TaskPyro:一个轻量级的 Python 任务调度和爬虫管理平台
前言
推荐一款本人在使用的Python爬虫管理平台,亲测不错!!!
TaskPyro 是什么?
TaskPyro 是一个轻量级的 Python 任务调度平台,专注于提供简单易用的任务管理和爬虫调度解决方案。它能够帮助您轻松管理和调度 Python 任务,特别适合需要定时执行的爬虫任务和数据处理任务。
开发背景
在当今数字化时代,自动化数据采集和处理变得越来越重要。然而,现有的任务调度解决方案要么过于复杂,要么缺乏针对 Python 环境的特定优化。TaskPyro 正是为了解决这些痛点而诞生的,旨在为 Python 开发者提供一个简单、高效、可靠的任务调度平台。
为什么选择TaskPyro?
- 轻量级设计:占用资源小,运行高效
- 灵活调度:支持多种调度方式,满足各类需求
- Python环境管理:自由分配不同的Python虚拟环境
- 可视化监控:直观的任务运行状态展示
- 安全可靠:完善的异常处理和错误恢复机制
适用人群
TaskPyro 特别适合以下用户群体:
- 数据工程师:需要定期执行数据采集、清洗和处理任务
- ️ 爬虫开发者:需要管理和调度多个爬虫任务
- 数据分析师:需要自动化数据分析流程
- ️ 系统运维人员:需要执行定时系统维护任务
- 创业团队:需要一个轻量级但功能完整的任务调度解决方案
使用流程
- 先配置Python环境
- 创建项目
- 创建定时任务
核心功能
TaskPyro 提供了一系列强大的功能,帮助您高效管理 Python 任务:
灵活的任务调度
- 支持 Cron 表达式定时调度
- 支持固定间隔调度
- 支持一次性任务执行
- 支持任务依赖关系配置
Python 环境管理
- 支持多个 Python 虚拟环境
- 环境隔离,避免依赖冲突
- 支持 pip 包管理
️ 爬虫框架支持
- 支持 Scrapy 等主流爬虫框架
- 支持 Selenium、Playwright、DrissionPage 等浏览器自动化工具
- 提供完整的框架运行环境配置
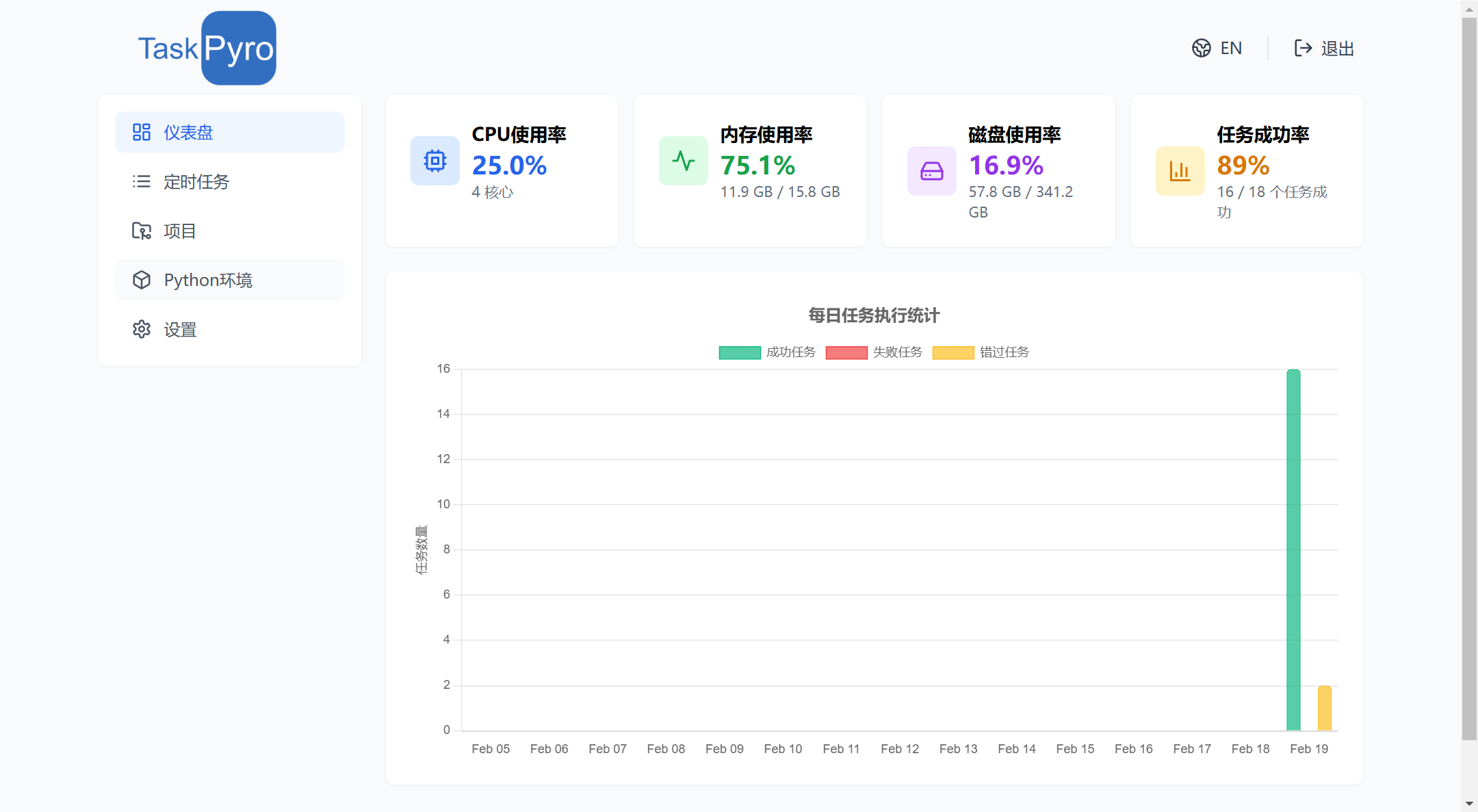
任务监控与管理
- 实时任务状态监控
- 详细的执行日志记录
- 任务执行统计分析
- 异常通知与告警
用户友好
- 直观的 Web 操作界面
- 详细的使用文档
- 简单的部署流程
- 完善的错误处理机制
Docker 安装
TaskPyro 提供了基于 Docker 的快速部署方案,让您能够轻松地在任何支持 Docker 的环境中运行。
前置条件
在开始安装之前,请确保您的系统已经安装了以下软件:
Docker 安装
- Docker(本人使用的版本为 26.10.0,低于此版本安装可能会存在问题,建议删除旧版本,升级新版本docker)
Docker Compose 安装
- Docker Compose(版本 2.0.0 或更高)
- 注意:如果您使用的是 Docker 26.1.0 版本,建议安装最新版本的 Docker Compose 以确保兼容性
安装步骤
0. 拉取代码
gitub
git clone https://github.com/taskPyroer/taskpyro.git
gitee
git clone https://gitee.com/hu_yupeng123/taskpyrodocker.git
可以直接拉取上面的代码,或者按下面的1、2、3步骤创建文件
1. 创建项目目录
mkdir taskpyro
cd taskpyro
2. 创建 docker-compose.yml 文件
在项目目录中创建 docker-compose.yml 文件,内容如下:
version: '3'
services:
frontend:
image: crpi-7ub5pdu5y0ps1uyh.cn-hangzhou.personal.cr.aliyuncs.com/taskpyro/taskpyro-frontend:1.0
ports:
- "${FRONTEND_PORT:-7789}:${FRONTEND_PORT:-7789}"
environment:
- PORT=${FRONTEND_PORT:-7789}
- SERVER_NAME=${SERVER_NAME:-localhost}
- BACKEND_PORT=${BACKEND_PORT:-8000}
- API_URL=http://${SERVER_NAME}:${BACKEND_PORT:-8000}
- TZ=Asia/Shanghai
env_file:
- .env
depends_on:
- api
api:
image: crpi-7ub5pdu5y0ps1uyh.cn-hangzhou.personal.cr.aliyuncs.com/taskpyro/taskpyro-api:1.0
ports:
- "${BACKEND_PORT:-8000}:${BACKEND_PORT:-8000}"
environment:
- PORT=${BACKEND_PORT:-8000}
- PYTHONPATH=/app
- CORS_ORIGINS=http://localhost:${FRONTEND_PORT:-7789},http://127.0.0.1:${FRONTEND_PORT:-7789}
- TZ=Asia/Shanghai
- WORKERS=${WORKERS:-1}
volumes:
- /opt/taskpyrodata/static:/app/../static
- /opt/taskpyrodata/logs:/app/../logs
- /opt/taskpyrodata/data:/app/data
env_file:
- .env
init: true
restart: unless-stopped
3. 创建 .env 文件
在项目目录中创建 .env 文件,用于配置环境变量:
FRONTEND_PORT=8080
BACKEND_PORT=9000
SERVER_NAME=localhost
WORKERS=1
4. 启动服务
docker-compose up -d
启动后直接在浏览器中访问至 http://<your_ip>:8080
安装注意事项
数据持久化
- 数据文件会保存在
/opt/taskpyrodata目录下,包含以下子目录:static:静态资源文件logs:系统日志文件data:应用数据文件
- 建议定期备份这些目录,特别是
data目录
- 数据文件会保存在
环境变量配置
- 在
.env文件中配置以下必要参数:FRONTEND_PORT:前端服务端口(默认8080)BACKEND_PORT:后端服务端口(默认9000)SERVER_NAME:服务器域名或IP(默认localhost,不用修改)WORKERS:后端工作进程数(默认1,不用修改)- 确保
SERVER_NAME配置正确,否则可能导致API调用失败
- 在
端口配置
- 前端服务默认使用8080端口
- 后端服务默认使用9000端口
- 确保这些端口未被其他服务占用
- 如需修改端口,只需要更新
.env文件中的配置
容器资源配置
- 建议为容器预留足够的CPU和内存资源
- 可通过Docker的资源限制参数进行调整
- 监控容器资源使用情况,适时调整配置
常见问题
前端服务无法访问
- 检查
FRONTEND_PORT端口是否被占用 - 确认前端容器是否正常启动:
docker-compose ps frontend - 查看前端容器日志:
docker-compose logs frontend - 验证
SERVER_NAME配置是否正确
- 检查
后端API连接失败
- 检查
BACKEND_PORT端口是否被占用 - 确认后端容器是否正常启动:
docker-compose ps api - 查看后端容器日志:
docker-compose logs api - 验证
CORS_ORIGINS配置是否包含前端访问地址
- 检查
容器启动失败
- 检查 Docker 服务状态:
systemctl status docker - 确认 docker-compose.yml 文件格式正确
- 验证环境变量配置是否完整
- 检查数据目录权限:
ls -l /opt/taskpyrodata
- 检查 Docker 服务状态:
数据持久化问题
- 确保
/opt/taskpyrodata目录存在且有正确的权限 - 检查磁盘空间是否充足
- 定期清理日志文件避免空间占用过大
- 建议配置日志轮转策略
- 确保
资源配置
- 根据实际需求调整 Docker 容器的资源限制
- 监控服务器资源使用情况,适时调整配置
升级说明
要升级到新版本,请执行以下步骤:
# 拉取最新镜像
docker-compose pull
# 重启服务
docker-compose up -d
更详细的文档
TaskPyro:一个轻量级的 Python 任务调度和爬虫管理平台的更多相关文章
- 分布式爬虫管理平台Crawlab安装与使用
Why,为什么需要爬虫管理平台? 以下摘自官方文档: Crawlab主要解决的是大量爬虫管理困难的问题,例如需要监控上百个网站的参杂scrapy和selenium的项目不容易做到同时管理,而且命令行管 ...
- Crawlab Lite 正式发布,更轻量的爬虫管理平台
Crawlab 是一款基于 Golang 的分布式爬虫管理平台,产品发布已经一年有余,经过开发团队的不断打磨,即将迭代到 v0.5 版本.在这期间我们为 Crawlab 加入了大量社区用户共同期望的功 ...
- 爬虫管理平台以及wordpress本地搭建
爬虫管理平台以及wordpress本地搭建 学习目标: 各爬虫管理平台了解 scrapydweb gerapy crawlab 各爬虫管理平台的本地搭建 Windows下的wordpress搭建 爬虫 ...
- 使用Docker部署爬虫管理平台Crawlab
当前目录创建 docker-compose.yml 文件 version: '3.3' services: master: image: tikazyq/crawlab:latest containe ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记
零.背景 之前在 node.js 下写过一些爬虫,去做自己的私人网站和工具,但一直没有稍微深入的了解,借着此次公司的新项目,体系的学习下. 本文内容主要侧重介绍爬虫的概念.玩法.策略.不同工具的列举和 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- Python静态网页爬虫相关知识
想要开发一个简单的Python爬虫案例,并在Python3以上的环境下运行,那么需要掌握哪些知识才能完成一个简单的Python爬虫呢? 爬虫的架构实现 爬虫包括调度器,管理器,解析器,下载器和输出器. ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
随机推荐
- COCI 2024/2025 #3
T1 P11474 [COCI 2024/2025 #3] 公交车 / Autobus 愤怒,从红升橙足以说明其恶心,考场上调了半小时才过. 这道题的车能够开 \(24\) 小时,并且他能从前一天开到 ...
- 痞子衡嵌入式:Farewell, 我的写博故事2024
-- 题图:苏州周庄古镇双桥 2024 年的最后一天,照旧写个年终总结.今年工作上稳步发挥,但是在生活上收获了一个新的爱好,大家可能知道,痞子衡比较爱运动,一直有在打篮球羽毛球桌球.有感于公司乒乓球文 ...
- 记录一个uniapp写的小程序的手写板,横屏,用于签名,也可竖屏
今天需要在小程序增加一个手写板的功能,但是得横向的手写纵向的保存,直接上代码,竖屏的时候不需要旋转图片 <template> <view class="wrapper&qu ...
- PyScript 使用(1)
今天按照官方文档进行pyscript的调用,发现paths下总是出现问题,于是调试了一下,问题解决了: # data.py import numpy as np def make_x_and_y(n) ...
- Java接口-详解
一.基本概念 接口(Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合.接口通常以interface来声明.一个类通过继承接口的方式,从而来继承接口的抽象方法. 如果一个类只由 ...
- 【Netty】(5)-源码 Bootstrap
[Netty]5 源码 Bootstrap 上一篇讲了AbstractBootstrap,为这篇做了个铺垫. 一.概述 Bootstrap 是 Netty 提供的一个便利的工厂类, 我们可以通过它来完 ...
- 使用pict生成正交表
使用pict可以自动生成正交表 步骤: 1.安装 2.新建TXT文件,格式为: 因子1:水平项1,水平项2 因子2:水平项1,水平项2 多个水平项用英文逗号分割 3.生成,打开cmd,切换到要 ...
- atomikos实现分布式事务
date: 2022-04-25 categories: [java, 编程] tags: [分布式事务] 概述 多数据源单服务写入, 分布式事务实现 使用随机数控制产生异常 注: 网上很多都是只有多 ...
- 小程序之confirm-type改变键盘右下角的内容和input按钮详解
confirm-type的介绍 confirm-type 在什么时候使用呢? 如果说搜索框的时候,当用户输入完了之后,我们就需要 将confirm-type="search"的值设 ...
- 2024大湾区网络安全大会,AOne来了!
近日,2024大湾区网络安全大会暨第二十六期花城院士科技会议在广州启幕.学者专家.高校院长.政府相关负责人及行业大咖齐聚一堂,围绕网络安全的前沿话题与挑战展开深入交流与探讨.天翼云科技有限公司网络安全 ...