tensorflow (七) k-means
tensorflow基础暂不介绍
Python 相关库的安装
pip install seaborn
安装 matplotlib:
pip install matplotlib
安装 python3-tk:
sudo apt-get install python3-tk -y
K-Means 聚类算法步简介
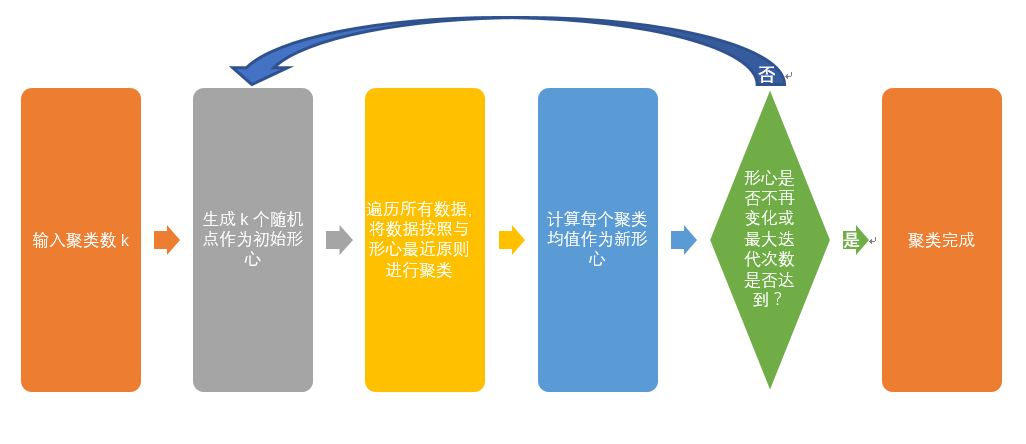
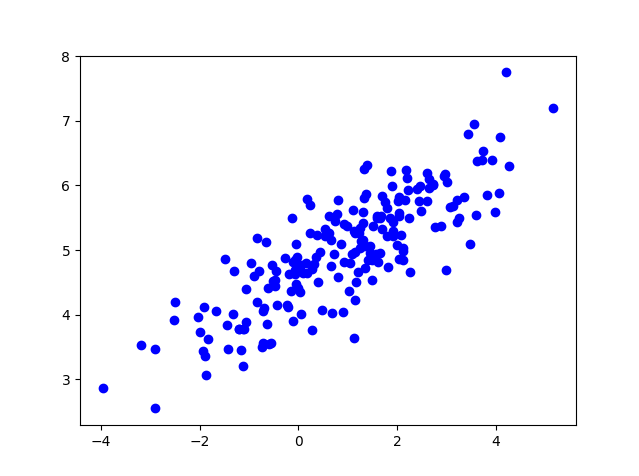
测试数据准备
200个数据进行 K-Means 聚类,首先我们先来了解一些生成的测试数据的形式#-*- coding:utf-8 -*-
# -*- coding: utf-8 -*-
import matplotlib
matplotlib.use('Agg')
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
############生成随机测试数据###############
sampleNo = 200;#生成数据数量
mu =3
# 二维正态分布
mu = np.array([[1, 5]])
Sigma = np.array([[1, 0.5], [1.5, 3]])
R = cholesky(Sigma)
srcdata= np.dot(np.random.randn(sampleNo, 2), R) + mu
plt.plot(srcdata[:,0],srcdata[:,1],'bo')
plt.savefig('data0.png')
K-Means 聚类算法的实现
代码:
# -*- coding: utf-8 -*-
import matplotlib
matplotlib.use('Agg')
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import tensorflow as tf
from random import choice, shuffle
from numpy import array
def KMeansCluster(vectors, noofclusters):
noofclusters = int(noofclusters)
assert noofclusters < len(vectors)
#找出每个向量的维度
dim = len(vectors[0])
#辅助随机地从可得的向量中选取形心
vector_indices = list(range(len(vectors)))
shuffle(vector_indices)
#计算图
graph = tf.Graph()
with graph.as_default():
#计算的会话
sess = tf.Session()
########从现有的点集合中抽取出一部分作为默认的中心点########
centroids = [tf.Variable((vectors[vector_indices[i]]))
for i in range(noofclusters)]
centroid_value = tf.placeholder("float64", [dim])
cent_assigns = []
for centroid in centroids:
cent_assigns.append(tf.assign(centroid, centroid_value))
assignments = [tf.Variable(0) for i in range(len(vectors))]
assignment_value = tf.placeholder("int32")
cluster_assigns = []
for assignment in assignments:
cluster_assigns.append(tf.assign(assignment,
assignment_value))
#############下面创建用于计算平均值的操作节点#############
mean_input = tf.placeholder("float", [None, dim])
mean_op = tf.reduce_mean(mean_input, 0)
#################用于计算欧氏距离的节点#################
v1 = tf.placeholder("float", [dim])
v2 = tf.placeholder("float", [dim])
euclid_dist = tf.sqrt(tf.reduce_sum(tf.pow(tf.subtract(
v1, v2), 2)))
centroid_distances = tf.placeholder("float", [noofclusters])
cluster_assignment = tf.argmin(centroid_distances, 0)
###################初始化所有的状态值###################
init_op = tf.global_variables_initializer()
sess.run(init_op)
#######################集群遍历#######################
#接下来在 K-Means 聚类迭代中使用最大期望算法,简单起见最大迭代次数直接设置为30次
noofiterations = 30
for iteration_n in range(noofiterations): #####################期望步骤#####################
#首先遍历所有的向量
for vector_n in range(len(vectors)):
vect = vectors[vector_n]
#计算给定向量与分配的形心之间的欧氏距离
distances = [sess.run(euclid_dist, feed_dict={
v1: vect, v2: sess.run(centroid)})
for centroid in centroids]
#下面可以使用集群分配操作,将算出的距离当做输入
assignment = sess.run(cluster_assignment, feed_dict = {
centroid_distances: distances})
#接下来为每个向量分配合适的值
sess.run(cluster_assigns[vector_n], feed_dict={
assignment_value: assignment}) ####################最大化的步骤####################
#基于上述的期望步骤,计算每个新的形心的距离从而使集群内的平方和最小
for cluster_n in range(noofclusters):
#收集所有分配给该集群的向量
assigned_vects = [vectors[i] for i in range(len(vectors))
if sess.run(assignments[i]) == cluster_n]
#计算新的集群形心
new_location = sess.run(mean_op, feed_dict={
mean_input: array(assigned_vects)})
#为每个向量分配合适的形心
sess.run(cent_assigns[cluster_n], feed_dict={
centroid_value: new_location}) #返回形心和分组
centroids = sess.run(centroids)
assignments = sess.run(assignments)
return centroids, assignments
############生成随机测试数据###############
sampleNo = 200;#生成数据数量
mu =3
# 数据遵从二维正态分布
mu = np.array([[1, 5]])
Sigma = np.array([[1, 0.5], [1.5, 3]])
R = cholesky(Sigma)
srcdata= np.dot(np.random.randn(sampleNo, 2), R) + mu
plt.plot(srcdata[:,0],srcdata[:,1],'bo')
plt.savefig('data.png')
############ kmeans 算法计算###############
k=4
center,result=KMeansCluster(srcdata,k)
print (center)
############利用 seaborn 画图############### res={"x":[],"y":[],"kmeans_res":[]}
for i in range(len(result)):
res["x"].append(srcdata[i][0])
res["y"].append(srcdata[i][1])
res["kmeans_res"].append(result[i])
pd_res=pd.DataFrame(res)
sns.lmplot("x","y",data=pd_res,fit_reg=False,size=5,hue="kmeans_res")
plt.show()
plt.savefig('kmeans.png')
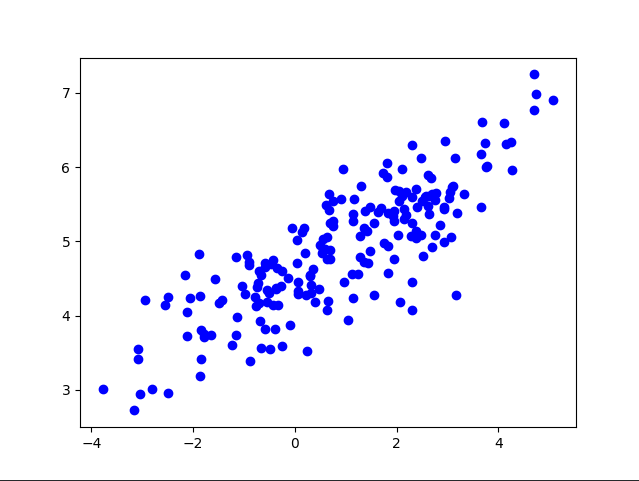


参考:https://codesachin.wordpress.com/2015/11/14/k-means-clustering-with-tensorflow/
tensorflow (七) k-means的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- TensorFlow(七):tensorboard网络执行
# MNIST数据集 手写数字 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # ...
- tensorflow(七)
一.模型托管工具 TensorFlow Serving TensorFlow Serving支持生产级的服务部署,允许用户快速搭建从模型训练到服务发布的工作流水线. 工作流水线主要由三部分构成 (1) ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- TensorFlow 初级教程(三)
TensorFlow基本操作 import os import tensorflow as tf os.environ[' # 使用TensorFlow输出Hello # 创建一个常量操作( Cons ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- TensorFlow(二):基本概念以及练习
一:基本概念 1.使用图(graphs)来表示计算任务 2.在被称之为会话(Session)的上下文(context)中执行图 3.使用tensor表示数据 4.通过变量(Variable)维护状态 ...
随机推荐
- allure --version 异常io.airlift.airline.ParseArgumentsUnexpectedException: Found unexpected parameter
执行allure --version时,有时会出现如下异常: io.airlift.airline.ParseArgumentsUnexpectedException: Found unexpecte ...
- 数据挖掘领域十大经典算法之—SVM算法(超详细附代码)
https://blog.csdn.net/fuqiuai/article/details/79483057
- 查看selenium API
pydoc是Python自带的模块,主要用于从python模块中自动生成文档,这些文档可以基于文本呈现的.也可以生成WEB 页面的,还可以在服务器上以浏览器的方式呈现! 一.pydoc 1.到底什么是 ...
- 【做题】ZJOI2017仙人掌——组合计数
原文链接 https://www.cnblogs.com/cly-none/p/ZJOI2017cactus.html 给出一个\(n\)个点\(m\)条边的无向连通图,求有多少种加边方案,使得加完后 ...
- P4233 射命丸文的笔记
思路 题目要求求的是哈密顿回路的期望数量,实际上就是哈密顿回路的总数/有哈密顿回路的竞赛图的数量 n个点的所有竞赛图中哈密顿回路的总数为 \[ (n-1)! 2^{\frac{n(n-1)}{2}-n ...
- CSS scroll-behavior和JS scrollIntoView让页面滚动平滑
转自 https://www.zhangxinxu.com/wordpress/2018/10/scroll-behavior-scrollintoview-%E5%B9%B3%E6%BB%91%E6 ...
- spring cloud之Feign的使用
原始的调用客户端的方式是通过注入restTemplate的方式 restTemplate.getForObject("http://CLIENT/hello", String.cl ...
- YARN详解
1.1 分布式资源调度框架 1.2.1 yarn的概念 Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协 ...
- JVM垃圾回收(四)- GC算法:实现(1)
GC算法:实现 上面我们介绍了GC算法中的核心概念,接下来我们看一下JVM里的具体实现.首先必须了解的一个重要的事实是:对于大部分的JVM来说,两种不同的GC算法是必须的,一个是清理Young Gen ...
- lua调用不同lua文件中的函数
a.lua和b.lua在同一个目录下 a.lua调用b.lua中的test方法,注意b中test的写法 _M 和 a中调用方法: b.lua local _M = {}function _M.test ...