进阶2:Hadoop 环境搭建: hadoop3.1.1 jdk1.8 在centos6.5上的伪分布式安装
参考文章:
https://blog.csdn.net/qq_38038143/article/details/82779016
https://blog.csdn.net/m0_37461645/article/details/84111375
1. 安装包准备
hadoop3.1 : https://pan.baidu.com/s/1VBivgUyyjmS5ysLOiVC1Og 密码:xxo6
jdk1.8 : https://pan.baidu.com/s/142vome8m8BfsE6aF6OMZyA 密码: jg1l
在主机端下载后,通过WinSCP软件将两个安装包传输到Redhat上。如图:

2. 安装jdk
命令:
rpm -ivh jdk-8u51-linux-x64.rpm
安装完成后,执行命令如下:
rpm -qa | grep jdk
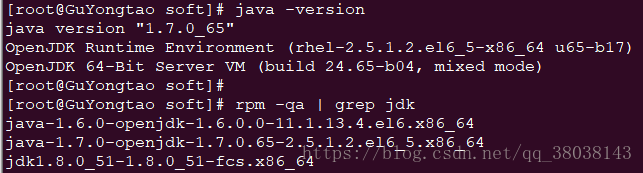
发现,java的版本仍然为1.7.0_65。rpm命令查询,系统默认已安装了jdk1.6和1.7。则依次卸载1.6和1.7:
命令:
rpm -e java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
rpm -e java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
并且修改/etc/profile文件,在文件末尾添加:
export JAVA_HOME=/usr/java/jdk1.8.0_51
执行命令,使/etc/profile文件立即生效:
命令:
source /etc/profile
再次查看java版本,安装成功

3. 设置免密登录
依次执行命令:
ssh-keygen -t rsa
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
chmod 600 authorized_keys
执行ssh localhost查看系统是否能够免密登录。
4. hadoop安装
解压hadoop-3.1.1:
tar -zxvf hadoop-3.1.1.tar.gz
移动压缩后的文件,并修改名称:
mv hadoop-3.1.1 /usr/local/hadoop
编辑hadoop 版本文件
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在该文件hadoop-env.sh末尾加入:
export JAVA_HOME=/usr/java/jdk1.8.0_51
执行命令查看版本:
cd /usr/local/hadoop/
./bin/hadoop version

配置文件:
修改文件~/.bashrc,在文件末尾加入:
export JAVA_HOME=/usr/java/jdk1.8.0_51
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
5. 伪分布式搭建
5.1 hadoop配置
5.1.1 在 /usr/local/hadoop/ 创建目录:

5.1.2 修改配置文件:
进入路径:
修改以下文件内容:
- vim core-site.xml
注:将下列所有配置文件的yue修改为自己centOS的主机名(如下面代码第9行,修改为hdfs://你的主机名:9000)
在<configuration中加入以下内容,:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>注释</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://yue:9000</value>
</property>
</configuration>
2.vim hdfs-site.xml
在<configuration中加入以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
</configuration>
- vim mapred-site.xml
在<configuration中加入以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>yue:9001</value>
</property>
</configuration>
4. vim yarn-site.xml
在<configuration中加入以下内容:
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>yue:8099</value>
</property>
</configuration>
6. 报错处理(可以跳过此步骤,直接进入8. hadoop启动)
由于启动过程发生报错,作出以下修改:
进入路径:
[root@master sbin]# pwd
/usr/local/hadoop/sbin
1.修改start-dfs.sh,stop-dfs.sh
在这两个文件的头部加入:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2.修改start-yarn.sh,stop-yarn.sh
在这两个文件的头部加入:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3. 修改文件:
vim /usr/local/hadoop/etc/hadoop/log4j.properties
4.在文件末尾加入:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
5. 如果在启动时报错:could not resolve hostname yue :name or service not know

解决办法:
vi /etc/hosts
注释前面,并新增(IP 主机名):
192.168.57.129 yue

7. hadoop启动(若启动时报错,可以回到6. 报错处理)
修改/etc/profile文件,在文件末尾加入,并执行source /etc/profile:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
格式化namenode节点:
命令:
hdfs namenode -format
效果:

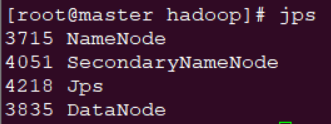
启动:系统能够免密登录后,启动命令(停止命令:stop-all.sh):
- 执行
start-dfs.sh
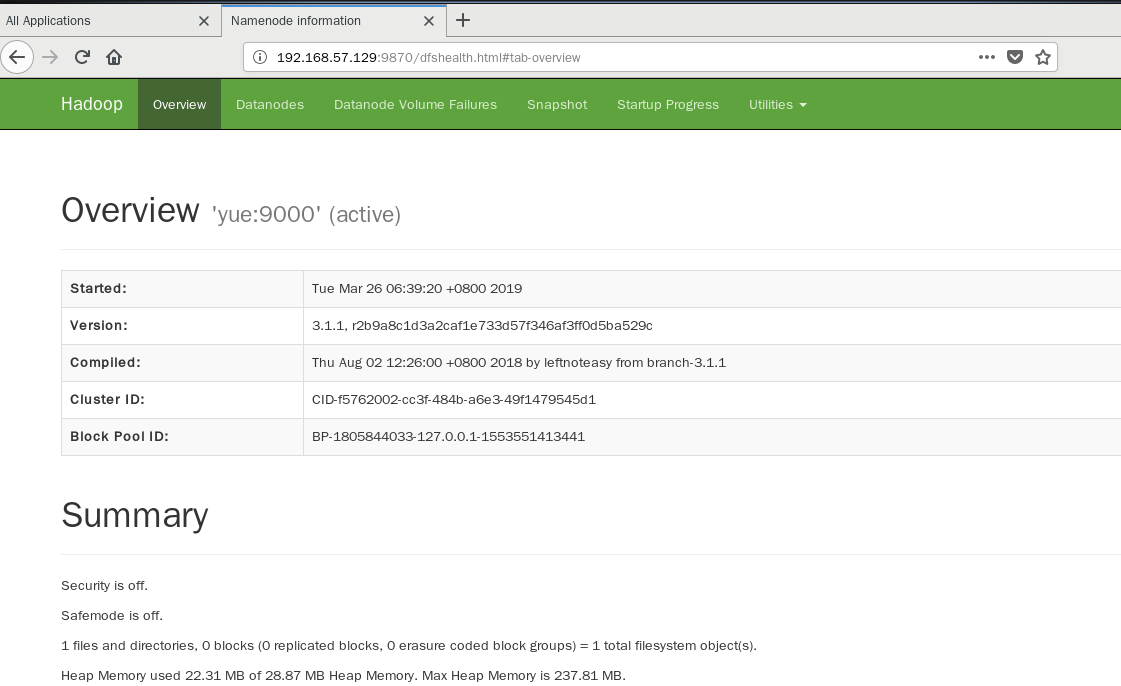
在Linux的浏览器查看(hadoop2.x 端口为:50070,3.1为9870):
可查看 NameNode 和 Datanode 信息,也可以在线查看 HDFS 中的文件
2. 执行
start-yarn.sh
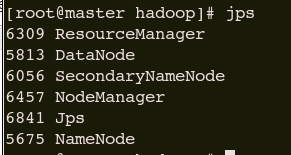
在Linux的浏览器查看,可查看任务运行情况:

配置完成
参考链接:
https://blog.csdn.net/cx105200/article/details/78284761
https://blog.csdn.net/u011762604/article/details/72897000
https://blog.csdn.net/mm_bit/article/details/49474709
https://blog.csdn.net/lglglgl/article/details/80553828
https://blog.csdn.net/l1028386804/article/details/51538611
进阶2:Hadoop 环境搭建: hadoop3.1.1 jdk1.8 在centos6.5上的伪分布式安装的更多相关文章
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- Hadoop环境搭建、启动和管理界面查看
一.hadoop环境搭建: 1. hadoop 6个核心配置文件的作用:core-site.xml:核心配置文件,主要定义了我们文件访问的格式 hdfs://hadoop-env.sh:主要配置我们的 ...
- Ubuntu中Hadoop环境搭建
Ubuntu中Hadoop环境搭建 JDK安装 方法一:通过命令行直接安装(不建议) 有两种java可以安装oracle-java8-installer以及openjdk (1)安装oracle-ja ...
- Linux集群搭建与Hadoop环境搭建
今天是8月19日,距离开学还有15天,假期作业完成还是遥遥无期,看来开学之前的恶补是躲不过了 今天总结一下在Linux环境下安装Hadoop的过程,首先是对Linux环境的配置,设置主机名称,网络设置 ...
- 转 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文:史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末活动哦] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
- Hadoop环境搭建问题总结
最近抽空搭建了Hadoop完全分布式环境,期间遇到了很多问题,大部分问题还是可以在网上搜到的,这里说下自己遇到的两个没有找到结果的问题吧. 1.启动时报:没有那个文件或目录 原因:三台机器的用户名不一 ...
随机推荐
- 20191110 Spring Boot官方文档学习(4.1)
4. Spring Boot功能 4.1.Spring应用 便捷的启动方式: public static void main(String[] args) { SpringApplication.ru ...
- mysql先分组,然后取每个分组中的第2大的记录
文章参考http://www.xaprb.com/blog/2006/12/07/how-to-select-the-firstleastmax-row-per-group-in-sql/ 首先建表: ...
- Mysql-问题解决记录
1.查看当前默认的配置文件位置 # mysqld --verbose --help | 'Default options' Default options are read from the foll ...
- [百家号]APT组织简介2019
5家新APT组织被披露,2019是“后起之秀”的天下? https://baijiahao.baidu.com/s?id=1621699899936470038&wfr=spider& ...
- [19/06/06-星期四] HTML基础_文本标签、列表(有序、无序、定义)、文本格式化(单位、字体、大小写、文本修饰、间距、对齐文本)
一.文本标签 em:用来表示一段内容的着重点,语气上的强调.一般显示为斜体 i:是斜体显示,和em显示效果一样.h5规定不需要着重的内容而是单纯加粗或斜体可以用i或b.用的不多 strong:用来表示 ...
- Boostrap4 li列表橫向
Boostrap3 li元素橫向: <ul class="nav navbar-nav list-inline"> <li class="list-in ...
- PHP_OS的常见值
PHP_OS是PHP中的一个预定义常量,表示当前操作系统.那么PHP_OS有哪些值可用呢??PHP_OS的值一般可以为:CYGWIN_NT-5.1,Darwin,FreeBSD,HP-UX,IRIX6 ...
- CSS样式 换行
强制不换行 div{ white-space:nowrap; } 自动换行 div{ word-wrap: break-word; word-break: normal; } 强制英文单词断行 div ...
- vue创建项目配置脚手架vue-cli环境出错
1.at process._tickCallback (internal/process/next_tick.js:188:7) npm ERR! message: 'request to http ...
- LazyMan的深入解析和实现
一.题目介绍 以下是我copy自网上的面试题原文: 实现一个LazyMan,可以按照以下方式调用: LazyMan("Hank")输出: Hi! This is Hank! L ...