python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作:
python3+pip官方配置
1.Anaconda(推荐,包括python和相关库)
【推荐地址:清华镜像】
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
【安装过程中注意选择自动添加path到环境变量中,未选择需要自己添加】
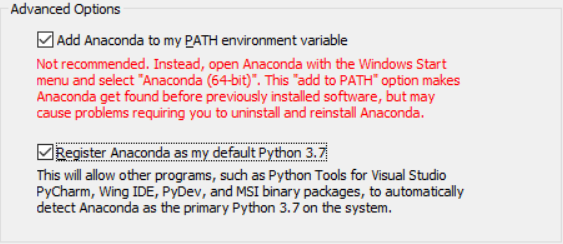
红色提示的意思是:自动添加的环境变量会处于最前面,自动成为默认,可能会使原本使用默认的软件报错,未防止以上问题,可以打开环境变量后,调整顺序将Anaconda相关path移到最后。
【环境变量设置成功】
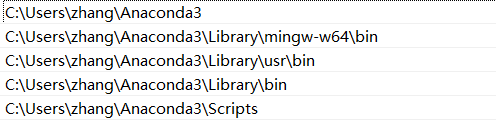
2.官方安装
官方安装指的是只安装python,需要的库通过手动安装,下文会涉及库的安装
【python下载】
官方地址: https://www.python.org/
【自行添加环境变量】

【注】【环境变量如何添加】
我的电脑(右键)---属性---高级系统设置---环境变量-----path----在后面加上分号添加python安装地址及下层scipt(对pip的配置),如上图
3.pycharm安装
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
官方网址:http://www.jetbrains.com/pycharm/download/#section=windows
【注】选择community下载(社区版的功能足够使用)
MongoDB安装配置
1.MongoDB数据库
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
【下载链接(64位)直接点击下载】
https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-4.0.5-signed.msi
2.可视化GUI下载
redis安装配置
1.redis安装
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
【下载链接】
https://github.com/MicrosoftArchive/redis/releases
2.可视化gui下载
https://github.com/uglide/RedisDesktopManager/releases
mysql安装配置
1.官方下载
https://dev.mysql.com/downloads/file/?id=480824
(8.0)
https://dev.mysql.com/downloads/file/?id=481157
(5.7)
【最好选择镜像msi下载安装】
安装包下载后的安装需要通过命令行执行命令,且root初始密码不能自己设置(惨痛的教训。。。没记住密码。。。8.0的改又特别麻烦,试了很多办法后卸载重装。)
【root密码请不要乱设置】
使用msi自行安装设置的root密码不要随便设置
2.可视化GUI
爬虫常用库的安装
1.内置库
在安装python时,会默认安装,一般不需要手动安装。
在使用爬虫时,常用的两个内置库是urllib、re
【如何检查库是否安装】在pycharm中import该库,一般不报错的就是库已经存在
import urllib
import urllib.request
import re
a=urllib.request.urlopen('http://www.baidu.com')#尝试使用urllib库
print(a)
2.第三方
第三方库一般都需要手动安装,爬虫使用的第三方库有下面这几个:
【requests】
如图所示,打开命令行(开始-输入cmd-打开命令行),输入以下代码:
pip3 install requests

【selenium】
打开命令行,输入以下代码:
pip3 install selenium
【phantomjs】(无界面浏览器)
http://phantomjs.org/download.html
# <editor-fold desc="被舍弃的PhantomJS"> from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.baidu.com') # </editor-fold>
【注意】最新的selenium已经不再支持ph
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
【替代】可使用Headless Chrome(需要安装chromedriver)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options chrome_options=Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver=webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.baidu.com/")
【chromedriver】
http://chromedriver.storage.googleapis.com/index.html
【注意】
驱动和chrome浏览器版本一定要匹配
【版本配置查看】最新是2.45而不是2.9
http://chromedriver.storage.googleapis.com/2.45/notes.txt
【lxml】
打开命令行,输入以下代码:
pip3 install lxml
网速慢的请使用下面一个方法
【whl文件安装】
【前提】安装wheel库
pip3 install wheel
【下载whl文件】
https://pypi.org/search/?q=lxml
【安装whl文件参考】
https://blog.csdn.net/weixin_41592575/article/details/78984585
【BeautifulSoup】
网页解析库,依赖lxml(请先安装lxml),安装好lxml后,打开命令行,输入以下代码:
pip3 install BeautifulSoup4
使用示例:
from bs4 import BeautifulSoup
【pyquery】
网页解析库。
打开命令行,输入以下代码:
pip3 install pyquery
使用示例:
from pyquery import PyQuery as pq
doc =pq('<html>hello world</html>')
result = doc('html').text()
print(result)
【pymysql】
打开命令行,输入以下代码:
pip3 install pymysql
使用示例:
import pymysql
conn =pymysql.connect(host='localhost',user='root',password='',port=3306,db='mysql')
cur =conn.cursor()
cur.execute('select * from db')
cur.fetchall()
【pymongo】
打开命令行,输入以下代码:
pip3 install pymongo
使用示例:
import pymongo
client = pymongo.MongoClient('localhost')
db =client['newtestdb']
db['table'].insert({'name':'zhang'})
db['table'].find_one({'name':'zhang'})
【redis】
打开命令行,输入以下代码:
pip3 install redis
使用示例:
import redis
r = redis.Redis('LOCALHOST',6379)
r.set('name','zhang')
r.get('name')
3.外部库
【flask】
打开命令行,输入以下代码:
pip3 install flask
【django——分布式开发】
打开命令行,输入以下代码:
pip3 install django
【jupyter——网页端notebook】
打开命令行,输入以下代码:
pip3 install jupyter
4.多版本python安装包
若电脑存在多个版本的python,可以参考下面的文章安装包
https://blog.csdn.net/qq_36148847/article/details/81189443
5.注意
在命名.py文件时,不要将文件名设置为包(库)名,会导致无法正确的import包(后续会讲到)
python爬虫学习笔记(一)——环境配置(windows系统)的更多相关文章
- Qt5学习笔记(1)-环境配置(win+64bit+VS2013)
Qt5学习笔记(1)-环境配置 工欲善其事必先-不装-所以装软件 久不露面,赶紧打下酱油. 下载 地址:http://download.qt.io/ 这个小网页就可以下载到跟Qt有关的几乎所有大部分东 ...
- WP8 学习笔记(001_环境配置)
Step 1 WP8 的开发要求64位操作系统,Windows 8及以上版本,需要激活版,建议网上买一个注册码.详见安装双系统. Step 2 安装好系统并已经激活之后,需要安装Windows Ph ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- 【lua学习笔记】——环境配置
1 开发平台 windows7 64位 2 下载链接 http://www.lua.org/download.html 3 安装完成-环境配置 4 运行 WIN+R 运行 cmd 运行lua,显示配 ...
- 学习笔记-ionic3 环境配置搭建到打包
折腾了两周总算理清楚了,参考的链接如下: https://blog.csdn.net/zeternityyt/article/details/79655150 环境配置 https://segmen ...
- Python爬虫学习笔记之Centos下安装配置Mongodb3.6
在Centos6.9上安装Mongodb时候,遇到"No package mongodb-org available"这个报错. 经过查询后,在Centos6.9上需要针对Mong ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- tensorflow学习笔记(1)-环境配置
配置环境anaconda3+windows10+pycharm+python==3.5.2+tensorflow==1.1.4+cuda10.0+cudnn7 https://www.anaconda ...
随机推荐
- js 小数取整数
1.丢弃小数部分,保留整数部分 parseInt() 22.127456取成22.13 parseInt(5/2) 2 向上取整,有小数就整数部分加1 Math.ceil(5/2) 3,四舍五入 ...
- 2--TestNG 参数化
(1)XML文件 public class ParameterTest{ @test @Parameters({"name","age"}) public vo ...
- WEB学习笔记13-高可读性的HTML之精简HTML代码/过时的块状元素和行内元素
<a id="more-intro">点击此处 <img src="down-arrow.png" /></a> (1)删除 ...
- hadoop day 7
1.storm概述 应用于实时的流式计算,结合消息队列和数据库进行使用. Spouts:拓扑的消息源 Bolts:拓扑的处理逻辑单元,每个bolt可以在集群当中多实例的并发执行 tuple:消息元组, ...
- 【转载】 什么是AutoML
文章来源:企鹅号 - 仲耀晖的碎碎念 tzattack Studio presents 来源:Google AI Blog 编译:仲耀晖 ------------------------------- ...
- EEG 睡眠 节律 代码
a1=load('EEG01.txt');[c,r]=size(a1);z=10;%等于几,绘图起点从几开始s=256*z;%绘图起点;还有,这里的256是采样率d=floor(c/256);cn=d ...
- redis的LRU算法(二)
前文再续,书接上一回.上次讲到redis的LRU算法,文章实在精妙,最近可能有机会用到其中的技巧,顺便将下半部翻译出来,实现的时候参考下. 搏击俱乐部的第一法则:用裸眼观测你的算法 Redis2.8的 ...
- 采用NoteExpress参考文献导入和导出
1.NoteExpress使用 该软件分为企业版和个人版,但目前看来个人版已经不能用了,我用的是我们学校购买的软件,感觉还是很方便的. (1)首先建立数据库: (2)可以通过导入原文选项将下载好的文章 ...
- Python全栈之路----常用模块----软件开发目录规范
目录基本内容 log #日志目录 conf #配置目录 core/luffycity #程序核心代码目录 #luffycity 是项目名,建议用小写 libs/modules #内置模块 d ...
- Java基于opencv—透视变换矫正图像
很多时候我们拍摄的照片都会产生一点畸变的,就像下面的这张图 虽然不是很明显,但还是有一点畸变的,而我们要做的就是把它变成下面的这张图 效果看起来并不是很好,主要是四个顶点找的不准确,会有一些偏差,而且 ...