svtools prune具体算法
svtools具有不同的子命令以实现不同的功能,其中一个就是lmerge。根据其help信息(cluster and prune a BEDPE file by position based on allele frequency)可以看出,它是对BEDPE文件内的变异进行聚类和修剪的。
zcat ${input_vcf_gz} | svtools afreq | svtools vcftobedpe | svtools bedpesort | svtools prune -s -d 100 -e 'AF' | svtools bedpetovcf
这里是svt-pipeline所用的命令,一共分为afreq、vcftobedpe、bedpesort、prune、bedpetovcf几个步骤。这对这几个步骤分别进行解释。
(1) afreq
这一步主要是对vcf文件添加一个等位频率的信息,即AF。我们这里所输入vcf文件是没有等位频率信息的,prune的修剪又是基于等位频率的,所以这里首先加上等位频率的信息。

图1.afreq执行之后的vcf INFO信息
上图所示,是afreq执行之后的vcf文件INFO信息,其中标红的位置是新加信息。添加了AF、NSAMP和MSQ信息。它们的含义可以在vcf文件的header部分找到,它们所代表的含义为:
AF, Description="Allele Frequency, for each ALT allele, in the same order as listed“
NSAMP, Description="Number of samples with non-reference genotypes"
MSQ, Description="Mean sample quality of positively genotyped samples"
这就是afreq所要做的。
(2) vcftobedpe
vcftobedpe即把vcf文件转换为bedpe文件,这两个文件在变异描述的格式上有所不同,而prune是针对bedpe文件进行变异聚类和修剪的,所以要把文件格式进行转换。
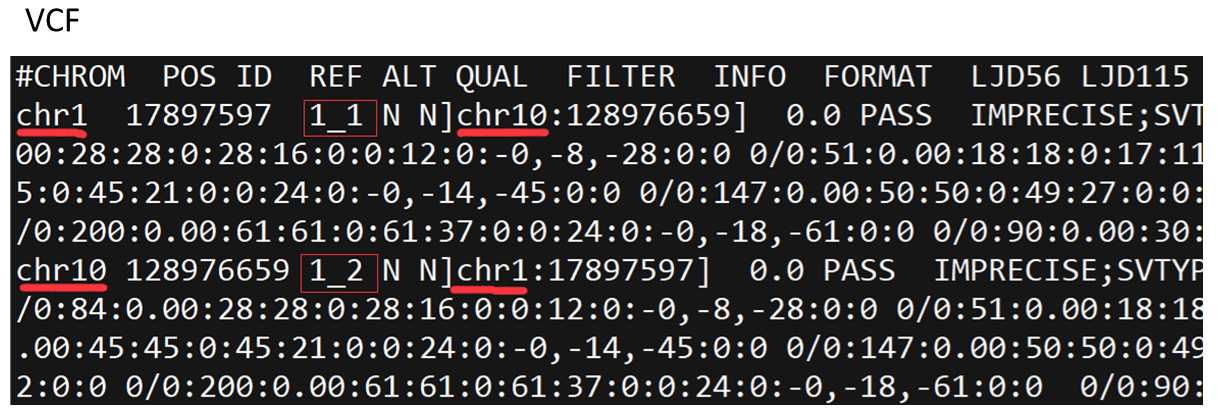
图2. 输入vcf文件

图3. 转换后的BEDPE文件
从图中可以看出,这里输入的vcf文件使用两行表示了同一个变异,使用1_1和1_2进行区分,但是在BEDPE文件中把这两行合并到了一行。
(3) bedpesort
bedpesort是对bedpe文件的排序。下图是对bedpe文件进行排序的方法,可以看出是按前6列逐次进行的排序,即左侧染色体、左侧起始位置、左侧终止位置、右侧染色体、右侧起始位置、右侧终止位置。

图4. Bedpe排序方法
(4) prune
接下来就是对已排序的bedpe文件进行聚类和修剪。在prune命令中会有三个常用的参数:-s,指定输入文件是经过排序的;-d指定一个碱基长度范围,用于后续聚类;-e指定一个指标,用于评估一个聚类内最优变异记录。
在把vcf文件转换为bedpe文件后,每个变异记录会有左侧起始位置、左侧终止位置和右侧起始位置、右侧终止位置,所有就构成了两个区间。Prune命令会按照-d参数指定的长度对这两个区间左右进行扩展,然后把这两个区间同时有重叠的变异记录放在一起成为一个聚类。然后遍历每个聚类内的记录,选择AF最大的那个记录作为最优记录,然后把其他记录里的SNAME信息添加到最优记录里,再把其他记录删除掉,作为修剪。
(5) bedpetovcf
最后就是把bedpe文件重新转换为vcf文件。
svtools prune具体算法的更多相关文章
- 关联规则算法Apriori的学习与实现
转自关联规则算法Apriori的学习与实现 首先我们来看,什么是规则?规则形如"如果-那么-(If-Then-)",前者为条件,后者为结果.关联规则挖掘用于寻找给定数据集中项之间的 ...
- Frequent Pattern 挖掘之一(Aprior算法)(转)
数据挖掘中有一个很重要的应用,就是Frequent Pattern挖掘,翻译成中文就是频繁模式挖掘.这篇博客就想谈谈频繁模式挖掘相关的一些算法. 定义 何谓频繁模式挖掘呢?所谓频繁模式指的是在样本数据 ...
- 【机器学习实战 第九章】树回归 CART算法的原理与实现 - python3
本文来自<机器学习实战>(Peter Harrington)第九章"树回归"部分,代码使用python3.5,并在jupyter notebook环境中测试通过,推荐c ...
- Mahout推荐算法之SlopOne
Mahout推荐算法之SlopOne 一. 算法原理 有别于基于用户的协同过滤和基于item的协同过滤,SlopeOne采用简单的线性模型估计用户对item的评分.如下图,估计UserB对 ...
- Aprior算法
在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库.于是人们提出了各种裁剪(prune)数据集的方法以减少I/O开支,韩嘉炜老师的FP-Tree算法就是其中非常高效 ...
- 关联分析Apriori算法和FP-growth算法初探
1. 关联分析是什么? Apriori和FP-growth算法是一种关联算法,属于无监督算法的一种,它们可以自动从数据中挖掘出潜在的关联关系.例如经典的啤酒与尿布的故事.下面我们用一个例子来切入本文对 ...
- python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法.ID3算法,C4.5算法可以生成二叉树或者多叉树 ...
- 03机器学习实战之决策树CART算法
CART生成 CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支.这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有 ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
随机推荐
- 写代码被大语言模型坑之使用LocalDateTime比较两个时间差了几天
自从去年ChatGPT3.5发布后使用了几次,现在写代码基本上离不开它和它的衍生产品们了.一方面查资料很方便,快速提炼要点总结:另一方面想写什么样的代码一问就能生成出来,功能大差不差,稍微改改就能用, ...
- K-Means(聚类算法)【转载】
聚类##### 今天说聚类,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别. 分类其实是从特定的数据中挖掘模式,作出判断的过程.比如Gmail邮 ...
- uni-app 监听返回按钮
前置条件: 开发环境:windows 开发框架:uni-app , H5+,nativeJS 编辑器:HbuilderX 2.8.13 4. 兼容版本:安卓,IOS已作测试 进入正题: 文档地址uni ...
- 工作中的技术总结_ form表单的前后台交互 _20210825
工作中的技术总结_ form表单的前后台交互 _20210825 在项目经常会使用 form 表单 进行数据的 页面展示 以及数据的 提交和后台处理 1.数据是怎么从后台传递到前台的 model.ad ...
- python实现基于RPC协议的接口自动化测试
01什么是RPC RPC(Remote Procedure Call)远程过程调用协议是一个用于建立适当框架的协议.从本质上讲,它使一台机器上的程序能够调用另一台机器上的子程序,而不会意识到它是远程的 ...
- C++之OpenCV入门到提高004:Mat 对象的使用
一.介绍 今天是这个系列<C++之 Opencv 入门到提高>得第四篇文章.这篇文章很简单,介绍如何使用 Mat 对象来实例化图像实例,了解它的构造函数和常用的方法,这是基础,为以后的学习 ...
- ChatGPT:编程的 “蜜糖” 还是 “砒霜”?告别依赖,拥抱自主编程的秘籍在此!
在当今编程界,ChatGPT 就像一颗耀眼却又颇具争议的新星,它对编程有着不可忽视的影响.但这影响就像一把双刃剑,使用不当,就可能让我们在编程之路上"受伤". 一.过度依赖 Cha ...
- MoD:轻量化、高效、强大的新型卷积结构 | ACCV'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处 论文: CNN Mixture-of-Depths 论文地址:https://arxiv.org/abs/2409.17016 创新点 提出新的卷积轻 ...
- Ubuntu 无法播放MP4
今天用ubuntu打开mp4发现无法播放,然后我以为文件损坏了,就传到手机上面,发现还是可以播放的,然后就查了一下相关资料,发现有人让我安装这个 sudo snap install ffmpeg 安装 ...
- 初见memcached
一. 概念 Memcached是danga.com(运营LiveJournal的技术团队)开发的一套分布式内存对象缓存系统,用于在动态系统中减少数据库负载,提升性能. 二. 适用场合 1. 分布式应用 ...