链路追踪 Sleuth 和 Zipkin
微服务的链路追踪概述:
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
Sleuth概述:
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,只需要在pom文件中引入相应的依赖即可。
它大量借用了Google Dapper的设计。Dapper论文阐述了分布式系统,特别是微服务架构中链路追踪的概念、数据表示、埋点、传递、收集、存储与展示等技术细节。
链路追踪Sleuth入门:
(1) 需要链路追踪的微服务都添加上配置依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
( 2) 修改application.yml添加日志级别
logging:
level:
root: INFO
org.springframework.web.servlet.DispatcherServlet: DEBUG
org.springframework.cloud.sleuth: DEBUG
每个微服务都需要添加如上的配置。启动微服务,调用之后,我们可以在各个微服务的控制台观察到 sleuth 的日志输出

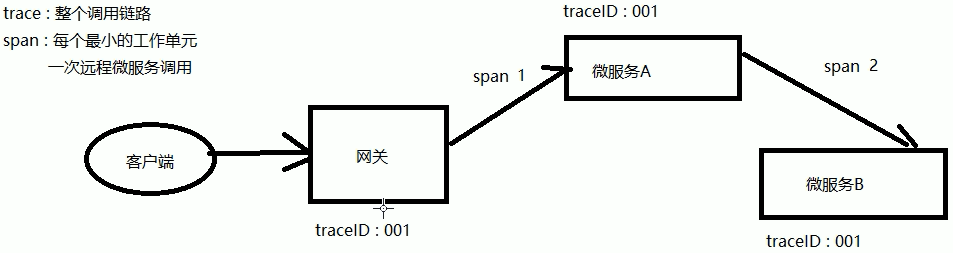
其中 975279e5c6fce4b0 是TraceId,后面跟着的是SpanId,依次调用有一个全局的TraceId,将调用链路串起来。仔细分析每个微服务的日志,不难看出请求的具体过程。
查看日志文件并不是一个很好的方法,当微服务越来越多日志文件也会越来越多,通过Zipkin可以将日志聚合,并进行可视化展示和全文检索。
Zipkin的概述:
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。 我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的 API 接口之外,它也提供了方便的 UI 组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。 Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch。
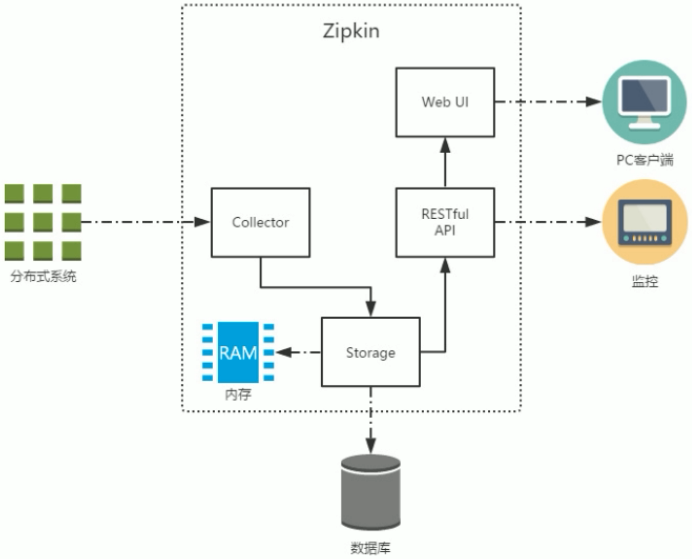
Zipkin 的架构,主要由 4 个核心组件构成:
Collector :收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
Storage :存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
RESTful API :API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
Web UI :UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和分析跟踪信息。
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用。客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。发送的方式主要有两种,一种是 HTTP 报文的方式,还有一种是消息总线的方式如 RabbitMQ。
不论哪种方式,我们都需要:
一个服务注册中心,这里就用之前的 eureka 来当注册中心。
一个 Zipkin 服务端。
多个微服务,这些微服务中配置 Zipkin 客户端。
Zipkin Server的部署和配置:
(1) Zipkin Server下载
从spring boot 2.0开始,官方就不再支持使用自建Zipkin Server的方式进行服务链路追踪,而是直接提供了编译好的 jar 包来给我们使用。可以从官方网站先下载Zipkin的web UI,我们这里下载的是zipkin -server-2.12.9-exec.jar
(2) 启动
在命令行输入 java -jar zipkin-server-2.12.9-exec.jar 启动 Zipkin Server
默认 Zipkin Server的请求端口为 9411
Zipkin Server 的启动参数可以通过官方提供的 yml 配置文件查找
在浏览器输入 http://127.0.0.1:9411 即可进入到 Zipkin Server 的管理后台
客户端Zipkin+Sleuth整合:
通过查看日志分析微服务的调用链路并不是一个很直观的方案,结合zipkin可以很直观地显示微服务之间的调用关系。
(1)客户端添加依赖(客户端指的是需要被追踪的微服务)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
(2)修改客户端配置文件

zipkin:
base-url: http://127.0.0.1:9411/ #zipkin server的地址
sender:
type: web #请求方式,默认以http的方式向zipkin server发送追踪数据,其他取值如 kafka、rabbit
sleuth:
sampler:
probability: 1.0 #采样的百分比,默认为0.1,即10%
#过于频繁的采样会影响系统性能,实际使用这里需要配置一个合适的值。
(3)测试
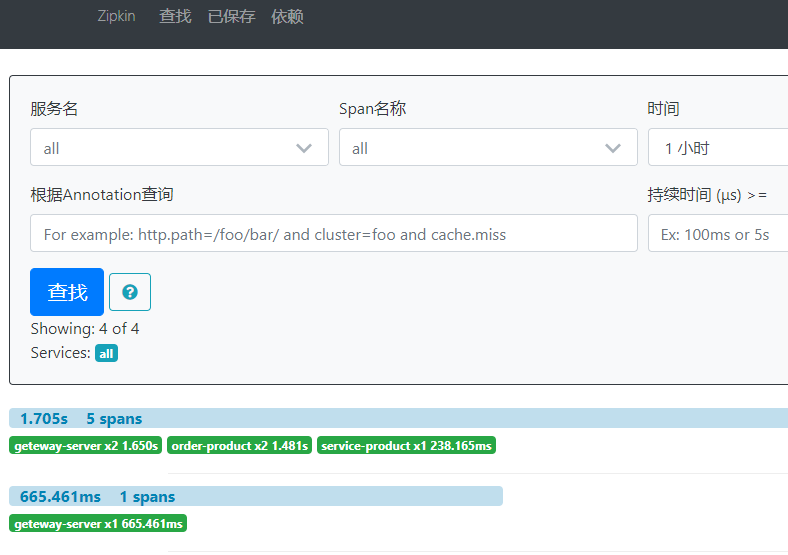
启动每个微服务,通过浏览器发送一次微服务请求。打开 Zipkin Service 控制台,根据条件追踪每次请求调用过程
基于消息中间件收集数据:
在默认情况下,Zipkin客户端和Server之间是使用HTTP请求的方式进行通信(即同步的请求方式),在网络波动,Server端异常等情况下可能存在信息收集不及时的问题。Zipkin支持与rabbitMQ整合完成异步消息传输。
1.RabbitMQ的安装与启动
.......
2.服务端启动:
java -jar zipkin-server-2.12.9-exec.jar --RABBIT_ADDRESSES=127.0.0.1:5672
RABBIT_ADDRESSES : 指定RabbitMQ地址
RABBIT_USER: 用户名(默认guest)
RABBIT_PASSWORD : 密码(默认guest)
启动Zipkin Server之后,我们打开RabbitMQ的控制台可以看到多了一个Queue
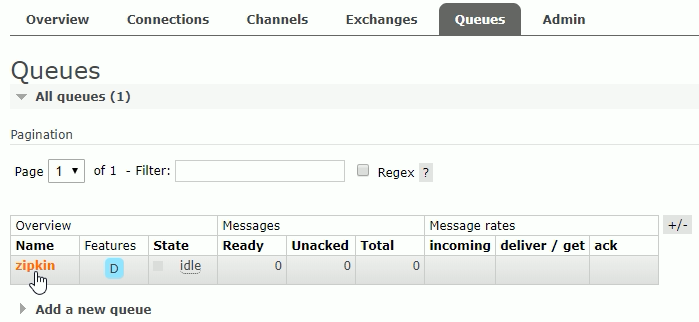
其中 zipkin 就是为我们自动创建的Queue队列
3.客户端配置
(1) 配置依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
(2) 配置消息中间件rabbit mq地址等信息
zipkin:
#base-url: http://127.0.0.1:9411/ #zipkin server的地址
sender:
#type: web #请求方式,默认以http的方式向zipkin server发送追踪数据,其他取值如 kafka、rabbit
type: rabbit
sleuth:
sampler:
probability: 1.0 #采样的百分比,默认为0.1,即10%
#过于频繁的采样会影响系统性能,实际使用这里需要配置一个合适的值。
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener: #配置重试策略
direct:
retry:
enabled: true
simple:
retry:
enabled: true
修改消息的投递方式,改为 rabbit 即可。
添加 rabbitmq 的相关配置
(3) 测试
关闭Zipkin Server,并随意请求连接。打开rabbitmq管理后台可以看到,消息已经推送到rabbitmq。
当Zipkin Server启动时,会自动的从rabbitmq获取消息并消费,展示追踪数据
存储跟踪数据:
Zipkin Server追踪数据信息默认保存到内存,这种方式不适合生产环境。因为一旦Zipkin Service关闭重启或者服务崩溃,就会导致历史数据消失。Zipkin支持将追踪数据持久化到mysql数据库或者存储到elasticsearch中。
1.准备数据库:可以从官网找到Zipkin Server持久mysql的数据库脚本
2.配置启动服务端
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root
STORAGE_TYPE : 存储类型
MYSQL_HOST: mysql主机地址
MYSQL_TCP_PORT:mysql端口
MYSQL_DB: mysql数据库名称
MYSQL_USER:mysql用户名
MYSQL_PASS :mysql密码
链路追踪 Sleuth 和 Zipkin的更多相关文章
- Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] 发表于 2018-04-24 | 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请 ...
- 学习一下 SpringCloud (五)-- 配置中心 Config、消息总线 Bus、链路追踪 Sleuth、配置中心 Nacos
(1) 相关博文地址: 学习一下 SpringCloud (一)-- 从单体架构到微服务架构.代码拆分(maven 聚合): https://www.cnblogs.com/l-y-h/p/14105 ...
- 分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
原创: dqqzj SpringForAll社区 今天 Spring Cloud Sleuth Span是基本的工作单位. 例如,发送 RPC是一个新的跨度,就像向RPC发送响应一样. 跨度由跨度唯一 ...
- 微服务—分布式服务追踪sleuth和zipkin
随着业务的发展,系统规模也会越来越大,各微服务间的调用关系也越来越错综复杂. 通常一个客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果, 在复杂的微服务架构系统中,几乎每 ...
- 【Day02】Spring Cloud组件的使用--Nacos配置中心、sentinel流量控制、服务网关Gateway、RocketMQ、服务调用链路(Sleuth、zipkin)
今日内容 一.配置中心 1.遗留问题 yml配置,每一次都需要重启项目 需要不重启项目拿到更新的结果 引出:配置中心 选择:Spring Cloud Config组件 / Alibaba的Nacos( ...
- 服务链路追踪---Sleuth
Sleuth:日志收集工具包,封装了Dapper和log-based追踪以及Zipkin和HTrace操作,为SpringCloud应用实现了一种分布式追踪解决方案. 当服务与服务之间调用复杂时,Sp ...
- 链路追踪工具之Zipkin学习小记
(接触了Zipkin,权将所了解或理解的记于此,以备忘) 分布式追踪系统 随着业务发展,系统拆分多个微服务.此时对于一个前端请求可能需要调用多个后端端服务才能完成,当整个请求变慢或不可用时,我们是无法 ...
- 带入gRPC:分布式链路追踪 gRPC + Opentracing + Zipkin
在实际应用中,你做了那么多 Server 端,写了 N 个 RPC 方法.想看看方法的指标,却无处下手? 本文将通过 gRPC + Opentracing + Zipkin 搭建一个分布式链路追踪系统 ...
- 基于Dapper的分布式链路追踪入门——Opencensus+Zipkin+Jaeger
微信搜索公众号 「程序员白泽」,进入白泽的编程知识分享星球 最近做了一些分布式链路追踪有关的东西,写篇文章来梳理一下思路,或许可以帮到想入门的同学.下面我将从原理到demo为大家一一进行讲解,欢迎评论 ...
- 十一、springcloud之链路追踪Sleuth
一.背景 随着微服务的数量增长,一个业务接口涉及到多个微服务的交互,在出错的情况下怎么能够快速的定位错误 二.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案, ...
随机推荐
- python翻译词典实例
#!/usr/bin/python # -*- coding:utf-8 -*- #通过有道翻译来进行内容翻译 import urllib2 import urllib import json #-- ...
- 如何在离线的Linux服务器上部署 Ollama,并使用 Ollama 管理运行 Qwen 大模型
手动安装 Ollama 根据Linux的版本下载对应版本的 Ollama, 查看Linux CPU型号,使用下面的命令 #查看Linux版本号 cat /proc/version #查看cpu架构 l ...
- RT-Thread Studio刚新建工程后直接打开main.c编译就board.c里产生报错,解决办法
如题,RT-Thread Studio刚新建工程后直接打开main.c编译就产生报错. 具体为:刚新建了一个stm32F407ZGT6和一个STM32F103RCT6的工程,之后啥代码也没有改,直接打 ...
- js中的数组去重的多种方法
1. indexOf()方法 const arr = [1,2,3,4,5,1,2,3,4,6,1,1,6,6,7,5,8] const newArr = [] arr.forEach(item =& ...
- 推荐一个.NetCore开源的CMS项目,功能强大、扩展性强、支持插件的系统!
推荐一个基于.Net Core开发的开源CMS项目,该项目功能完善.涉及知识点比较多,不管是作为二次开发.还是学习都是不错的选择. 01 项目简介 Cofoundry是基于.Net开发的.代码优先开发 ...
- 【一步步开发AI运动小程序】七、进行运动计时、计数
随着人工智能技术的不断发展,阿里体育等IT大厂,推出的"乐动力"."天天跳绳"AI运动APP,让云上运动会.线上运动会.健身打卡.AI体育指导等概念空前火热.那 ...
- 一个新的音乐管理软件--JxAudio
介绍 JxAudio是一个基于.net core的音频管理系统,支持音乐的播放.上传.下载.删除等功能. 兼容Subsonic协议,可以使用Subsonic客户端进行访问. 支持Windows.Lin ...
- maven 分离打包的技术
1.概要 我们在构建springboot 程序的时候,可以将所有的文件打包成一个大的文件,这个使用起来还是很方便的,但是有些情况下不是很方便,比如 程序需要经常更新的时候,通过网络传输就比较慢,还有比 ...
- px2rem 实现vue rem 自适应/
npm install postcss-px2rem px2rem-loader --save 新建js 文件rem.js // rem等比适配配置文件 // 基准大小 const baseSize ...
- GPUStack v0.4:文生图模型、语音模型、推理引擎版本管理、离线支持和部署本地模型
GPUStack 是一个专为运行 AI 模型设计的开源 GPU 集群管理器,致力于支持基于任何品牌的异构 GPU 构建统一管理的算力集群.无论这些 GPU 运行在 Apple Mac.Windows ...