【转载】 KL距离(相对熵)
原文地址:
https://www.cnblogs.com/nlpowen/p/3620470.html
-----------------------------------------------------------------------------------------------
KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy)。它衡量的是相同事件空间里的两个概率分布的差异情况。其物理意义是:在相同事件空间里,概率分布P(x)对应的每个事件,若用概率分布 Q(x)编码时,平均每个基本事件(符号)编码长度增加了多少比特。我们用D(P||Q)表示KL距离,计算公式如下:
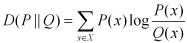
当两个概率分布完全相同时,即P(X)=Q(X),其相对熵为0 。我们知道,概率分布P(X)的信息熵为:

其表示,概率分布P(x)编码时,平均每个基本事件(符号)至少需要多少比特编码。通过信息熵的学习,我们知道不存在其他比按照本身概率分布更好的编码方式了,所以D(P||Q)始终大于等于0的。虽然KL被称为距离,但是其不满足距离定义的三个条件:1)非负性(满足);2)对称性(不满足);3)三角不等式 (不满足)。
我们以一个例子来说明,KL距离的含义。
假如一个字符发射器,随机发出0和1两种字符,真实发出概率分布为A,但实际不知道A的具体分布。现在通过观察,得到概率分布B与C。各个分布的具体情况如下:
A(0)=1/2,A(1)=1/2
B(0)=1/4,B(1)=3/4
C(0)=1/8,C(1)=7/8
那么,我们可以计算出得到如下:
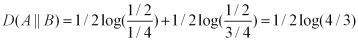
也即,这两种方式来进行编码,其结果都使得平均编码长度增加了。我们也可以看出,按照概率分布B进行编码,要比按照C进行编码,平均每个符号增加的比特数目少。从分布上也可以看出,实际上B要比C更接近实际分布(因为其与A分布的KL距离更近)。
如果实际分布为C,而我们用A分布来编码这个字符发射器的每个字符,那么同样我们可以得到如下:

再次,我们进一步验证了这样的结论:对一个信息源编码,按照其本身的概率分布进行编码,每个字符的平均比特数目最少。这就是信息熵的概念,衡量了信息源本身的不确定性。另外,可以看出KL距离不满足对称性,即D(P||Q)不一定等于D(Q||P)。
当然,我们也可以验证KL距离不满足三角不等式条件。
上面的三个概率分布,D(B||C)=1/4log2+3/4log(6/7)。可以得到:D(A||C) - (D(A||B)+ D(B||C)) =1/2log2+1/4log(7/6)>0,这里验证了KL距离不满足三角不等式条件。所以KL距离,并不是一种距离度量方式,虽然它有这样的学名。
其实,KL距离在信息检索领域,以及统计自然语言方面有重要的运用。
-----------------------------------------------------------------------------------------------
【转载】 KL距离(相对熵)的更多相关文章
- (转载)KL距离,Kullback-Leibler Divergence
转自:KL距离,Kullback-Leibler Divergence KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对 ...
- KL距离(相对熵)
KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy).它衡量的是相同事件空间里的两个概率分 ...
- KL距离,Kullback-Leibler Divergence
http://www.cnblogs.com/ywl925/p/3554502.html http://www.cnblogs.com/hxsyl/p/4910218.html http://blog ...
- [NLP自然语言处理]计算熵和KL距离,java实现汉字和英文单词的识别,UTF8变长字符读取
算法任务: 1. 给定一个文件,统计这个文件中所有字符的相对频率(相对频率就是这些字符出现的概率——该字符出现次数除以字符总个数,并计算该文件的熵). 2. 给定另外一个文件,按上述同样的方法计算字符 ...
- 最大熵与最大似然,以及KL距离。
DNN中最常使用的离散数值优化目标,莫过于交差熵.两个分布p,q的交差熵,与KL距离实际上是同一回事. $-\sum plog(q)=D_{KL}(p\shortparallel q)-\sum pl ...
- 各种形式的熵函数,KL距离
自信息量I(x)=-log(p(x)),其他依次类推. 离散变量x的熵H(x)=E(I(x))=-$\sum\limits_{x}{p(x)lnp(x)}$ 连续变量x的微分熵H(x)=E(I(x)) ...
- [Machine Learning & Algorithm]CAML机器学习系列2:深入浅出ML之Entropy-Based家族
声明:本博客整理自博友@zhouyong计算广告与机器学习-技术共享平台,尊重原创,欢迎感兴趣的博友查看原文. 写在前面 记得在<Pattern Recognition And Machine ...
- 信息熵 Information Theory
信息论(Information Theory)是概率论与数理统计的一个分枝.用于信息处理.信息熵.通信系统.数据传输.率失真理论.密码学.信噪比.数据压缩和相关课题.本文主要罗列一些基于熵的概念及其意 ...
- IQA(图像质量评估)
图像质量评价(Image Quality Assessment,IQA)是图像处理中的基本技术之一,主要通过对图像进行特性分析研究,然后评估出图像优劣(图像失真程度). 主要的目的是使用合适的评价指标 ...
随机推荐
- Easy sssp(spfa判负环与求最短路)
#include<bits/stdc++.h> using namespace std; int n,m,s; struct node{ int to,next,w; }e[]; bool ...
- 团队作业Beta冲刺--第二天
团队作业Beta冲刺 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 你们都是魔鬼吗 作业学习目标 (1)掌握软件黑盒测试技术:(2)学会编制软件 ...
- maven 项目打包配置(build节点)
参考博客:https://www.cnblogs.com/Binhua-Liu/p/5604841.html maven-assembly-plugin的使用 : https://www.cnblog ...
- [React] Write a Custom State Hook in React
Writing your own custom State Hook is not as a daunting as you think. To keep things simple, we'll r ...
- 洛谷 P3375 【模板】KMP字符串匹配 题解
KMP模板,就不解释了 #include<iostream> #include<cstdio> #include<cstring> #include<algo ...
- Linux 服务器用户间ssh免密码登录
1.本脚本为服务器用户间密码互信登录脚本 2.依赖 需要安装expect工具 3.使用 sh CreateUserssh.sh hadoop hadoop /home/hadoop/.ssh 三个带入 ...
- 对数据仓库ODS DW DM的理解
原文链接:https://www.jianshu.com/p/72e395d8cb33 今天看了一些专业的解释,还是对ODS.DW和DM认识不深刻,下班后花时间分别查了查它们的概念. ODS——操作性 ...
- 转载 C# 开源框架(整理)
C# 开源框架(整理)http://www.cnblogs.com/gaoyuchuanIT/articles/5612268.html Json.NET http://json.codeplex.c ...
- VS - Microsoft.Practices.Unity
PM> Install-Package Unity Web.config <configSections> <section name="unity" t ...
- 给各阶段java学习者的建议[转]
第一部分:零基础或基础薄弱的同学这部分主要适用于尚未做过Java工作的同学,包括一些在校生以及刚准备转行Java的同学.一.Java基础首先去找一个Java的基础教程学一下,这里可以推荐达内java课 ...