Redis底层数据结构 链表
链表
Redis 的 List 对象的底层实现之一就是链表。C 语言本身没有链表这个数据结构的,所以 Redis 自己设计了一个链表数据结构。
链表节点结构设计
先来看看「链表节点」结构的样子:
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
有前置节点和后置节点,可以看的出,这个是一个双向链表。
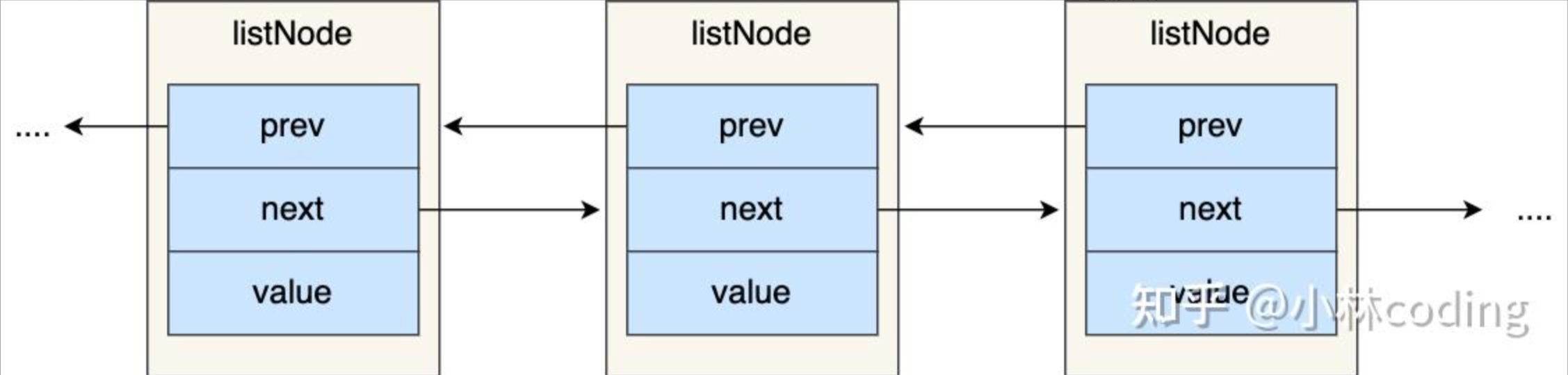
链表结构设计
不过,Redis 在 listNode 结构体基础上又封装了 list 这个数据结构,这样操作起来会更方便,链表结构如下:
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
举个例子,下面是由 list 结构和 3 个 listNode 结构组成的链表。

链表的优势与缺陷
Redis 的链表实现优点如下:
listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表;
list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头节点和表尾节点的时间复杂度只需O(1);
list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需O(1);
listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值;
链表的缺陷也是有的:
链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。
因此,Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
不过,压缩列表存在性能问题(具体什么问题,下面会说),所以 Redis 在 3.2 版本设计了新的数据结构 quicklist,并将 List 对象的底层数据结构改由 quicklist 实现。
然后在 Redis 5.0 设计了新的数据结构 listpack,沿用了压缩列表紧凑型的内存布局,最终在最新的 Redis 版本,将 Hash 对象和 Zset 对象的底层数据结构实现之一的压缩列表,替换成由 listpack 实现。
ziplist(压缩列表)
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,
这种方法可以有效地节省内存开销。
压缩列表的缺陷也是有的:
不能保存过多的元素,否则查询效率就会降低;
新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
压缩列表结构设计
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。

压缩列表在表头有三个字段:
zlbytes,记录整个压缩列表占用内存字节数;
zltail,记录压缩列表 tail【尾部节点】距离起始地址由多少字节,也就是列表尾的偏移量;
zllen,记录压缩列表包含的 entry 节点数量;
entry,压缩列表中的节点;
zlend,标记压缩列表的结束点,固定值 0xFF
ZipList的结构:
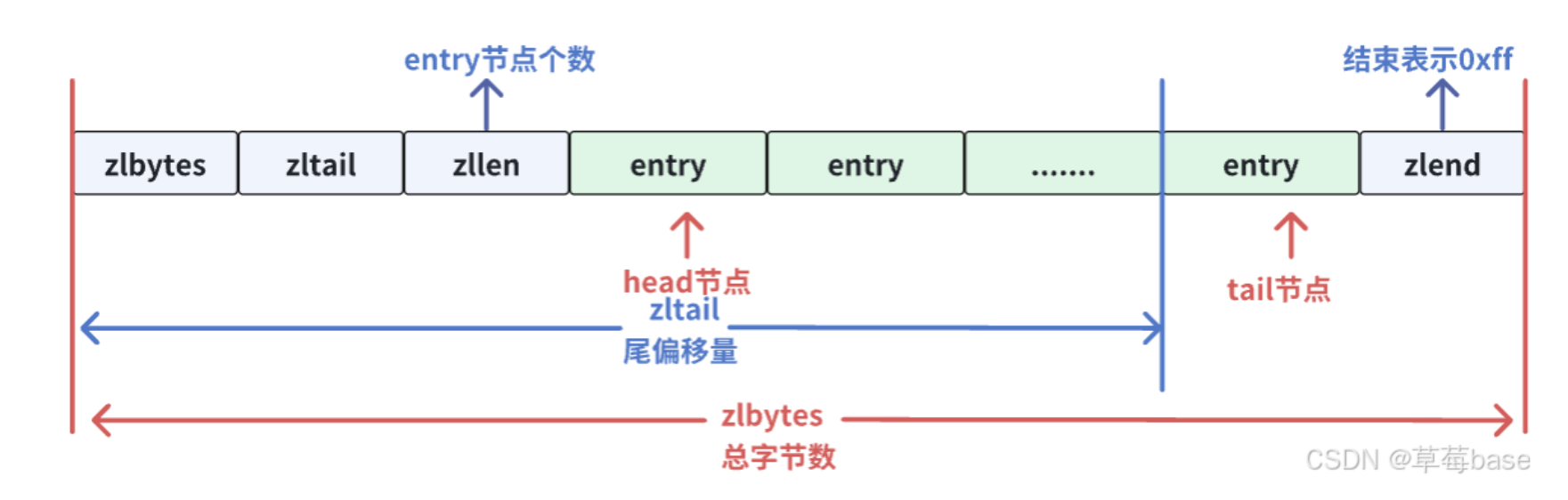
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。
而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
另外,压缩列表节点(entry)的构成如下:
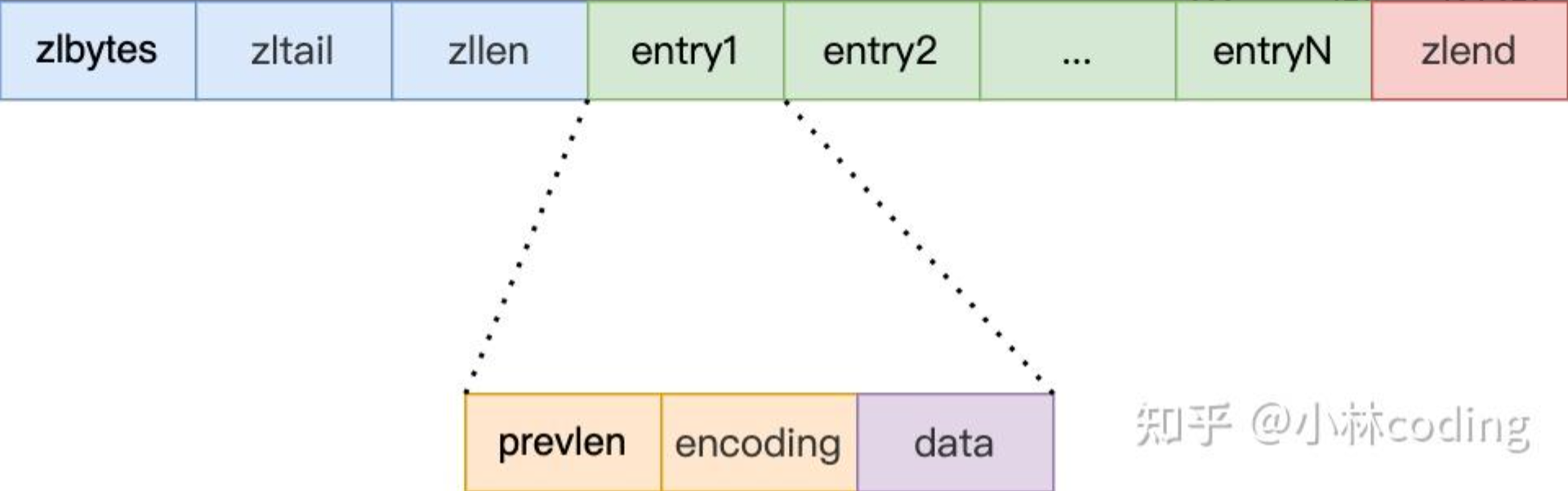
压缩列表节点包含三部分内容:
prevlen,记录了【前一个节点】的长度;
encoding,记录了当前节点实际数据的类型以及长度;
data,记录了当前节点的实际数据;
当我们往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,
这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关:
如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码。
如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码。
连锁更新
压缩列表除了查找复杂度高的问题,还有一个问题。
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,
可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
前面提到,压缩列表节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图:

因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值。
这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为 e1 的前置节点,如下图:

因为 e1 节点的 prevlen 属性只有 1 个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,
并将 e1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。
多米诺牌的效应就此开始。

e1 原本的长度在 250~253 之间,因为刚才的扩展空间,此时 e1 的长度就大于等于 254 了,因此原本 e2 保存 e1 的 prevlen 属性也必须从 1 字节扩展至 5 字节大小。
正如扩展 e1 引发了对 e2 扩展一样,扩展 e2 也会引发对 e3 的扩展,而扩展 e3 又会引发对 e4 的扩展.... 一直持续到结尾。
这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」,就像多米诺牌的效应一样,第一张牌倒下了,推动了第二张牌倒下;第二张牌倒下,又推动了第三张牌倒下....,
压缩列表的缺陷
空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
虽说如此,Redis 针对压缩列表在设计上的不足,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。
这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
Redis底层数据结构 链表的更多相关文章
- Redis 底层数据结构介绍
Redis 底层数据结构 版本:2.9 支持的数据类型: 字符串 散列 列表 集合 有序集合 字符串 Redis 利用原生的 c 字符串进行了一次封装.封装的字符串叫做简单动态字符串:SDS(simp ...
- Redis底层数据结构详解
上一篇说了Redis有五种数据类型,今天就来聊一下Redis底层的数据结构是什么样的.是这一周看了<redis设计与实现>一书,现来总结一下.(看书总是非常烦躁的!) Redis是由C语言 ...
- redis底层数据结构之快速列表(quicklist)
快速列表(quicklist) redis3 .2版本之前,List类型数据使用的底层数据结构是压缩列表(ziplist)或双向链表(linkedlist),当列表元素个数比较少并且每个元素占用空间比 ...
- 【redis】redis底层数据结构原理--简单动态字符串 链表 字典 跳跃表 整数集合 压缩列表等
redis有五种数据类型string.list.hash.set.zset(字符串.哈希.列表.集合.有序集合)并且自实现了简单动态字符串.双端链表.字典.压缩列表.整数集合.跳跃表等数据结构.red ...
- Redis学习笔记(二)redis 底层数据结构
在上一节提到的图中,我们知道,可以通过 redisObject 对象的 type 和 encoding 属性.可以决定Redis 主要的底层数据结构:SDS.QuickList.ZipList.Has ...
- redis底层数据结构之双向链表(linkedlist)
双向链表(linkedlist) redis的双向链表(linkedlist)是基于链表的一种数据结构 链表是一种常见的基础数据结构,是一种非顺序存储数据的线性表,在每一个节点里存储了下一个节点的指针 ...
- redis底层数据结构之字典(dict)
字典(dict) 字典又称为符号表或者关联数组.或映射(map),是一种用于保存键值对(key-value)的抽象数据结构 字典中的每个key都是唯一的,通过key对值来进行查找或修改,时间复杂度为 ...
- redis底层数据结构--简单动态字符串 链表 字典 跳跃表 整数集合 压缩列表
1.动态字符串 redis中使用c语言的字符床存储字面量,默认字符串存储采用自己构建的简单动态字符串SDS(symple dynamic string) redis包含字符串的键值对都是用SDS实现的 ...
- redis 列表的底层数据结构链表
当一个列表键包含了数量比较多的元素,又或者列表中包含的的元素都是比较长的字符串,Redis就会使用链表作为列表键的底层实现 每个列表节点的数据结构为 列表数据接口中保存了 该节点前置节点的指针.后置节 ...
- Redis 底层数据结构之链表
文章参考:<Redis设计与实现>黄建宏 链表 链表提供了高效的节点重排能力,以及可以顺序访问,也可以通过增删节点灵活调整链表长度,Redis中的列表.发布订阅.慢查询.监视器等功能均用到 ...
随机推荐
- k8s~控制deamonset中pod的数量
DaemonSet 是 Kubernetes 中的一种控制器,用于确保集群中的每个节点(或特定标签选择器匹配的节点)运行一个 Pod 的副本.DaemonSet 通常用于运行集群守护进程,如日志收集. ...
- C#数据结构与算法入门实战指南
前言 在编程领域,数据结构与算法是构建高效.可靠和可扩展软件系统的基石.它们对于提升程序性能.优化资源利用以及解决复杂问题具有至关重要的作用.今天大姚分享一些非常不错的C#数据结构与算法实战教程,希望 ...
- 份额大涨! 天翼云稳居中国公有云laaS市场、laaS+PaaS市场第三!
近日,国际数据公司(IDC)最新发布的<公有云市场数据跟踪,2023Q3>报告显示,在公有云整体市场增速全面收紧的背景下,中国电信天翼云市场份额大涨,中国公有云IaaS市场份额增长至12. ...
- MTV和MVC模式,初识模板
MTV和MVC模式,初识模板1.MTV和MVC模式:分层级进行管理 说到框架模式我们有必要简单的说下设计模式,了解下设计模式这个概念,因为有人对设计模式和框架模式的概念经常混淆 设计模式: 是一套被反 ...
- CAD内核的奥秘 | 工业软件发展史 (转)
CAD内核的奥秘 | 工业软件发展史 (声明:此文非本人原著,仅供交流,如果侵犯到原作者权利,立即删除) 如果一个产业要寻根,就会发现一个万千世界,最后会聚焦到一个点上. "一沙一世界&qu ...
- QT5笔记: 20. QStringListModel的使用
主要为 :添加.插入.修改.删除.清空等操作 例子:本例子中QListView 没有做任何处理,只是拖放至ui文件,设置了布局 MainWindow.h #ifndef MAINWINDOW_H #d ...
- autMan奥特曼机器人-autMan的PHP环境
直装版请自行安装php环境. docker版本预置了php环境,如下图: 如果使用插件"test php"测试环境时,实时日志有报错如下: 可进入终端,输入两条命令 apk add ...
- 深入解析:Jupyter Notebook 中魔法命令的使用技巧与应用
Jupyter Notebook 中的魔法命令为用户提供了诸多便利功能.魔法命令主要分为行魔法(Line magic)和单元魔法(Cell magic),行魔法前缀为"%",单元魔 ...
- hbase - [05] hbase关联hive
一.配置 1.在hive的配置文件中配置HBASE_HOME(conf/hive-env.sh) export HBASE_HOME=/opt/module/hbase 2.将 conf/hive-e ...
- mysql扫描全表更新状态部分失败
1. mysql排序问题 一直以为mysql是按照主键排序的,实则排序和主键没有关系(不使用 order by 子句). 然后从 stackoverflow 上查了一下,找到了以下的回答: 没有默认的 ...