python 使用selenium模块爬取同一个url下不同页的内容(浏览器模拟人工翻页)
页面翻页,下一页可能是一个新的url
也有可能是用js进行页面跳转,url不变,解决方法是实现浏览器模拟人工翻页
目标:爬取同一个url下不同页的数据(上述第二种情况)
url:http://www.gx211.com/collegemanage/search.aspx?id=1&xxcity=1
中国高校之窗,我要爬取北京市所有的学校列表,共有四页数据,四页都是同一个url。
部分页面如图:
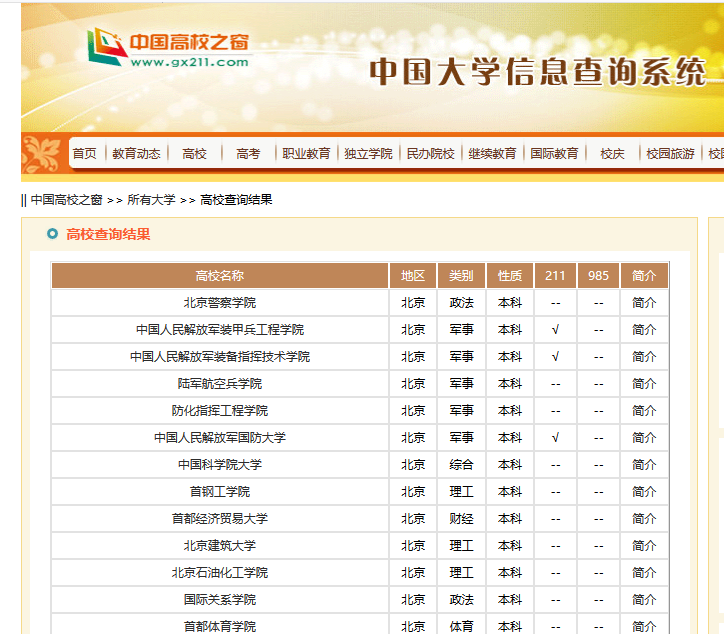
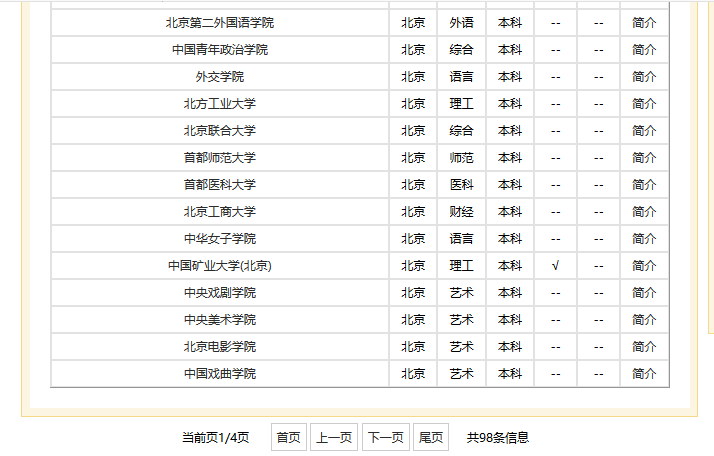
找到“下一页”按钮的源码,确认是用js进行的跳转。

工具:
- selenium
- pyquery
- 火狐浏览器
代码:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from pyquery import PyQuery as pq #
# 爬取北京市所有的学校
# browser = webdriver.Firefox() # 创建一个浏览器对象,这里还可以使用chrome等浏览器
try:
BJuniv = []
browser.get('http://www.gx211.com/collegemanage/search.aspx?id=1&xxcity=1') # 获取并打开url
for r in range(4):
html = browser.page_source # 获取html页面
doc = pq(html) # 解析html
table = doc('.content tbody') # 定位到表格
table.find('script').remove() # 除去script标签 list_cont = table('tr').items() # 获取tr标签列表
for i in list_cont:
univ = (i.text()).split() # 获取每个tr标签中的文本信息,返回一个列表
print(univ)
BJuniv.append(univ)
nextpagebutton = browser.find_element_by_xpath('//*[@id="Lk_Down"]') # 定位到“下一页”按钮
nextpagebutton.click() # 模拟点击下一页
wait = WebDriverWait(browser, 10) # 浏览器等待10s finally:
browser.close() # 关闭浏览器
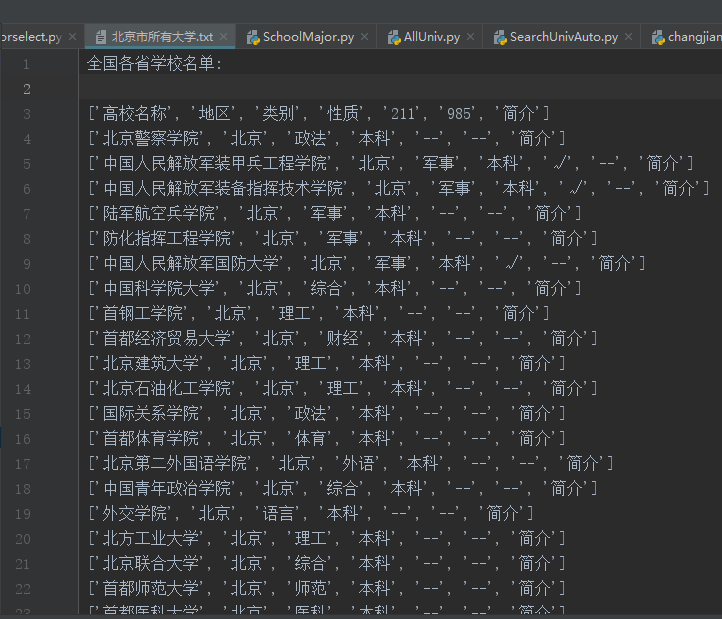
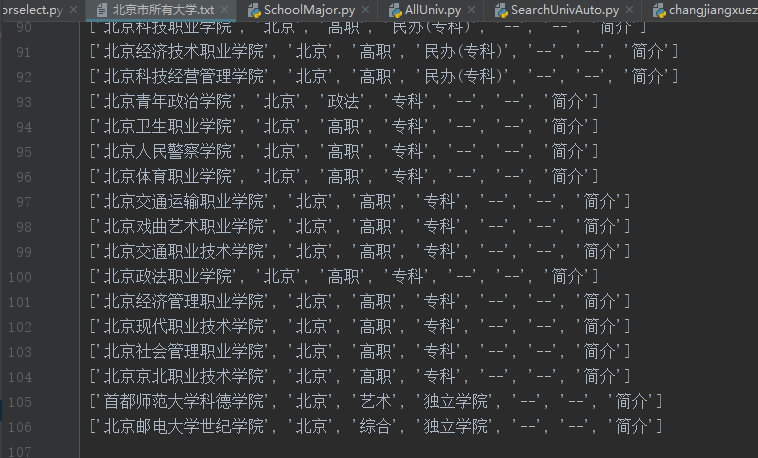
with open("北京市所有大学.txt", "wt", encoding='utf8') as out_file: # 存储为txt格式
out_file.write('全国各省学校名单:\n\n')
for u in BJuniv:
out_file.write(str(u) + '\n')
运行过程:自动打开浏览器,输入url,获取页面,点击下一页,重复直到循环结束。(过程看不到很细致的,跳转比较快)
运行结果(部分):
python 使用selenium模块爬取同一个url下不同页的内容(浏览器模拟人工翻页)的更多相关文章
- [python爬虫] Selenium定向爬取PubMed生物医学摘要信息
本文主要是自己的在线代码笔记.在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容. PubMed是一个免费的搜寻引擎,提供生物医学方 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- [python爬虫] Selenium定向爬取虎扑篮球海量精美图片
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员 ...
- Python爬虫之使用Fiddler+Postman+Python的requests模块爬取各国国旗
介绍 本篇博客将会介绍一个Python爬虫,用来爬取各个国家的国旗,主要的目标是为了展示如何在Python的requests模块中使用POST方法来爬取网页内容. 为了知道POST方法所需要传 ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
- python的requests模块爬取网页内容
注意:处理需要用户名密码认证的网站,需要auth字段. # -*- coding:utf-8 -*- import requests headers = { "User-Agent" ...
- python实例:自动爬取豆瓣读书短评,分析短评内容
思路: 1.打开书本“更多”短评,复制链接 2.脚本分析链接,通过获取短评数,计算出页码数 3.通过页码数,循环爬取当页短评 4.短评写入到txt文本 5.读取txt文本,处理文本,输出出现频率最高的 ...
- [实战演练]python3使用requests模块爬取页面内容
本文摘要: 1.安装pip 2.安装requests模块 3.安装beautifulsoup4 4.requests模块浅析 + 发送请求 + 传递URL参数 + 响应内容 + 获取网页编码 + 获取 ...
- python+selenium+xpath 爬取天眼查工商基本信息
# -*- coding:utf-8 -*-# author: kevin# CreateTime: 2018/8/16# software-version: python 3.7 import ti ...
随机推荐
- zabbix触发器表达式
zabbix触发器表达式 触发器使用逻辑表达式来评估通过item获取的数据是处于哪种状态, 触发器中的表达式使用很灵活,我们可以创建一个复杂的逻辑测试监控,触发器表达式形式如下: {<serve ...
- vue filters中使用data中数据
vue filters中 this指向的不是vue实例,但想要获取vue实例中data中的数据,可以采用下面方法.在 beforeCreate中将vue实例赋值给全局变量app0,然后filters中 ...
- HDU 3085 Nightmare Ⅱ(噩梦 Ⅱ)
HDU 3085 Nightmare Ⅱ(噩梦 Ⅱ) Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Ja ...
- Moqui 代码解释
Service: entity-find 和 entity-find-one 的区别: <entity-find entity-name="" list="&quo ...
- win7 / mysql-8.0.11-winx64 安装的测坑步骤
虚惊一场,主要问题是 Navicat Premium 连接 mysql8 Client does not support authentication . 1. 下载 官网下载压缩包: mysql ...
- Premiere Pro 中的键盘快捷键
官网地址:https://helpx.adobe.com/cn/premiere-pro/using/default-keyboard-shortcuts-cc.html?mv=product& ...
- Linux中的wheel用户组是什么?
在Linux中wheel组就类似于一个管理员的组. 通常在Linux下,即使我们有系统管理员root的权限,也不推荐用root用户登录.一般情况下用普通用户登录就可以了,在需要root权限执行一些操作 ...
- ASP.NET MVC CSRF (XSRF) security
CSRF(Cross-site request forgery)跨站请求伪造,也被称为“One Click Attack”或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站 ...
- fail to resolve com.umeng.analytics:analytics:latest.integration
今天友盟接入的时候,他娘的居然提示我这个友盟jar包拉不下来 明明之前还好好的,而且别的什么东西都没问题,就这个有问题 原来使用的是 compile "com.umeng.analytics ...
- 浅谈前端nuxt(ssr)
SSR: 服务端渲染(Server Side Render),即:网页是通过服务端渲染生成后输出给客户端. 一.那为什么要使用SSR呢? 我用一句话理解的就是降低SPA(Single Page App ...