卡掉hash的方法
大质数hash
通常,这个质数会选择在 \(10^9\) 附近,如 \(998244353\),\(10^9+7\)。
考虑生日碰撞,欲达到 50% 成功率,需要尝试的次数为
Q(H)\approx\sqrt{\frac\pi2H}\approx39623
\end{align}
\]
可以参考概率表
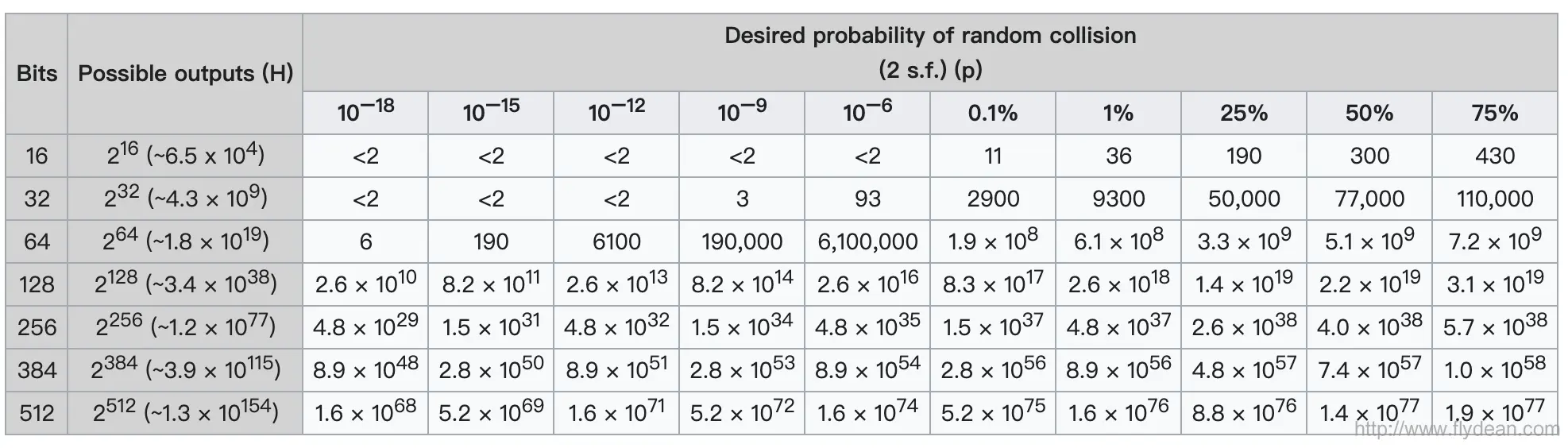
所以我们可以生成 \(10^5\) 左右个较短的字符串,即可有很大的概率发生hash冲突。
Code
#include<iostream>
#include<algorithm>
#include<cstring>
#include<map>
#include<vector>
#include<limits.h>
#define LL long long
#define ULL unsigned long long
using namespace std;
vector<string> create(unsigned num,unsigned int sze)
{
vector<string>ans;
while(num--)
{
string str;
for(unsigned int i=0;i<sze;i++)
{
str.push_back('a'+rand()%26);
}
ans.push_back(str);
}
return ans;
}
bool check(vector<string>strs,ULL base,ULL p)
{
// sort(strs.begin(),strs.end());
map<int,string>Map;
for(unsigned int i=0;i<strs.size();i++)
{
ULL x=0;
for(unsigned int j=0;j<strs[i].size();j++)
{
x=x*base+strs[i][j]-'a';
x%=p;
}
if(Map.find(x)==Map.end()) Map[x]=strs[i];
else
{
if(Map[x]!=strs[i]) return 1;
}
}
return 0;
}
int main()
{
srand(time(0));
int T=100,succ=0;
for(int t=0;t<T;t++)
{
vector<string>strs=create(100000,10); // 生成100000个长度为10的随机字符串
bool c=check(strs,31,998244853); // base=31,p=998244353,检查是否存在hash冲突
cout<<c<<endl;
succ+=c;
}
cout<<succ<<"/"<<T<<endl;
return 0;
}
试运行发现,设置字符串数量为\(39623\)时,发生hash冲突的概率近似\(50\%\),符合预期。而当设置字符串数量为\(100000\)时,\(1000\)次测试中只有\(4\)次没有发生hash冲突。所以设置\(10^5\)个字符串就差不多可以卡掉绝大多数单大质数hash了。
64位无符号整数自然溢出
首先需要对base奇偶性分类讨论。
当base是偶数时比较简单:设第 \(i\) 位指的是字符串从右往左数第 \(i\) 个字符,设有相同串 \(C\) ,其长度不小于64.构造字符串 \(A=a+C,B=b+C\),这两个字符串的后64位上均相同,更高位上不相同。
字符串中第 \(i\) 位的权重为 \(base^{i-1}\),则高于64位上的字符的权重一定可以被 \(2^{64}\) 整除。也就是说,高于64位上的字符不会对hash值产生影响。
下面着重说一下base为奇数的情况。
构造方法
考虑使用字符a和b构造字符串:
记 \(\overline A\) 表示字符串 \(A\) 中所有 a 变成 b ,所有 b 变成 a。
记 \(A_1=a\),\(A_i=A_{i-1}+\overline{A_{i-1}}\)
例如 \(A_2=ab,A_3=abba,A_4=abbabaab\)
那么\(len(A_i)=2^{i-1}\)
可以证明,当 \(i\) 大于某个数时,\(hash(A_i)=hash(\overline{A_i})\)
证明
由于我们的hash函数使用的是64位无符号整数自然溢出,所以相当于我们需要证明
2^{64}\mid(hash(A_i)-hash(\overline{A_i}))
\end{align}
\]
设\(f(i)=hash(A_i)-hash(\overline{A_i})\)
根据递推公式可得
hash(A_i)&=hash(A_{i-1})\times base^{len(A_{i-1})}+hash(\overline{A_{i-1}})\\
&=hash(A_{i-1})\times base^{2^{i-2}}+hash(\overline{A_{i-1}})
\end{align}
\]
则有
f(i)&=(hash(A_{i-1})-hash(\overline{A_{i-1}}))\times base^{2^{i-2}}+(hash(\overline{A_{i-1}})-hash(A_{i-1}))\\
&=(hash(A_{i-1})-hash(\overline{A_{i-1}}))\times (base^{2^{i-2}}-1)\\
&=f(i-1)\times (base^{2^{i-2}}-1)
\end{align}
\]
设\(g(i)=base^{2^{i-2}}-1(i\ge2)\)
则有
f(i)&=f(i-1)\times g(i)\\
&=f(i-2)\times g(i) \times g(i-1)\\
&=f(1)\times g(i)\times g(i-1)\times g(i-2)\times\dots\times g(2)
\end{align}
\]
由于 \(base\) 是奇数,所以 \(base^{2^{i-2}}\) 也是奇数,故 \(g(i)\) 是偶数。
故有
2^{i-1}\mid f(i)
\end{align}
\]
为了达到\(2^{64}\mid f(i)\),需取\(i=65\)即可,但是这样会构造两个长度为\(2^{64}\approx10^{20}\)的字符串,是不可行的。
由于\(g(i)=base^{2^{i-2}}-1=(base^{2^{i-3}}+1)(base^{2^{i-3}}-1)=偶数*g(i-1)\)
所以有
2^{i-1} & \mid g(i)\\
2^\frac{i(i-1)}{2} & \mid f(i)
\end{align}
\]
我们需要\(\frac{i(i-1)}{2}\ge64\),则只需取\(i=12\),构造出字符串 \(A_{12}\) 和 \(\overline{A_{12}}\),即可卡掉base为奇数的自然溢出。
最后,在这两字符串后再加上长度大于等于64的相同串,即可同时卡掉base为偶数的自然溢出。
Code
#include<iostream>
#include<string>
#include<cmath>
#include<map>
#include<vector>
#include<limits.h>
#define ULL unsigned long long
using namespace std;
string C;
string create()
{
string str="a";
for(int i=2;i<=11;i++) // 会产生长度为2^(i-1)长度的字符串,而我们需要i_max=12
{
for(int j=0;j<(1<<(i-2));j++) //延拓字符串长度为1<<(i-1)
{
str.push_back(str[j]=='a'?'b':'a');
}
}
return str;
}
string Not(string str)
{
for(unsigned int i=0;i<str.size();i++)
{
str[i]=(str[i]=='a'?'b':'a');
}
return str;
}
bool check(string a,string b,ULL base)
{
ULL aa=0,bb=0;
for(unsigned int i=0;i<a.size();i++)
{
aa=aa*base+a[i]-'a';
}
for(unsigned int i=0;i<b.size();i++)
{
bb=bb*base+b[i]-'a';
}
return aa==bb;
}
int main()
{
for(int i=1;i<=65;i++) C.push_back('a');
string str=create();
string A=str+C,B=Not(str)+C;
cout<<"构造的字符串的长度为"<<A.size()<<endl;
int T=10000,succ=0;
for(int t=0;t<T;t++)
{
bool c=check(A,B,t*2+1);
cout<<c<<endl;
succ+=c;
}
cout<<succ<<"/"<<T<<endl;
return 0;
}
疑惑:为什么这里取 \(i=11\) 就可以了?
我在研究的过程中,发现取 \(i=11\) 时,对于测试的所有奇数base都成功了。但是明明证明的是 \(i\) 最小取 \(12\)?最后由lzh揭开了谜团。
\(g(3)\) 很特别:\(g(3)=base^{2^{3-2}}-1=base^2-1\)
由于base是奇数,设\(base=2n-1(n\ge1)\),有
g(3)=(2n-1)^2-1=4n^2-4n=4n(n+1)
\end{align}
\]
一定是8的倍数。故 \(2^3 \mid g(3)\)。
再结合递推公式,有
\begin{cases}
2^{i} \mid g(i)\quad i\ge3\\
2^1 \mid g(i)\quad i=2\\
\end{cases}
\end{align}
\]
所以有
2^{\frac{(3+i)(i-2)}{2}+1} \mid f(x)
\end{align}
\]
当 \(i=11\)时,刚好是\(2^{64}\)(真巧!)
如何避免被卡
- 随机base。相当于让不同位置上的权重不一样
- 双模数hash。
- 超大质数hash。既能像自然溢出一样有着大值域不易生日攻击,又不会被特殊的构造卡掉。
卡掉hash的方法的更多相关文章
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- centos LB负载均衡集群 三种模式区别 LVS/NAT 配置 LVS/DR 配置 LVS/DR + keepalived配置 nginx ip_hash 实现长连接 LVS是四层LB 注意down掉网卡的方法 nginx效率没有LVS高 ipvsadm命令集 测试LVS方法 第三十三节课
centos LB负载均衡集群 三种模式区别 LVS/NAT 配置 LVS/DR 配置 LVS/DR + keepalived配置 nginx ip_hash 实现长连接 LVS是四层LB ...
- 查看kindle paperwhite2上卡索引书籍的方法
昨天kindle耗电量突然加快,经过检查和网络搜索得知是卡索引导致的耗电量增大.我自己通过关闭索引的方式解决了这个问题. 在这个过程中发现了一个可以直接找到所有卡索引书籍的方法,在此分享一下. 首先打 ...
- 内网技巧-通过SAM数据库获得本地用户hash的方法
内网技巧-通过SAM数据库获得本地用户hash的方法 在windows上的C:\Windows\System32\config目录保存着当前用户的密码hash.我们可以使用相关手段获取该hash. 提 ...
- ViewPager实现页卡的3种方法(谷歌组件)
----方法一:---- 效果图: 须要的组件: ViewPager+PagerTabStrip 布局文件代码: <!--xmlns:android_custom="http://sc ...
- 3D VR卡镜的使用方法
先把它展开 然后把它卡在手机中间 介绍一个VR游戏资源 Chair In a Room,这是一个立体沉浸式的3D游戏,原理是陀螺仪传感器随着手机转动可以观察整个三维房间 如图所示,点击进入,将两眼放到 ...
- 防止Android程序被系统kill掉的处理方法
转载请注明出处:http://blog.csdn.net/cuiran/article/details/38851401 目前遇到一个问题程序需要一直运行,并显示在最前端,但是运行一段时间发现会被系统 ...
- c# 运行大运算程序主窗体卡掉的解决
写了一个运算过滤大文本的程序, 其中方法里边使用了多线程,并行线程等方法. 但主窗体控件直接使用此方法时,页面卡顿.所以主线程被堵塞. 代码如下, splitfile 这个方法运行时页面卡顿,阻塞了 ...
- MySQL提权之user.MYD中hash破解方法
经常在服务器提权的时候,尤其是windows环境下,我们发现权限不高,却可以读取mysql的datadir目录,并且能够成功下载user.MYD这个文件.但是在读取内容的时候,经常会遇到root密码h ...
- 解决hash冲突方法
转自:https://www.cnblogs.com/wuchaodzxx/p/7396599.html 目录 开放定址法 线性探测再散列 二次探测再散列 伪随机探测再散列 再哈希法 链地址法 建立公 ...
随机推荐
- es6 export和export default的区别
相同点 export 与 export default 均可用于导出常量.函数.文件.模块 可在其它文件或模块中通过import+(常量 | 函数 | 文件 | 模块)名的方式,将其导入,以便能够对其 ...
- go 定时任务库 cron
简介 在Linux中,Cron是计划任务管理系统,通过crontab命令使任务在约定的时间执行已经计划好的工作,例如定时备份系统数据.周期性清理缓存.定时重启服务等. 本文介绍的cron库是一个用于管 ...
- pandas(进阶操作)-- 政治献金项目数据分析
博客地址:https://www.cnblogs.com/zylyehuo/ 开发环境 anaconda 集成环境:集成好了数据分析和机器学习中所需要的全部环境 安装目录不可以有中文和特殊符号 jup ...
- centos7 挂载未分配的硬盘空间 (测试可用)
=============================================== 2019/7/28_第1次修改 ccb_warlock == ...
- Mac 刷题环境配置
Mac 刷题环境配置 这篇博文主要记录自己为了更方便的在 Mac 上写算法题,主要是基于 Clion做的一些环境配置:有些操作其实在 Windows ,Linux 下也是通用的,如果看到的小伙伴也可以 ...
- 支持VS2022的包发布工具NuPack 2022发布
我们很高兴地宣布 NuPack 2022 正式发布!这是一个开源项目,旨在简化 .NET 开发中的 NuGet 包发布流程. NuPack 是什么? NuPack 是一个轻量级工具,VS扩展,它可以帮 ...
- Visual Studio 自定义项目模版
以 Visual Studio 2017 为例. 在 Visual Studio 中用户项目模版就是我们俗称的自定义项目模版. 用户项目模版位置 在Visual Studio中打开[工具-选项-项目和 ...
- 如何优化和提高MaxKB回答的质量和准确性?
目前 ChatGPT.GLM等生成式人工智能在文本生成.文本到图像生成等在各行各业的都有着广泛的应用,但是由于大模型训练集基本都是构建于网络公开的数据,对于一些实时性的.非公开的或离线的数据是无法获取 ...
- 理解PostgreSQL和SQL Server中的文本数据类型
理解PostgreSQL和SQL Server中的文本数据类型 在使用PostgreSQL时,理解其文本数据类型至关重要,尤其对有SQL Server背景的用户而言.尽管两个数据库系统都支持文本存储, ...
- 面试官:如果某个业务量突然提升100倍QPS你会怎么做?
"假设你负责的系统,某个业务线的QPS突然暴增100倍,你会怎么应对?" --这是上周朋友去面试,被问到一道题,他答了"加机器扩容",结果面试官眉头一皱:&qu ...