFY,IFY,IFY},//'D'
{IFY,IFY,IFY,,,,,,IFY}, //'E'
{,IFY,IFY,IFY,,,,IFY,IFY}, //'F'
{IFY,IFY,IFY,IFY,,,,IFY,IFY}, //'G'
{IFY,IFY,IFY,IFY,,IFY,IFY,,IFY}, //'H'
{,,IFY,IFY,IFY,IFY,IFY,IFY,}, //'I'
}; EdgeType g_init_edges_bak[MAXVEX][MAXVEX] = {
{,,IFY,IFY,IFY,,IFY,IFY,}, //'A'
{,,,IFY,IFY,IFY,IFY,IFY,}, //'B'
{IFY,,,,IFY,IFY,IFY,IFY,IFY},//'C'
{IFY,IFY,,,,IFY,IFY,IFY,IFY},//'D'
{IFY,IFY,IFY,,,,,,IFY}, //'E'
{,IFY,IFY,IFY,,,,IFY,IFY}, //'F'
{IFY,IFY,IFY,IFY,,,,IFY,IFY}, //'G'
{IFY,IFY,IFY,IFY,,IFY,IFY,,IFY}, //'H'
{,,IFY,IFY,IFY,IFY,IFY,IFY,}, //'I'
};
//==========================================================================
//静态图-邻接矩阵
typedef struct {
VertexType vexs[MAXVEX];
EdgeType Mat[MAXVEX][MAXVEX];
int numVexs,numEdges;
}MGraph; //====================================================================
//打印矩阵
void prt_maxtix(EdgeType *p,int vexs)
{
int i,j;
for (i=;i<vexs;i++)
{
printf("\t");
for (j=;j<vexs;j++)
{
if( (*(p + MAXVEX*i + j)) == IFY)
{
printf(" $ ");
}
else
{
printf(" %2d ", *(p + MAXVEX*i + j));
}
}
printf("\n");
}
} //check the number of vextex
int getVexNum(VertexType *vexs)
{
VertexType *pos = vexs;
int cnt=;
while(*pos <= 'Z' && *pos >= 'A')
{
cnt++;
pos++;
}
return cnt;
} bool checkMat(EdgeType *p,VertexType numvex)
{
int i,j;
for (i=;i<numvex;i++)
{
for(j=i+;j<numvex;j++)
{
//printf("[%d][%d] = %d\t",i,j,*(p + MAXVEX*i + j));
//printf("[%d][%d] = %d\n",j,i,*(p + MAXVEX*j + i));
if (*(p + MAXVEX*i + j) != *(p + MAXVEX*j +i) )
{
printf("ERROR:Mat[%d][%d] or Mat[%d][%d] not equal!\n",i,j,j,i);
return false;
}
}
}
return true;
} void init_Grp(MGraph *g,VertexType *v,EdgeType *p)
{
int i,j;
// init vex num
(*g).numVexs = getVexNum(v); //init vexter
for (i=;i<(*g).numVexs;i++)
{
(*g).vexs[i]=*v;
v++;
} //init Mat
for (i=;i<(*g).numVexs;i++)
{
for (j=;j<(*g).numVexs;j++)
{
(*g).Mat[i][j] = *(p + MAXVEX*i + j);
}
}
if(checkMat(&((*g).Mat[][]),(*g).numVexs) == false)
{
printf("init error!\n");
exit();
}
} void prim(MGraph G,int num)
{
int sum=;
int min,i,j,k;
int adjvex[MAXVEX];
int lowcost[MAXVEX]; lowcost[num] = ;
adjvex[num] = ; for (i = ; i < G.numVexs;i++ )
{
if (num == i)
{
continue;
}
lowcost[i]=G.Mat[num][i]; //存放起始顶点到各个顶点的权值。
adjvex[i] = num;
} for (i=;i<G.numVexs;i++)
{
//1.找权最短路径
//2.把权最短路径的顶点纳入已找到的顶点集合中,重新查看新集合中最短路径
if(num == i)
{
continue;
}
min = IFY;
j=;k=;
while (j<G.numVexs)
{
if (lowcost[j] != && lowcost[j] < min)
{
min = lowcost[j];
k = j; }
j++;
}
printf(" (%d,%d) --> ",adjvex[k],k);
sum += G.Mat[adjvex[k]][k];
lowcost[k]=;
for (j=;j<G.numVexs;j++)
{ if (lowcost[j] != && G.Mat[k][j] < lowcost[j])
{
lowcost[j] = G.Mat[k][j];
adjvex[j]=k;
}
} }
printf("total:sum=%d\n",sum);
} int _tmain(int argc, _TCHAR* argv[])
{
MGraph grp;
//init
init_Grp(&grp,g_init_vexs,&g_init_edges[][]);
//print Matix
prt_maxtix(&grp.Mat[][],grp.numVexs); //prim(grp,4);
int i;
for (i=;i<grp.numVexs;i++)
{
prim(grp,i);
}
//prim(grp,3); getchar();
return ;
}
测试结果:

最小生成树一样,而且总权值也一样。
算法学习记录-图——最小生成树之prim算法的更多相关文章
- 算法学习记录-图——最小生成树之Kruskal算法
之前的Prim算法是基于顶点查找的算法,而Kruskal则是从边入手. 通俗的讲:就是希望通过 边的权值大小 来寻找最小生成树.(所有的边称为边集合,最小生成树形成的过程中的顶点集合称为W) 选取边集 ...
- 算法学习记录-图——最短路径之Dijkstra算法
在网图中,最短路径的概论: 两顶点之间经过的边上权值之和最少的路径,并且我们称路径上的第一个顶点是源点,最后一个顶点是终点. 维基百科上面的解释: 这个算法是通过为每个顶点 v 保留目前为止所找到的从 ...
- 算法学习记录-图(DFS BFS)
图: 目录: 1.概念 2.邻接矩阵(结构,深度/广度优先遍历) 3.邻接表(结构,深度/广度优先遍历) 图的基本概念: 数据元素:顶点 1.有穷非空(必须有顶点) 2.顶点之间为边(可空) 无向图: ...
- 算法学习记录-图——应用之关键路径(Critical Path)
之前我们介绍过,在一个工程中我们关心两个问题: (1)工程是否顺利进行 (2)整个工程最短时间. 之前我们优先关心的是顶点(AOV),同样我们也可以优先关心边(同理有AOE).(Activity On ...
- 算法学习记录-图——最小路径之Floyd算法
floyd算法: 解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包. 设为从到的只以集合中的节点为中间节点的最短路径的长度. 若最短路径经过 ...
- 算法学习记录-图——应用之拓扑排序(Topological Sort)
这一篇写有向无环图及其它的应用: 清楚概念: 有向无环图(DAG):一个无环的有向图.通俗的讲就是从一个点沿着有向边出发,无论怎么遍历都不会回到出发点上. 有向无环图是描述一项工程或者系统的进行过程的 ...
- C++编程练习(10)----“图的最小生成树“(Prim算法、Kruskal算法)
1.Prim 算法 以某顶点为起点,逐步找各顶点上最小权值的边来构建最小生成树. 2.Kruskal 算法 直接寻找最小权值的边来构建最小生成树. 比较: Kruskal 算法主要是针对边来展开,边数 ...
- 最小生成树的Prim算法
构造最小生成树的Prim算法 假设G=(V,E)为一连通网,其中V为网中所有顶点的集合,E为网中所有带权边的集合.设置两个新的集合U和T,其中集合U用于存放G的最小生成树的顶点,集合T用于 ...
- 数据结构与算法--最小生成树之Prim算法
数据结构与算法--最小生成树之Prim算法 加权图是一种为每条边关联一个权值或称为成本的图模型.所谓生成树,是某图的一棵含有全部n个顶点的无环连通子图,它有n - 1条边.最小生成树(MST)是加权图 ...
随机推荐
- Glide加载图片的事例
//获取图片的url String url = resultsEntity.getUrl(); //判断获取的图片是否存在 if (resultsEntity.getItemHeight() > ...
- cucumber 背景和场景的区别
背景是公用的,每个场景都会执行,相当于前提条件: 场景是一个单独的case 别人的cucumber学习总结: 链接:http://ruby-china.org/topics/7119
- 剑指tomcat之多项目部署问题
部署项目时遇到的问题,tomcat的webapps文件夹中有两个war包,但每次启动Tomcat服务时,只会默认启动一个war包. 解决方案一:在Tomcat主页中进入应用管理页面,手动开启项目.(进 ...
- I/O————File对象
File文件对象 文件和文件夹都是用File代表 创建一个文件对象,(并不会有真正的文件或文件夹被创建) File f1 = new File("d:/lolfilder"); S ...
- 如何让局域网其他计算机访问您的Mysql???
一.配置Mysql:(修改mysql数据库中user表) mysql -u root -p // root用户登录mysql>use mysql; // 选择mysql数据库 mysql> ...
- IOS之UI异步刷新
NSOperationQueue *operationQueue; // for rendering pages on second thread [operationQueue waitUn ...
- office word excel等图标显示异常
1.查看注册表:查看参数对应的路径被删除,计算机搜索新的文件路径更改路径即可.以此类推~ 计算机\HKEY_CLASSES_ROOT\Excel.Sheet.12\DefaultIcon 正常exce ...
- 使用JavaScript调用手机平台上的原生API
我之前曾经写过一篇文章使用Cordova将您的前端JavaScript应用打包成手机原生应用,介绍了如何使用Cordova框架将您的用JavaScript和HTML开发的前端应用打包成某个手机平台(比 ...
- SQLite基础教程目录
SQLite基础教程目录 SQLite主页 SQLite概述 SQLite -安装 SQLite -命令 SQLite -语法 SQLite -数据类型 SQLite -创建数据库 SQLite -附 ...
- access处理重复创建表的方法。
第一种,使用MSysObjects表查找表名为当前创建表的名字的内容,相当于普通查询,但是access数据库有一个安全问题,就是有时候一开始是没有权限去调这些系统表的,这时可以再2007的access ...