HashMap知识点
1.基本数据结构
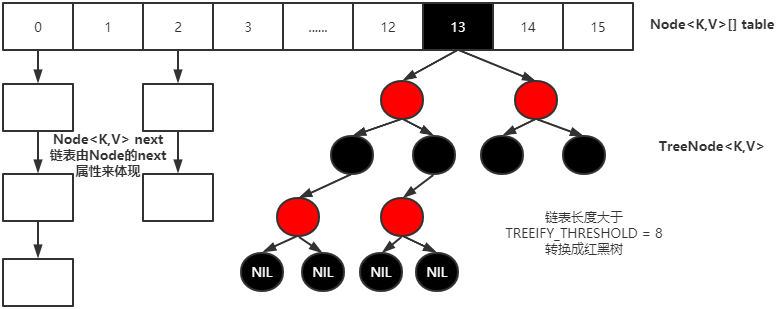
1. JDK1.7 数组 + 链表
2. JDK1.8 数组 + (链表 | 红黑树)
2.树化与退化
1.树化意义
1.红黑树用来避免Dos攻击,防止链表过长时性能下降,树化应该是偶然情况,是保底策略.
2.hash 表的查找,更新的时间复杂度是 O(1),而红黑树的查找,更新的时间复杂度是 O(log2n ),TreeNode 占用空间也比普通 Node 的大,如非必要,尽量还是使用链表
3.hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
2.树化规则
1.当链表长度超过树化阈值8时,先尝试扩容来减少链表长度,如果数组容量已经 >= 64,才会进行树化.
3.退化规则
1. 情况1:在扩容时如果拆分树时,树元素 <= 6 则会退化链表
2. 情况2:在 remove 树节点时若 root 根节点,根节点的左右子节点或者孙节点只要有一个为 null 也会退化为链表.
3.索引计算
1.索引计算方法
1.首先,计算对象的hashCode()
2.再进行调用HashMap的hash()方法进行二次哈希 (二次哈希是为了综合高位数据,让哈希分布更为均匀)
3.最后 哈希结果 & (数组容量 - 1) 得到索引位置
2.数组容量为何是2的 n 次幂
1.计算索引时,如果是2的n次幂可以使用位于运算替代取模,效率更高.
2.扩容时 hash & 旧容量 == 0的元素留在原来位置,否则新位置 = 旧位置 + 旧容量
3.上述都是为了配合容量为2的 n 次幂时的优化手段,例如 HashTable的容量就不是2的 n 次幂,并不能说哪种设计更好.
4. put 与 扩容
1. put 流程
1.HashMap 是懒惰创建数组的,首次使用才创建数组
2.计算索引(桶下标)
3.如果桶下标还没人占用,创建 Node 占位返回
4.如果桶下标已经有人占用
1.已经是 TreeNode 走红黑树的添加或更新逻辑
2.是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
5.返回前检查容量是否超过阈值,一旦超过进行扩容
2. 1.7 与 1.8 的区别
1. 表插入节点时,1.7是头插法,1.8是尾插法
2. 1.7是大于等于阈值且没有空位时才扩容,而1.8是大于阈值就扩容
3. 1.8在扩容计算Node索引时会优化
3. 扩容加载因子 (factor) 为何默认是0.75f
1. 在空间占用和查询时间之间取得比较好的权衡
2. 大于这个值,空间节省了,但是链表就会比较长,影响性能
3. 小于这个值,冲突减少了,但是扩容更频繁,空间占用更多
5.并发问题
1.扩容死链 (1.7会存在)
1.7 源码如下:

void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
e 和 next 都是局部变量,用来指向当前节点和下一个节点
线程1(绿色)的临时变量 e 和 next 刚引用了这俩节点,还未来得及移动节点,发生了线程切换,由线程2(蓝色)完成扩容和迁移
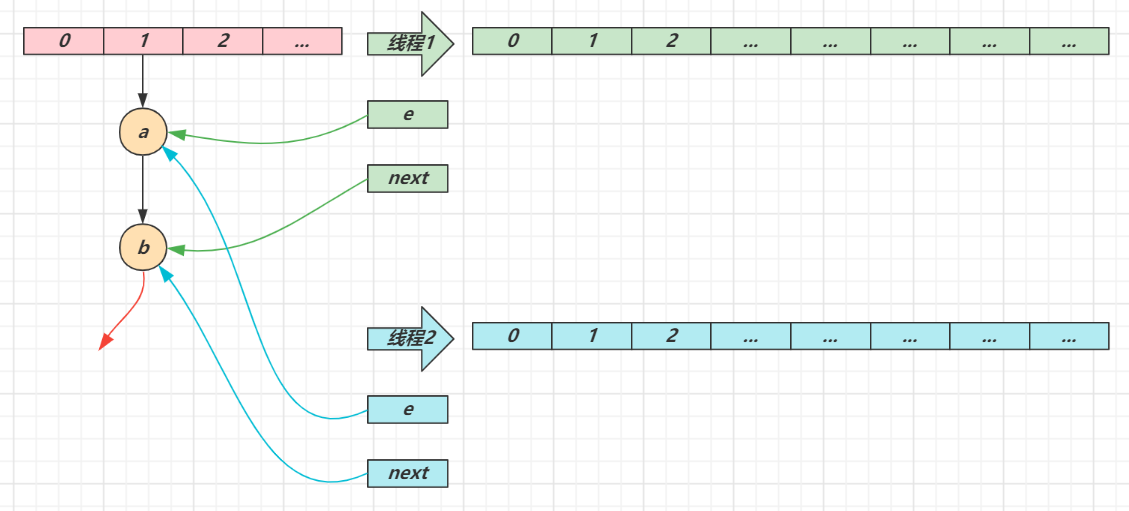
线程2 扩容完成,由于头插法,链表顺序颠倒。但线程1 的临时变量 e 和 next 还引用了这俩节点,还要再来一遍迁移
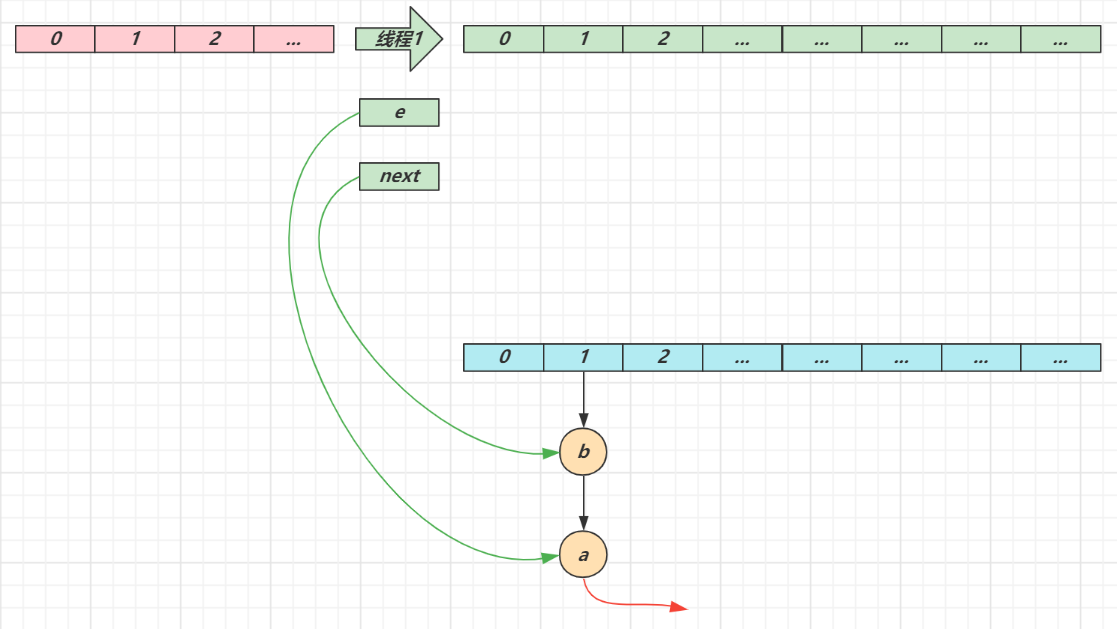
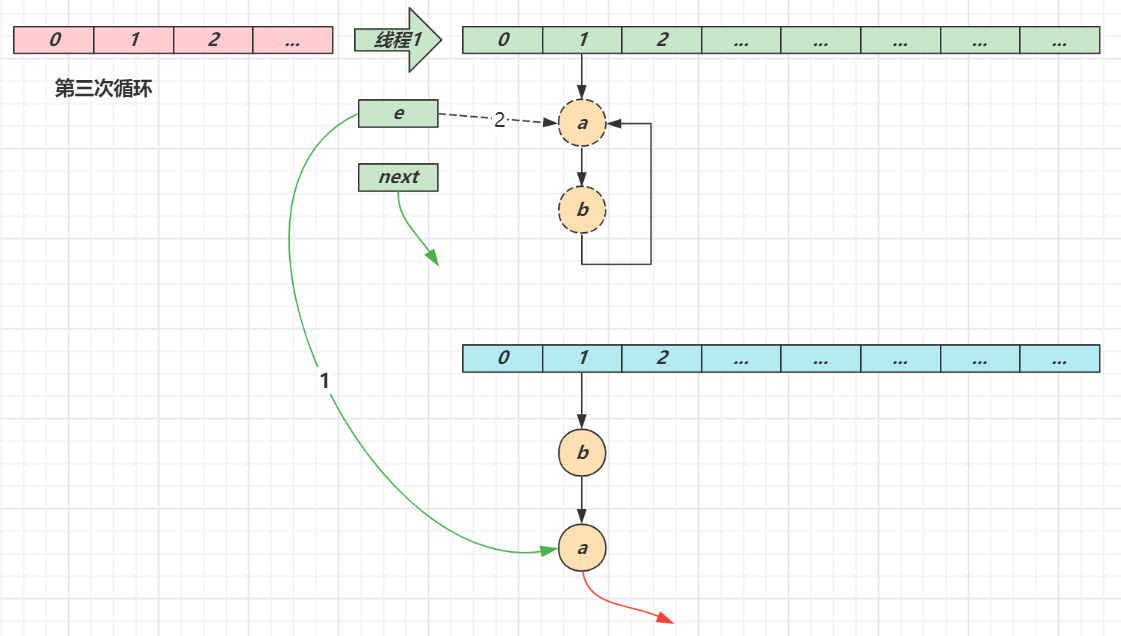
第一次循环
循环接着线程切换前运行,注意此时 e 指向的是节点 a,next 指向的是节点 b
e 头插 a 节点,注意图中画了两份 a 节点,但事实上只有一个(为了不让箭头特别乱画了两份)
当循环结束是 e 会指向 next 也就是 b 节点

第二次循环
next 指向了节点 a
e 头插节点 b
当循环结束时,e 指向 next 也就是节点 a
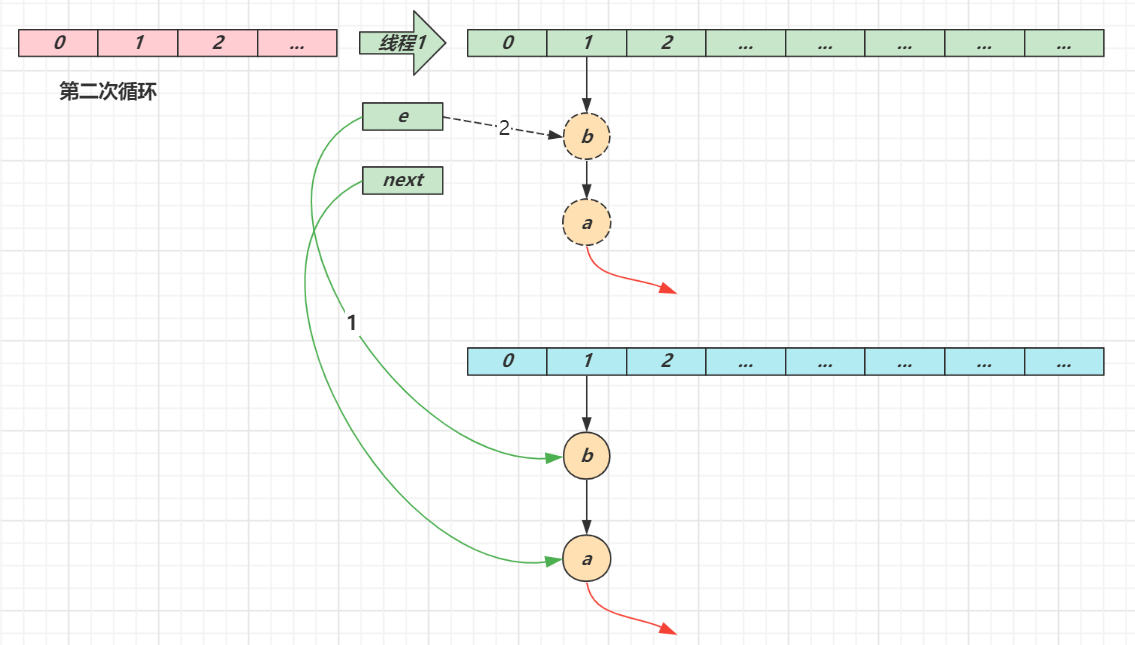
第三次循环
next 指向了 null
e 头插节点 a,a 的 next 指向了 b(之前 a.next 一直是 null),b 的 next 指向 a,死链已成
当循环结束时,e 指向 next 也就是 null,因此第四次循环时会正常退出
HashMap知识点的更多相关文章
- HashMap知识点总结,这一篇算是总结的不错的了,建议看看!
HashMap存储结构 内部包含了⼀个 Entry 类型的数组 Entry[] table.transient Entry[] table;(transient:表示不能被序列化)Entry类型存储着 ...
- HashMap知识点、问题
转载:https://blog.csdn.net/qq_27007251/article/details/71403647 https://www.cnblogs.com/kxdblog/p/4323 ...
- 阿里P7岗位面试,面试官问我:为什么HashMap底层树化标准的元素个数是8
前言 先声明一下,本文有点标题党了,像我这样的菜鸡何德何能去面试阿里的P7岗啊,不过,这确实是阿里p7级岗位的面试题,当然,参加面试的人不是我,而是我部门的一个大佬.他把自己的面试经验分享给了我,也让 ...
- 牛客网Java刷题知识点之为什么HashMap和HashSet区别
不多说,直接上干货! HashMap 和 HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的 ...
- 牛客网Java刷题知识点之为什么HashMap不支持线程的同步,不是线程安全的?如何实现HashMap的同步?
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- HashMap面试知识点
HashMap的工作原理是近年来常见的Java面试题. 几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么为何这道面试题如 ...
- HashMap面试知识点总结
主要参考 JavaGuide 和 敖丙 的文章, 其中也有参考其他的文章, 但忘记保存链接了, 文中图片也是引用别的大佬的, 请见谅. 新手上路, 若有问题, 欢迎指正. 背景 HashMap 的相关 ...
- HashMap几个需要注意的知识点
HashMap简介 HashMap 是java集合框架的一部分. key value都允许null值 (除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同) 不保 ...
随机推荐
- STM32的中断刨析(完结)
STM32中断刨析 一直以来,学习了 stm32 和 freertos 但在思考 RTOS 的任务调度时,涉及到 stm32 的中断相关的 PendSV 就感觉糊里糊涂.本篇记录刨析 stm32 的中 ...
- Linux中的用户管理-创建删除修改
用户管理 一.用户分类 用户分为三类: 1.管理员 root root UID:0 #拥有最高权限 默认系统中就一个 UID即user ID 类似于身份号码,唯一的,不可重复 2.虚拟用户 作用:在运 ...
- python get请求传array数组
前言 使用传统的http发get请求时,如果传参为array数组,参数名称为a时,可以这样传值a=1&a=2&a=3,但是当只有一个时,这种方式就不合理了. get请求还有另外一种方式 ...
- btrace一些你不知道的事(源码入手)
背景 周五下班回家,在公司班车上觉得无聊,看了下btrace的源码(自己反编译). 一些关于btrace的基本内容,可以看下我早起的一篇记录:btrace记忆 上一篇主要介绍的是btrace的一些基本 ...
- NOIP2024加赛8
NOIP2024加赛8 T1 flandre 第 4 个样例没给全,说明这可以直接猜结论 首先我们假设选定了 $ x $ 个数,那么我们肯定是把他们从小到大排好序依次放,这样才能使整体效果最大.然后我 ...
- ThreadLocal-全概念解析
介绍 ThreadLocal 提供线程局部变量,ThreadLocal实例通常是线程私有静态字段,使用的目的是希望将线程与状态关联起来.与JMM中局部变量有几分相似之处,但是不用写回主内存(如果违反, ...
- Echarts 提示组件
1.开启指示器 默认情况下,指示器是关闭状态,如果需要开启,直接配置tooltip字段即可 var option = { tooltip:{}, } 2.指示器的触发类型 触发类型的字段为trigge ...
- 阿里巴巴LangEngine开源了!支撑亿级网关规模的高可用Java原生AI应用开发框架
LangEngine作为阿里集团内部发起的纯Java版本的AI应用开发框架,经过充分实践,已经广泛应用于包括淘宝.天猫.阿里云.爱橙科技.菜鸟.蚂蚁.飞猪.1688.LAZADA等在内的多个业务场景. ...
- 【Amadeus原创】Docker安装最新版wordpress
0.安装docker curl -fsSL https://get.docker.com | bash -s docker --mirror aliyun service docker start 1 ...
- ChatGPT生成测试用例的最佳实践(四)
通常情况下还应该进行测试用例外部评审.将已完成的基于百度关键字搜索业务的功能和安全测试用例集的存放位置告知项目团队成员,需要预留出一定的时间,便于项目组研发.产品人员阅读,以免在项目团队测试用例评审会 ...