Lucene系列-facet--转
https://blog.csdn.net/whuqin/article/details/42524825
1.facet的直观认识
facet:面、切面、方面。个人理解就是维度,在满足query的前提下,观察结果在各维度上的分布(一个维度下各子类的数目)。
如jd上搜“手机”,得到4009个商品。其中品牌、网络、价格就是商品的维度(facet),点击某个品牌或者网络,获取更细分的结果。

点击品牌小米,获得小米手机的结果,显示27个。
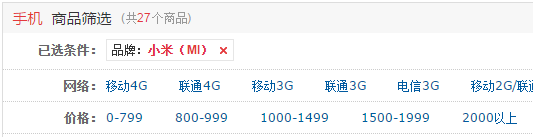
点击移动4G,获得移动4G、小米手机,显示4个。
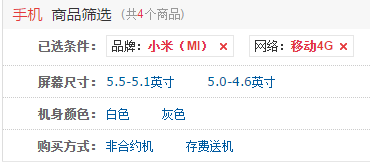
2.facet特性
facet counting:返回一个facet下某子类的结果数。如上面的品牌维度下小米子类中满足查询"手机"的结果有27个。
facet associations:一个文档与某子类的关联度,如一本书30%讲lucene,70%讲solor,这个百分比就是书与分类的关联度(匹配度、信心度)。
multiple facet requests:支持多facet查询(多维度查询)。如查询品牌为小米、网络为移动4G的手机。
3.实例
一个facet简单使用例子,依赖于lucene-facet-4.10.0。讲述了从搜手机到品牌、到网络向下browser的过程。
public class SimpleFacetsExample {
private final Directory indexDir = new RAMDirectory();
private final Directory taxoDir = new RAMDirectory();
private final FacetsConfig config = new FacetsConfig();
/** Empty constructor */
public SimpleFacetsExample() {
config.setHierarchical("Publish Date", true);
}
/** Build the example index. */
private void index() throws IOException {
IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig(Version.LUCENE_4_10_0,
new WhitespaceAnalyzer()));
// Writes facet ords to a separate directory from the main index
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir);
Document doc = new Document();
doc.add(new TextField("device", "手机", Field.Store.YES));
doc.add(new TextField("name", "米1", Field.Store.YES));
doc.add(new FacetField("brand", "小米"));
doc.add(new FacetField("network", "移动4G"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new TextField("device", "手机", Field.Store.YES));
doc.add(new TextField("name", "米4", Field.Store.YES));
doc.add(new FacetField("brand", "小米"));
doc.add(new FacetField("network", "联通4G"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new TextField("device", "手机", Field.Store.YES));
doc.add(new TextField("name", "荣耀6", Field.Store.YES));
doc.add(new FacetField("brand", "华为"));
doc.add(new FacetField("network", "移动4G"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new TextField("device", "电视", Field.Store.YES));
doc.add(new TextField("name", "小米电视2", Field.Store.YES));
doc.add(new FacetField("brand", "小米"));
indexWriter.addDocument(config.build(taxoWriter, doc));
taxoWriter.close();
indexWriter.close();
}
private void facetsWithSearch() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
//1.查询手机
System.out.println("-----手机-----");
TermQuery query = new TermQuery(new Term("device", "手机"));
FacetsCollector.search(searcher, query, 10, fc);
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
List<FacetResult> results = facets.getAllDims(10);
//手机总共有3个,品牌维度:小米2个,华为1个;网络维度:移动4G 2个,联通4G 1个
for (FacetResult tmp : results) {
System.out.println(tmp);
}
//2.drill down,品牌选小米
System.out.println("-----小米手机-----");
DrillDownQuery drillDownQuery = new DrillDownQuery(config, query);
drillDownQuery.add("brand", "小米");
FacetsCollector fc1 = new FacetsCollector();//要new新collector,否则会累加
FacetsCollector.search(searcher, drillDownQuery, 10, fc1);
facets = new FastTaxonomyFacetCounts(taxoReader, config, fc1);
results = facets.getAllDims(10);
//获得小米手机的分布,总数2个,网络:移动4G 1个,联通4G 1个
for (FacetResult tmp : results) {
System.out.println(tmp);
}
//3.drill down,小米移动4G手机
System.out.println("-----移动4G小米手机-----");
drillDownQuery.add("network", "移动4G");
FacetsCollector fc2 = new FacetsCollector();
FacetsCollector.search(searcher, drillDownQuery, 10, fc2);
facets = new FastTaxonomyFacetCounts(taxoReader, config, fc2);
results = facets.getAllDims(10);
for (FacetResult tmp : results) {
System.out.println(tmp);
}
//4.drill sideways,横向浏览
//如果已经进入了小米手机,但是还想看到其他牌子(华为)的手机数目,就用到了sideways
System.out.println("-----小米手机drill sideways-----");
DrillSideways ds = new DrillSideways(searcher, config, taxoReader);
DrillDownQuery drillDownQuery1 = new DrillDownQuery(config, query);
drillDownQuery1.add("brand", "小米");
DrillSidewaysResult result = ds.search(drillDownQuery1, 10);
results = result.facets.getAllDims(10);
for (FacetResult tmp : results) {
System.out.println(tmp);
}
indexReader.close();
taxoReader.close();
}
/** Runs the search and drill-down examples and prints the results. */
public static void main(String[] args) throws Exception {
SimpleFacetsExample example = new SimpleFacetsExample();
example.index();
example.facetsWithSearch();
}
}
输出:
-----手机-----
//总数3个,2个子类
dim=brand path=[] value=3 childCount=2
小米 (2)
华为 (1)
dim=network path=[] value=3 childCount=2
移动4G (2)
联通4G (1)
-----小米手机-----
//普通向下浏览,丢失了同一维度,其他子类的统计
dim=brand path=[] value=2 childCount=1
小米 (2)
dim=network path=[] value=2 childCount=2
移动4G (1)
联通4G (1)
-----移动4G小米手机-----
dim=brand path=[] value=1 childCount=1
小米 (1)
dim=network path=[] value=1 childCount=1
移动4G (1)
-----小米手机drill sideways-----
//drill sideways, 保留了该drill维度的其他子类统计
dim=brand path=[] value=3 childCount=2
小米 (2)
华为 (1)
//小米手机中的网络分布
dim=network path=[] value=2 childCount=2
移动4G (1)
联通4G (1)
Lucene系列-facet--转的更多相关文章
- Lucene系列-facet
1.facet的直观认识 facet:面.切面.方面.个人理解就是维度,在满足query的前提下,观察结果在各维度上的分布(一个维度下各子类的数目). 如jd上搜“手机”,得到4009个商品.其中品牌 ...
- Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
一.Lucene介绍 1. Lucene简介 最受欢迎的java开源全文搜索引擎开发工具包.提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言).Lucene的目的是为软件开发人 ...
- lucene中facet实现统计分析的思路——本质上和word count计数无异,像splunk这种层层聚合(先filed1统计,再field2统计,最后field3统计)lucene是排序实现
http://stackoverflow.com/questions/185697/the-most-efficient-way-to-find-top-k-frequent-words-in-a-b ...
- Lucene系列-FieldCache
域缓存,加载所有文档中某个特定域的值到内存,便于随机存取该域值. 用途及使用场景 当用户需要访问各文档中某个域的值时,IndexSearcher.doc(docId)获得Document的所有域值,但 ...
- [lucene系列笔记1]lucene6的安装与配置(Windows系统)
lucene是一个java开源的高效全文检索工具包,最近做项目要用到,把学习的过程记录一下. 第一步:下载安装jdk 1.首先从官网下载jdk(下载之前先查看你的电脑是多少位操作系统,如果是32就下载 ...
- Lucene系列-索引文件
本文介绍下lucene生成的索引有哪些文件组成,每个文件包含了什么信息.基于Lucene 4.10.0. 数据结构 索引(index)包含了存储的文档(document)正排.倒排信息,用于文本搜索. ...
- Lucene系列-近实时搜索(1)
近实时搜索(near-real-time)可以搜索IndexWriter还未commit的内容,介于immediate和eventual之间,在数据比较大.更新较频繁的情况下使用.本文主要来介绍下如何 ...
- Lucene系列-搜索
Lucene搜索的时候就要构造查询语句,本篇就介绍下各种Query.IndexSearcher是搜索主类,提供的常用查询接口有: TopDocs search(Query query, int n); ...
- Lucene系列-分析器
分析器介绍 搜索的基础是对文本信息进行分析,Lucene的分析工具在org.apache.lucene.analysis包中.分析器负责对文本进行分词.语言处理得到词条,建索引和搜索的时候都需要用到分 ...
随机推荐
- Html隐藏占空间与隐藏不占空间
隐藏不占用空间: display:none; 以下为示例代码: <span style="display:none;"> 获取中</span> 隐藏占用空间 ...
- Python学习-1.安装Python
到Python的官方网站 https://www.python.org/downloads/ 下载官方的安装包 https://www.python.org/ftp/python/3.4.1/pyth ...
- [JS] Ajax请求会话过期处理
对于页面来说,处理session过期比较简单,一般只需在过滤器里面判断session用户是否存在,不存在则跳转页面到登陆页即可. 对于Ajax请求来说,这个办法则无效,只能获取到登录页的html代码. ...
- JWT+ASP.NET MVC 时间戳防止重放攻击
时间戳作用 客户端在向服务端接口进行请求,如果请求信息进行了加密处理,被第三方截取到请求包,可以使用该请求包进行重复请求操作.如果服务端不进行防重放攻击,就会服务器压力增大,而使用时间戳的方式可以解 ...
- Python 第三方包上传至 PyPI 服务器
PyPI 服务器主要功能是?PyPI 服务器怎么搭建? PyPI 服务器可以用来管理自己开发的 Python 第三包. Pypi服务器搭建 Python 第三方包在本地打包 # 本地目录执行以下命令应 ...
- mybatis3.4与spring3.2.5整合出现的问题
错误信息: Exception in thread "main" java.lang.AbstractMethodError: org.mybatis.spring.transac ...
- 配置阿里云ESC服务器部署项目
第一次SSH登录 ECS 服务器: 打开命令行终端(git),键入: > ssh root@39.108.54.110 输入实例密码,进入服务器环境. 配置 root 及应用账号权限 新增管理员 ...
- LoadLinked/StoreConditional (LL/SC)
MIPS中LL/SC指令介绍 MIPS32中的LL.SC指令说明 理解MIPS指令集中的ll (load linked) 和 sc 你用ll指令读取一个内存中的数据并存到一个寄存器,然后在寄存器修改( ...
- 【xsy1156】 树套树(tree) 倍增
题目大意:给你$m$棵由$n$个点构成的全等的树$A$.这$m$棵树之间有$m-1$条边相连,组成了一棵大树. 有$q$组询问,每次询问这棵大树上两点之间的距离. $n,m,q≤10^5$ 这是一道小 ...
- POJ 1125
#include<iostream> #include<stdio.h> #define MAXN 102 #define inf 100000000 using namesp ...