Hadoop 完全分布式搭建
搭建环境
https://www.cnblogs.com/YuanWeiBlogger/p/11456623.html
修改主机名
-------------------
1./etc/hostname
s129
2./etc/hosts
127.0.0.1 localhost
192.168.248.129 s129
192.168.248.128 s128
192.168.248.127 s127
192.168.248.126 s126
完全分布式
1.克隆3台client(centos6.8)
右键centos-->管理->克隆-> ... -> 完整克隆
2.启动client
3.启用客户机共享文件夹。
4.修改hostname和ip地址文件
[/etc/hostname]
s127
[/etc/sysconfig/network-scripts/ifcfg-ethxxxx]
...
IPADDR=..
5.重启网络服务
$>sudo service network restart
6.修改/etc/resolv.conf文件
nameserver 192.168.231.2
7.重复以上3 ~ 6过程.
准备完全分布式主机的ssh
-------------------------
1.删除所有主机上的/home/yw/.ssh/*
2.在s129主机上生成密钥对
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
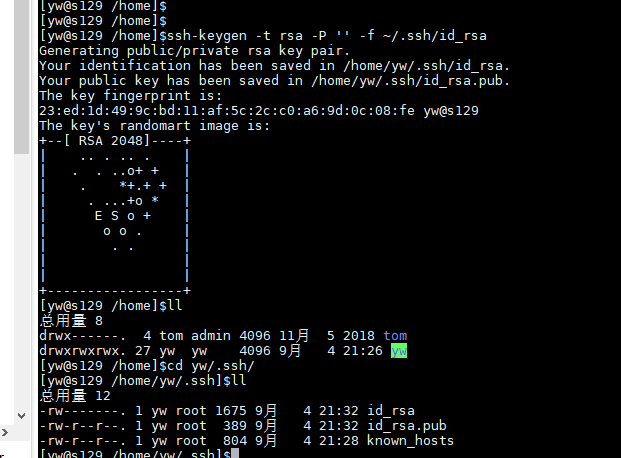
3.将s129的公钥文件id_rsa.pub远程复制到126 ~128主机上。
并放置/home/yw/.ssh/authorized_keys
$>scp id_rsa.pub yw@s129:/home/yw/.ssh/authorized_keys
$>scp id_rsa.pub yw@s128:/home/yw/.ssh/authorized_keys
$>scp id_rsa.pub yw@s127:/home/yw/.ssh/authorized_keys
$>scp id_rsa.pub yw@s126:/home/yw/.ssh/authorized_keys
4.配置完全分布式(${hadoop_home}/etc/hadoop/)

修改完全分布式的xml文件
[core-site.xml]
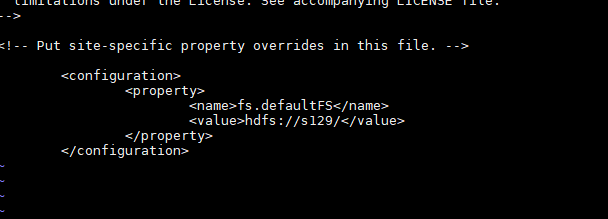
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s129/</value>
</property>
</configuration>
[hdfs-site.xml]
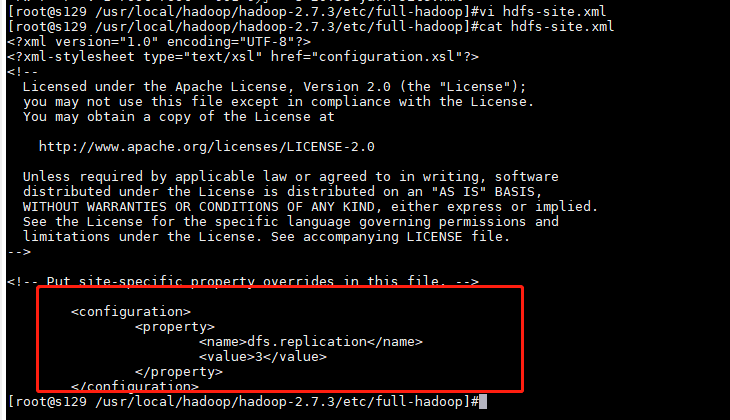
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
[mapred-site.xml]
不变
[yarn-site.xml]
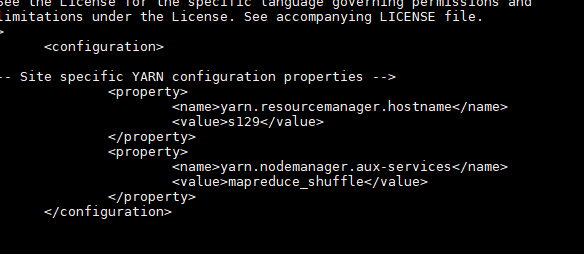
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s129</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
[slaves]
s128
s127
s126

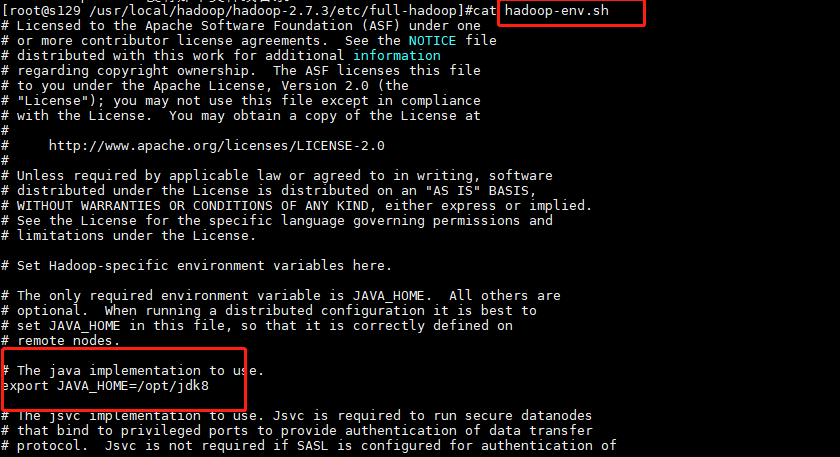
[hadoop-env.sh]
...
export JAVA_HOME=/opt/jdk

...
5.分发配置
$>cd /usr/local/hadoop/hadoop-2.7.3/etc

$>scp -r full-hadoop root@s128:/usr/local/hadoop/hadoop-2.7.3/etc/

$>scp -r full-hadoop root@s127:/usr/local/hadoop/hadoop-2.7.3/etc/
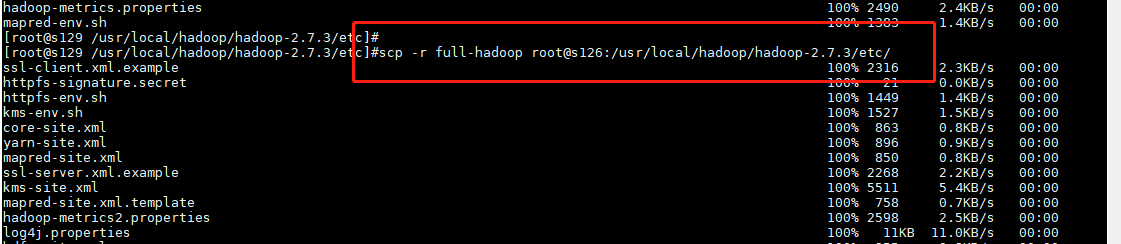
$>scp -r full-hadoop root@s126:/usr/local/hadoop/hadoop-2.7.3/etc/
6.删除符号连接 (把原来的伪分布式连接删掉)
$>cd /usr/local/hadoop/hadoop-2.7.3/etc
$>rm -rf hadoop
$>ssh s128 rm -rf /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/
$>ssh s127 rm -rf /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/
$>ssh s126 rm -rf /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/

7.创建符号连接
$>cd /usr/local/hadoop/hadoop-2.7.3/etc
$>ln -s full-hadoop hadoop
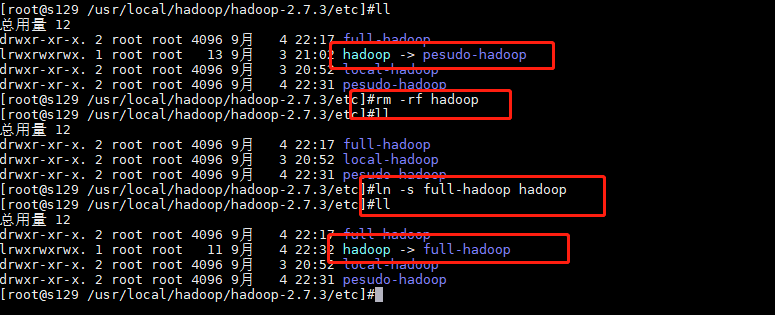
$>ssh s126 ln -s /usr/local/hadoop/hadoop-2.7.3/etc/full-hadoop /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
$>ssh s127 ln -s /usr/local/hadoop/hadoop-2.7.3/etc/full-hadoop /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
$>ssh s128 ln -s /usr/local/hadoop/hadoop-2.7.3/etc/full-hadoop /usr/local/hadoop/hadoop-2.7.3/etc/hadoop

8.删除临时目录文件
$>cd /tmp
$>rm -rf hadoop-centos
$>ssh s128 rm -rf /tmp/hadoop-centos
$>ssh s127 rm -rf /tmp/hadoop-centos
$>ssh s126 rm -rf /tmp/hadoop-centos

9.删除hadoop日志
$>cd /usr/local/hadoop/hadoop-2.7.3/logs
$>rm -rf *
$>ssh s128 rm -rf /usr/local/hadoop/hadoop-2.7.3/logs/*
$>ssh s127 rm -rf /usr/local/hadoop/hadoop-2.7.3/logs/*
$>ssh s126 rm -rf /usr/local/hadoop/hadoop-2.7.3/logs/*

10.格式化文件系统
$>hadoop namenode -format
11.启动hadoop进程
$>start-all.sh
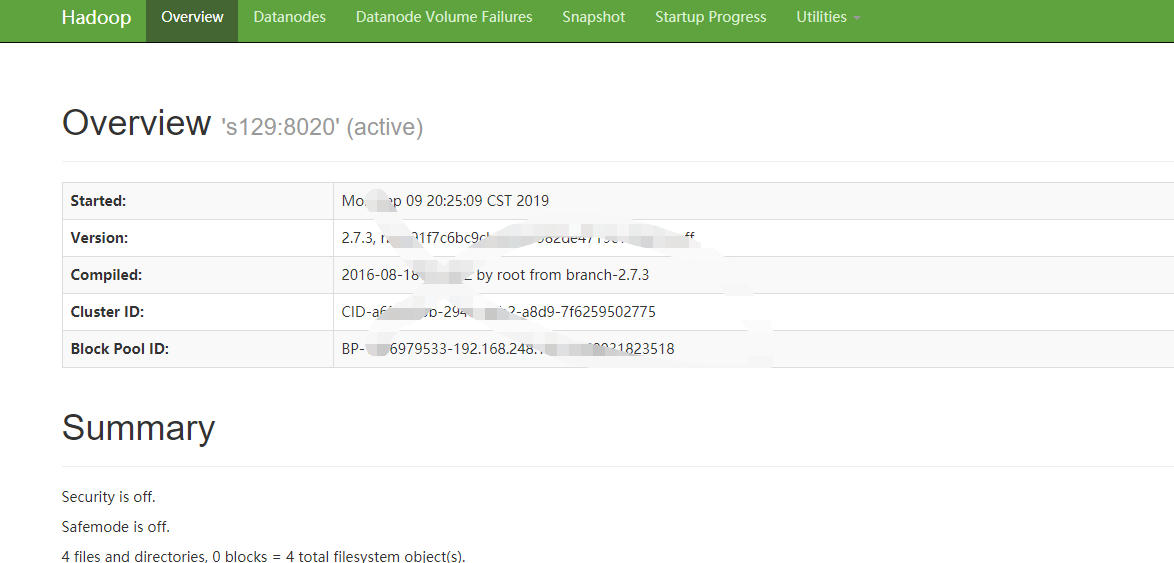
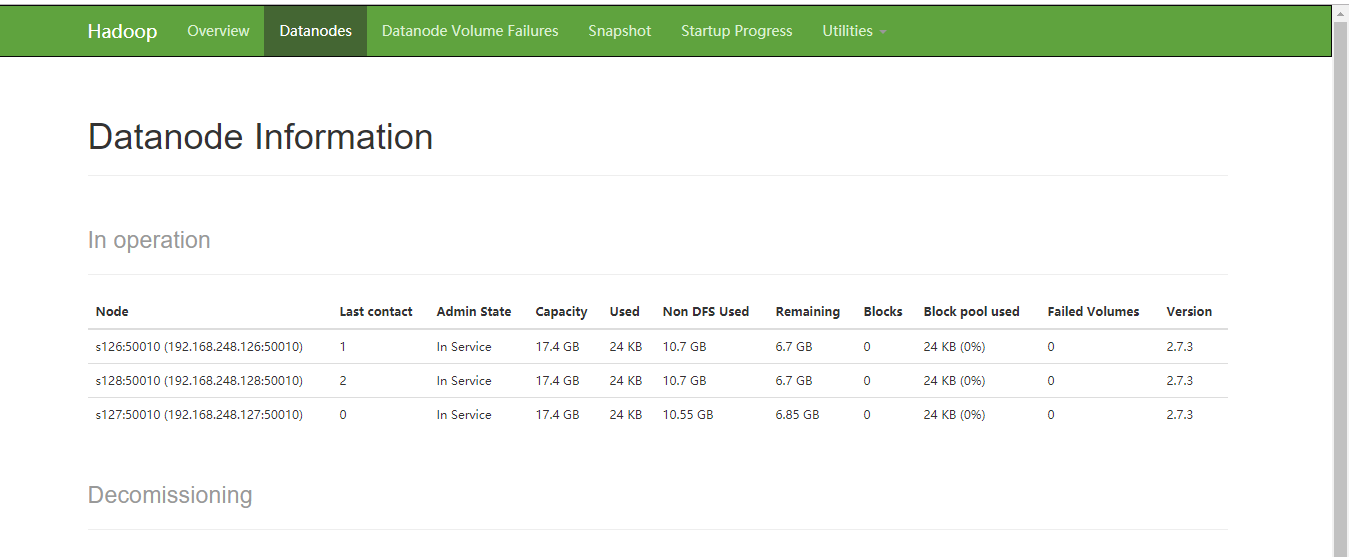
完全分布式搭建完成。
Hadoop 完全分布式搭建的更多相关文章
- hadoop完全分布式搭建HA(高可用)
2018年03月25日 16:25:26 D调的Stanley 阅读数:2725 标签: hadoop HAssh免密登录hdfs HA配置hadoop完全分布式搭建zookeeper 配置 更多 个 ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- 3.hadoop完全分布式搭建
3.Hadoop完全分布式搭建 1.完全分布式搭建 配置 #cd /soft/hadoop/etc/ #mv hadoop local #cp -r local full #ln -s full ha ...
- Hadoop伪分布式搭建(一)
下面内容主要说明在Windows虚拟机上面,怎么搭建一个Hadoop伪分布式,并如何运行wordcount程序和网页查看HDFS文件系统. 1 相关软件下载和安装 APACH官网提供hadoop版本 ...
- Hadoop伪分布式搭建步骤
说明: 搭建环境是VMware10下用的是Linux CENTOS 32位,Hadoop:hadoop-2.4.1 JAVA :jdk7 32位:本文是本人在网络上收集的HADOOP系列视频所附带的 ...
- hadoop 伪分布式搭建
下载hadoop1.0.4版本,和jdk1.6版本或更高版本:1. 安装JDK,安装目录大家可以自定义,下面是我的安装目录: /usr/jdk1.6.0_22 配置环境变量: [root@hadoop ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
- Hadoop完全分布式搭建流程
centos7 搭建完全分布式 Hadoop 环境 SSR 前言 本次教程是以先创建 四台虚拟机 为基础,再配置好一台虚拟机的情况下,直接复制文件到另外的虚拟机中(这样做大大简化了安装流程) 且本次 ...
- Hadoop伪分布式搭建CentOS
所需软件及版本: jdk-7u80-linux-x64.tar.gz hadoop-2.6.0.tar.gz 1.安装JDK Hadoop 在需在JDK下运行,注意JDK最好使用Oracle的否则可能 ...
随机推荐
- win10常用快捷键(热键)总结
win10常用快捷键总结: win+Ctrl+D 创建虚拟桌面 win+Ctrl+左(右)键 切换虚拟桌面 win+Ctrl+F4 关闭虚拟桌面 win+D 隐藏所有窗口/显示所有窗口 win+M 隐 ...
- Java学习笔记-文件读写和Json数组
Java文件读写 Java中I/O流对文件的读写有很多种方法,百度后主要看了以下三种 第一种方式:使用FileWriter和FileReader,对文件内容按字符读取,代码如下 String dir ...
- 肿瘤免疫疗法 | 细胞治疗和PD1/PDL1 | Tumor immunotherapy | cell therapy
人类肿瘤治疗史上的里程碑无疑一定有一座是肿瘤免疫疗法的. 而肿瘤免疫疗法的主要两大领域,细胞治疗以及以PD1/PDL1为代表的免疫检查点抑制剂都在飞速发展. 目前,已经有5种抗PD1/PDL1抗体药物 ...
- LSTM和双向LSTM讲解及实践
LSTM和双向LSTM讲解及实践 目录 RNN的长期依赖问题LSTM原理讲解双向LSTM原理讲解Keras实现LSTM和双向LSTM 一.RNN的长期依赖问题 在上篇文章中介绍的循环神经网络RNN在训 ...
- The Practical Importance of Feature Selection(变量筛选重要性)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- windows下安装anaconda和tensorflow
anaconda确实很好用,省去了很多麻烦,现在我个人推荐直接使用anaconda. anaconda的特点:可以存在多个python环境,要使用某一个环境的话,就需要切换到这个环境,安装.卸载包都是 ...
- Java中使用Socket连接判断Inputstream结束,java tcp socket服务端,python tcp socket客户端
最近在试着用java写一个socket的服务器,用python写一个socket的客户端来完成二者之间的通信,但是发现存在一个问题,服务器方面就卡在读取inputsream的地方不动了,导致后面的代码 ...
- 转 mysql awr 报告
1. https://github.com/noodba/myawr 2. https://www.cnblogs.com/zhjh256/p/5779533.html
- 《Learning a Discriminative Feature Network for Semantic Segmentation》解读
旷世18年的CVPR,论文链接:https://arxiv.org/abs/1804.09337 Motivation:针对分割中的“类内不一致”和“类间一致性”的两大问题,设计了结合Smooth n ...
- c# Invoke的新用法
在C# 3.0及以后的版本中有了Lamda表达式,像上面这种匿名委托有了更简洁的写法..NET Framework 3.5及以后版本更能用Action封装方法.例如以下写法可以看上去非常简洁: voi ...