DataDream:调一调更好,基于LoRA微调SD的训练集合成新方案 | ECCV'24
尽管文本到图像的扩散模型已被证明在图像合成方面达到了最先进的结果,但它们尚未证明在下游应用中的有效性。先前的研究提出了在有限的真实数据访问下为图像分类器训练生成数据的方法。然而,这些方法在生成内部分布图像或描绘细粒度特征方面存在困难,从而阻碍了在合成数据集上训练的分类模型的泛化能力。论文提出了
DataDream,一个合成分类数据集的框架,在少量目标类别示例的指导下,更真实地表示真实数据分布。
DataDream在生成训练数据之前,对图像生成模型的LoRA权重进行微调,使用少量真实图像。然后,使用合成数据微调CLIP的LoRA权重,以在各种数据集上改善下游图像分类性能,超越先前的方法。通过大量实验展示了
DataDream的有效性,在10个数据集中的7个数据集上,以少量示例数据超越了最先进的分类准确率,同时在其他3个数据集上也表现竞争力。此外,论文提供了关于多种因素的影响的见解,例如真实图像和生成图像的数量以及微调计算对模型性能的影响。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: DataDream: Few-shot Guided Dataset Generation

Introduction
文本到图像生成模型的出现,例如稳定扩散(Stable Diffusion),不仅能够创建照片真实感的合成图像,还为增强下游任务提供了机会。一个潜在的应用是在合成数据上训练或微调特定任务的模型。这在真实数据获取有限的领域尤其有用,因为生成模型提供了一种经济高效的方式来生成大量训练数据。论文研究了合成训练数据在低样本设置下对图像分类任务的影响,即当每个类别只有少量图像可用,但收集整个数据集的成本将是难以承受的。

之前的研究主要集中在使用给定数据集的类名称来指导数据生成过程。具体来说,他们使用文本到图像扩散模型生成图像,将类名称作为条件输入。为了更好地引导模型生成目标对象的准确描绘,他们将每个类的文本描述纳入提示中,这些描述来自语言模型或人工标注的类描述。尽管这些方法直观,但导致一些生成的图像缺乏所关注的对象。例如,来自ImageNet数据集的类名称“clothes iron”的真实图像显示的是用于熨烫衣物的电器,而FakeIt生成的图像大多描绘的是金属熨斗或由其制成的任意物体(见图1,左侧)。这种情况发生在生成模型误解类名称的模糊性或稀有类别时。现实图像与合成图像之间的这种不一致限制了生成图像在图像分类中的信息价值,并阻碍了性能的提升。
为了弥合真实图像与合成图像之间的差距,真实图像可以更好地为生成模型提供有关真实数据分布特征的信息。例如,正在同时开发的DISEF方法在生成合成数据集时,从部分带噪声的真实图像开始,将少量样本作为条件输入到预训练的扩散模型中。它还使用预训练的图像描述模型来多样化文本到图像的提示。虽然这种方法改善了真实数据和合成数据分布的对齐,但有时未能捕捉到细粒度特征。例如,尽管航空数据集中“DHC-3-800”类名称的真实图像在机翼前包含一个螺旋桨,但DISEF生成的合成图像缺乏这个细节(见图1,右侧)。准确表示类区分特征对分类任务来说可能至关重要,尤其是在细粒度数据集中。
为此,论文提出了一种新方法DataDream,旨在利用少量真实数据来适应生成模型。受到个性化生成建模方法的启发,这些方法通过少量描绘相同对象的真实图像对生成模型进行微调,该方法侧重于将生成模型对齐到一个具有多类和每类多样化对象的目标数据集。这与之前的少量样本数据集生成方法不同,后者并未探索微调生成模型的可能性。
具体来说,通过两种方式基于LoRA来调整Stable Diffusion: \(\text{DataDream}_{\text{cls}}\) ,为每个类训练LoRA,以及 \(\text{DataDream}_{\text{dset}}\) ,为所有类训练一个LoRA。论文是首个提出使用少量样本数据来适应生成模型以生成合成训练数据的方法,而不是利用已冻结的预训练生成模型。在训练之后,使用相同的提示生成图像,该提示用于微调DataDream,生成的图像描绘了所关注的对象(例如衣物熨斗)或细粒度特征(例如DHC-3-800飞机的螺旋桨),如图1的最后一行所示。
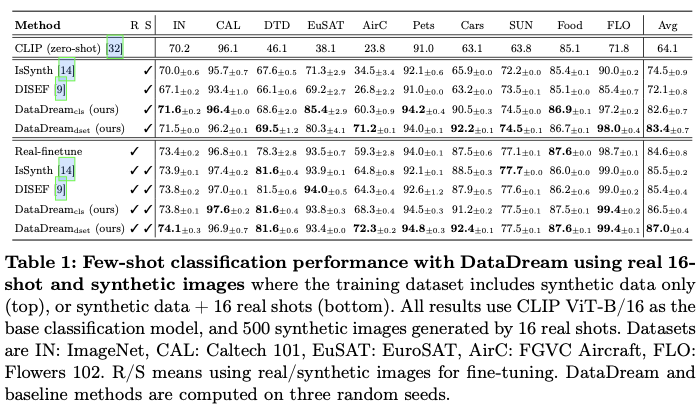
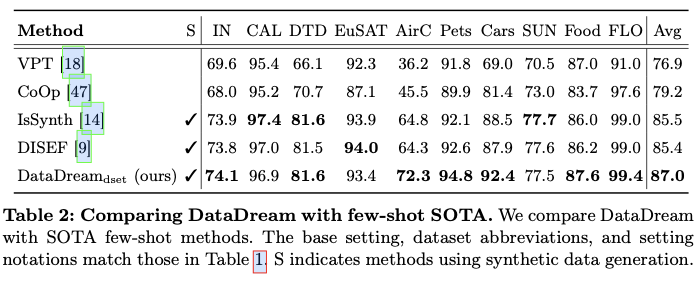
通过大量实验验证了DataDream的有效性,只使用合成数据时,在所有数据集中达到了最先进的水平,并且在同时使用真实少量样本和合成数据进行训练时,在10个数据集中有7个获得了最佳性能。为了理解该方法的有效性,论文分析了真实数据与合成数据之间的对齐情况,揭示了该方法在与真实数据分布的对齐方面优于基线方法。最后,通过增加合成数据点和真实样本的数量,探讨了该方法的可扩展性,显示了更大数据集的潜在好处。
总之,论文的贡献如下:
引入了
DataDream,一种新颖的少量样本方法,该方法改进了Stable Diffusion,以生成更好的同类分布图像,从而用于下游训练。在10个数据集中,DataDream在7个上超过了最先进的少量样本分类表现,其余3个数据集的表现则相当。强调仅使用合成数据报告结果的重要性。证明当仅使用合成数据训练分类器时,论文的方法能够取得更优的性能,在某些情况下甚至超过了仅使用真实少量样本图像训练的分类器,这表明论文的方法生成的图像能够从少量真实数据中提取出更具洞察力的信息。
通过分析合成数据与真实数据之间的分布对齐情况来研究论文方法的有效性。在少量样本的指导下,该方法生成的合成数据与真实数据的对齐效果最佳。
Methodology
Preliminaries
Latent diffusion model
论文的方法基于Stable Diffusion实现,这是一种概率生成模型,通过文本提示学习生成真实的图像。给定数据 \((x,c) \in {\mathcal{D}}\) ,其中 \(x\) 是一幅图像, \(c\) 是描述 \(x\) 的标题,该模型通过逐渐去噪潜在空间中的高斯噪声来学习条件分布 \(p(x|c)\) 。给定一个预训练的编码器 \(E\) ,它将图像 \(x\) 编码为潜在变量 \(z\) ,即 \(z=E(x)\) ,目标函数定义为:
\min_{\theta} \,\, \mathbb{E}_{(x,c) \sim {\mathcal{D}}, \, \epsilon \sim {\mathcal{N}}(0,1), \, t} \, \left[\, \left\| \, \epsilon - \epsilon_{\theta} (z_t, \tau(c), t) \, \right\|_2^2 \,\right] \, ,
\end{equation}
\]
其中 \(t\) 是时间步, \(z_t\) 是距离潜在变量 \(z\) \(t\) 步的潜在带噪声数据, \(\tau\) 是文本编码器, \(\epsilon_{\theta}\) 是潜在扩散模型。直观上,参数 \(\theta\) 被训练用于去噪给定文本提示 \(c\) 作为条件信息的潜在 \(z_t\) 。在推理阶段,一个随机噪声向量 \(z_T\) 通过潜在扩散模型进行了 \(T\) 次传递,并与标题 \(c\) 一起,得到去噪后的潜在变量 \(z_0\) 。随后,将 \(z_0\) 输入到一个预训练的解码器 \(D\) 中,以生成图像 \(x'=D(z_0)\) ,用于文本到图像的生成。
Low-rank adaptation
低秩适配方法(LoRA)是一种微调方法,用于以参数高效的方式将大型预训练模型调整到下游任务。给定预训练模型权重 \(\theta \in \mathbb{R}^{d \times k}\) ,LoRA引入一个新的参数 \(\delta \in \mathbb{R}^{d \times k}\) ,该参数被分解为两个矩阵, \(\delta=BA\) ,其中 \(B \in \mathbb{R}^{d \times r}\) , \(A \in \mathbb{R}^{r \times k}\) ,且具有较小的LoRA秩 \(r\) ,即 \(r \ll \min (d, k)\) 。LoRA权重添加到模型权重中以获得微调后的权重,即 \(\theta^{\text{(ft)}} = \theta \!+ \delta\) ,以适应下游任务。在训练过程中, \(\theta\) 保持固定,而仅更新 \(\delta\) 。
DataDream method
论文的目标是通过利用扩散模型生成的合成图像来提高分类性能,至关重要的是将合成图像的分布与真实图像的分布对齐。通过将扩散模型调整为少量真实图像的数据集来实现这种对齐。
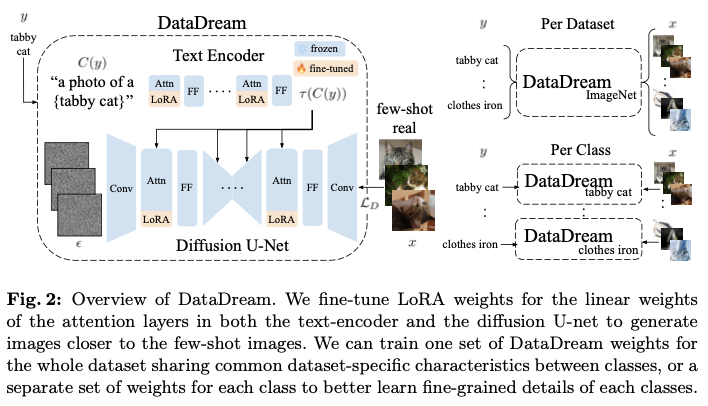
假设可以访问一个少量样本的数据集 \({\mathcal{D}}^{\text{fs}}=\{(x_i, y_i)\}_{i=1}^{KN}\) ,其中 \(x_i\) 是一张图像, \(y_i \in \{1,2,\cdots\!, N\}\) 是它的标签, \(K\) 是每个类别的样本数量, \(N\) 是类别的数量。为了匹配真实数据的分布,使用少量样本的数据集 \({\mathcal{D}}^{\text{fs}}\) 进行微调。具体来说,在扩散模型的文本编码器和 U-net 中引入 LoRA 权重,在这里选择有效地调整注意力层的参数。对于每个注意力层,考虑查询、键、值和输出投影矩阵 \(W_q\), \(W_k\), \(W_v\), \(W_o\),在每个矩阵中,线性投影被替换为
h_{l,\star} = W_{\star} h_{l-1} + B_{\star} A_{\star} h_{l-1}
\end{equation}
\]
其中 \(h\) 表示投影的输入/输出激活,最终得到每个注意力层 \(l\) 的可训练LoRA权重 \(\delta^{(l)} = \{A_{\star}, B_{\star} | \forall \star \in \{q, k, v, o\}\}\) 。为了简化符号,省略偏置权重。所有其他模型参数(包括 \(W_{\star}\) )保持不变,而 \(\delta\) 权重则通过梯度下降进行优化。
为了从预训练的扩散模型checkpoint开始训练,权重矩阵 \(B_{\star}\) 被初始化为零,而 \(A_{\star}\) 则随机初始化。因此,组合的微调权重 \(B_{\star} A_{\star}\) 最初为零,并逐步学习对原始预训练权重的修改。在测试时,LoRA权重可以通过更新权重 \(W^{\text{(ft)}}_{\star} =W_{\star} + B_{\star} A_{\star}\) 集成到模型中,使得推理时间与预训练模型相同。与DreamBooth相比,不微调所有网络权重,也不添加保留损失,因为其正则化会阻碍与真实图像的强对齐。
进一步考虑两种设置:1) \(\text{DataDream}_{\text{dset}}\) ,在该设置中,在整个数据集 \({\mathcal{D}}^{\text{fs}}\) 上训练扩散模型的LoRA权重,2) \(\text{DataDream}_{\text{cls}}\) ,在该设置中,为数据集中的每个类别初始化 \(N\) 组LoRA权重 \(\{\delta_n|n=1,\cdots\!,N\}\) ,每组权重针对子集 \({\mathcal{D}}^{\text{fs}}_{n} = \{(x,y)| (x,y) \!\in {\mathcal{D}}^{\text{fs}}, y\!=\!n\}\) 进行训练。
在 \(\text{DataDream}_{\text{dset}}\) 设置中,原始模型参数 \(\theta\) 保持不变,仅对LoRA权重进行训练,目标函数为
\min_{\delta} \mathcal{L}_{\text{D}} = \min_{\delta} \,\, \mathbb{E}_{(x,y) \sim {\mathcal{D}}^{\text{fs}}, \, \epsilon \sim {\mathcal{N}}(0,1), \, t} \, \left[\, || \, \epsilon - \epsilon_{\theta\!, \delta} (z_t, \tau_{\delta}(C(y)), t) \, ||_2^2 \,\right] \, .
\label{eq:datadream_loss}
\end{equation}
\]
在 \(\text{DataDream}_{\text{cls}}\) 设置中, \({\mathcal{D}}^{\text{fs}}_{n}\) 和 \(\delta_n\) 分别替代 \({\mathcal{D}}^{\text{fs}}\) 和 \(\delta\) 。由于使用的是文本到图像的扩散模型,通过函数 \(C\) 定义文本条件,该函数将标签 \(y\) (即类名)映射到使用标准模板 "a photo of a[CLS]" 的提示。该提示会通过文本编码器传递,并在扩散模型的解码步骤中使用。
这两种设置各有不同的优势。在 \(\text{DataDream}_{\text{dset}}\) 中,类之间的LoRA权重共享允许在整个数据集内进行关于共性特征的知识转移。这对于那些在各类别中共享粗粒度特征的细粒度数据集是有益的。另一方面, \(\text{DataDream}_{\text{cls}}\) 为学习每个类别的细节分配了更多的权重,这使得生成模型能够更好地与每个类别的数据分布对齐。
在将扩散模型适应于少样本数据集后,使用调整后的模型在相同的文本提示条件下为每个类别生成500张图像,该文本提示与DataDream使用的相同,从而形成一个合成数据集 \({\mathcal{D}}^{synth}\) 。在仅使用合成图像或合成与真实少样本图像的组合 \({\mathcal{D}}^{fs}\) 上训练分类器。
对于分类器的训练,调整了一个CLIP模型,类似于之前在少样本分类中的工作。为CLIP ViT-B/16模型的图像编码器和文本编码器添加了LoRA适配器。在同时使用合成图像和真实图像进行训练时,使用来自真实数据和合成数据的损失的加权平均。
\mathcal{L}_{\text{C}} = \,\,
\lambda \, \mathbb{E}_{(x,y) \sim {\mathcal{D}}^{\text{fs}}} \, \text{CE}(f(x),y) +
(1 \!-\! \lambda) \, \mathbb{E}_{(x,y) \sim {\mathcal{D}}^{\text{synth}}} \, \text{CE}(f(x),y) \, ,
\end{equation}
\]
其中 \(\lambda\) 是分配给来自真实数据的损失的权重,函数 \(\text{CE}\) 是交叉熵损失。
Implementation details
基于Stable Diffusion版本2.1实现了DataDream,计算基于三个随机种子。对于每个种子,从每个数据集的训练样本中随机抽样少量图像。在所有数据集上训练200个周期,批量大小为8,唯一的例外是 \(\text{DataDream}_{\text{dset}}\) 在ImageNet上训练100个周期。因此, \(\text{DataDream}_{\text{dset}}\) 和 \(\text{DataDream}_{\text{cls}}\) 有相同的训练计算量,即每 \(N\) 个 \(\text{DataDream}_{\text{cls}}\) 适配器权重(每类一个)执行 \(S/N\) 次更新步骤,其中 \(S\) 是整个数据集的 \(\text{DataDream}_{\text{dset}}\) 的总步骤数。
使用AdamW作为优化器,学习率为 \(1e-4\) ,并采用余弦退火调度器。对DataDream中所有适配权重使用LoRA级别 \(r=16\) 。对于DataDream的合成图像生成,使用50次步骤和指导尺度2.0。如果未提及,则每类生成500张图像。对于分类器,使用CLIP ViT-B/16作为基础模型,并在CLIP的图像编码器和文本编码器上应用LoRA进行微调,级别为16。将分配给真实损失项的权重设置为 \(\lambda=0.8\) 。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

DataDream:调一调更好,基于LoRA微调SD的训练集合成新方案 | ECCV'24的更多相关文章
- advisor调优工具优化sql(基于sql_id)
advisor调优工具优化sql(基于sql_id) 问题背景:客户反馈数据库迁移后cpu负载激增,帮忙查看原因 解决思路:1> 查看问题系统发现有大量的latch: cache buffers ...
- JVM调优(三)——基于Btrace的监控调试
JVM调优(三)--基于Btrace的监控调试 简介 Btrace可以动态地向目标应用程序的字节码注入追踪代码 用到的技术: JavaComplierApi.JVMTI.Agent.Instrumen ...
- JVM调优(二)——基于JVisualVM的可视化监控
JVM调优(二)--基于JVisualVM的可视化监控 工具路径://java/jdk1.8xxx/bin/JVisuaVM.exe 监控本地的Tomcat 监控远程Tomcat 监控普通的JAVA进 ...
- 我们基于kaldi开发的嵌入式语音识别系统升级成深度学习啦
先前的文章<三个小白是如何在三个月内搭一个基于kaldi的嵌入式在线语音识别系统的>说我们花了不到三个月的时间搭了一个基于kaldi的嵌入式语音识别系统,不过它是基于传统的GMM-HMM的 ...
- 云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
引言 随着模型规模和数据量的不断增大,分布式训练已经成为了工业界主流的 AI 模型训练方式.基于 Kubernetes 的 Kubeflow 项目,能够很好地承载分布式训练的工作负载,业已成为了云原生 ...
- 【模型压缩】MetaPruning:基于元学习和AutoML的模型压缩新方法
论文名称:MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning 论文地址:https://arxiv.org/ ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- 基于 SSR 的预渲染首屏直出方案
基于 SSR 的预渲染首屏直出方案 Create React Doc 是一个使用 React 的 markdown 文档站点生成工具.此前在 Create React Doc 中引入了预渲染技术来预先 ...
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- 基于MDK的ARM-GCC开发环境建立及新唐M0的HID类设备的C++开发
一,下载安装测试arm-none-eabi-gcc编译工具链 1,查看arm-none-eabi-gcc编译工具版本 打开网页:https://sourcery.mentor.com/G ...
随机推荐
- ubuntu18.04 源码方式安装wine , 警告,libxrender 64-bit development files not found, XRender won't be supported.
警告信息: configure: WARNING: libxrender 64-bit development files not found, XRender won't be supported. ...
- 使用 defineNuxtRouteMiddleware 创建路由中间件
title: 使用 defineNuxtRouteMiddleware 创建路由中间件 date: 2024/8/10 updated: 2024/8/10 author: cmdragon exce ...
- 牛客周赛 Round 5
牛客周赛 Round 5 A-游游的字母变换_牛客周赛 Round 5 (nowcoder.com) #include <bits/stdc++.h> #define int long l ...
- Linux中登录mysql
输入 mysql -u root -p 然后输入密码,就能登录 root@zrt2:/home/zrt2# mysql -u root -pEnter password: Welcome to the ...
- Git回退服务器版本及receive.denyDeleteCurrent配置
https://blog.csdn.net/sunalongl/article/details/52013435 如果某次修改了某些内容,并且已经commit到本地仓库,而且已经push到远程仓库了, ...
- Win32_GDI_绘制文字路径透明窗口
效果图: 前面字体是个透明窗口 后面是桌面背景 代码实现: void MyMainDialog::TextPathWindow(LPCTSTR lpShowText) { HDC hdc = GetD ...
- win10缺少SNMP服务解决办法
一,以管理员的身份启动Powershell 第一步在win10系统任务栏上,点击搜索图标,输入"PowerShell",如下图所示: 2 第二步搜索到PowerShell之后,鼠标 ...
- maven 插件之 maven-shade-plugin,解决同包同名 class 共存问题的神器
开心一刻 有一天螃蟹出门,不小心撞倒了泥鳅泥鳅很生气地说:你是不是瞎啊!螃蟹说:不是啊,我是螃蟹 概述 maven-shade-plugin 官网已经介绍的很详细了,我给大家简单翻译一下 This p ...
- ansible rpm包下载
Ansible2.9.18版本下载链接:https://pan.baidu.com/s/1dKlwtLWSOKoMkanW900n9Q 提取码:ansi 将软件上传至系统并解压安装: # tar -z ...
- linux 环境中cat命令进行关键字搜索
在linux环境中通过关键字搜索文件里面的内容 1.显示文件里匹配关键字那行以及上下50行 cat 文件名 | grep -C 50 '关键字' 2.显示关键字及前50行 cat 文件名 | grep ...