【视频开发】【CUDA开发】英伟达CUVID硬解,并通过FFmpeg读取文件
虽然FFmpeg本身有cuvid硬解,但是找不到什么好的资料,英伟达的SDK比较容易懂,参考FFmpeg源码,将NVIDIA VIDEO CODEC SDK的数据获取改为FFmpeg获取,弥补原生SDK不能以流作为数据源的不足。所用SDK版本为Video_Codec_SDK_7.1.9,英伟达官网可下载。
1.修改数据源
首先是FFmpeg的一些常规的初始化

bool VideoSource::init(const std::string sFileName, FrameQueue *pFrameQueue)
{
assert(0 != pFrameQueue);
oSourceData_.hVideoParser = 0;
oSourceData_.pFrameQueue = pFrameQueue; int i;
AVCodec *pCodec; av_register_all();
avformat_network_init();
pFormatCtx = avformat_alloc_context(); if (avformat_open_input(&pFormatCtx, sFileName.c_str(), NULL, NULL) != 0){
printf("Couldn't open input stream.\n");
return false;
}
if (avformat_find_stream_info(pFormatCtx, NULL)<0){
printf("Couldn't find stream information.\n");
return false;
}
videoindex = -1;
for (i = 0; i<pFormatCtx->nb_streams; i++)
if (pFormatCtx->streams[i]->codec->codec_type == AVMEDIA_TYPE_VIDEO){
videoindex = i;
break;
} if (videoindex == -1){
printf("Didn't find a video stream.\n");
return false;
} pCodecCtx = pFormatCtx->streams[videoindex]->codec; pCodec = avcodec_find_decoder(pCodecCtx->codec_id);
if (pCodec == NULL){
printf("Codec not found.\n");
return false;
} //Output Info-----------------------------
printf("--------------- File Information ----------------\n");
av_dump_format(pFormatCtx, 0, sFileName.c_str(), 0);
printf("-------------------------------------------------\n"); memset(&g_stFormat, 0, sizeof(CUVIDEOFORMAT)); switch (pCodecCtx->codec_id) {
case AV_CODEC_ID_H263:
g_stFormat.codec = cudaVideoCodec_MPEG4;
break; case AV_CODEC_ID_H264:
g_stFormat.codec = cudaVideoCodec_H264;
break; case AV_CODEC_ID_HEVC:
g_stFormat.codec = cudaVideoCodec_HEVC;
break; case AV_CODEC_ID_MJPEG:
g_stFormat.codec = cudaVideoCodec_JPEG;
break; case AV_CODEC_ID_MPEG1VIDEO:
g_stFormat.codec = cudaVideoCodec_MPEG1;
break; case AV_CODEC_ID_MPEG2VIDEO:
g_stFormat.codec = cudaVideoCodec_MPEG2;
break; case AV_CODEC_ID_MPEG4:
g_stFormat.codec = cudaVideoCodec_MPEG4;
break; case AV_CODEC_ID_VP8:
g_stFormat.codec = cudaVideoCodec_VP8;
break; case AV_CODEC_ID_VP9:
g_stFormat.codec = cudaVideoCodec_VP9;
break; case AV_CODEC_ID_VC1:
g_stFormat.codec = cudaVideoCodec_VC1;
break;
default:
return false;
} //这个地方的FFmoeg与cuvid的对应关系不是很确定,不过用这个参数似乎最靠谱
switch (pCodecCtx->sw_pix_fmt)
{
case AV_PIX_FMT_YUV420P:
g_stFormat.chroma_format = cudaVideoChromaFormat_420;
break;
case AV_PIX_FMT_YUV422P:
g_stFormat.chroma_format = cudaVideoChromaFormat_422;
break;
case AV_PIX_FMT_YUV444P:
g_stFormat.chroma_format = cudaVideoChromaFormat_444;
break;
default:
g_stFormat.chroma_format = cudaVideoChromaFormat_420;
break;
} //找了好久,总算是找到了FFmpeg中标识场格式和帧格式的标识位
//场格式是隔行扫描的,需要做去隔行处理
switch (pCodecCtx->field_order)
{
case AV_FIELD_PROGRESSIVE:
case AV_FIELD_UNKNOWN:
g_stFormat.progressive_sequence = true;
break;
default:
g_stFormat.progressive_sequence = false;
break;
} pCodecCtx->thread_safe_callbacks = 1; g_stFormat.coded_width = pCodecCtx->coded_width;
g_stFormat.coded_height = pCodecCtx->coded_height; g_stFormat.display_area.right = pCodecCtx->width;
g_stFormat.display_area.left = 0;
g_stFormat.display_area.bottom = pCodecCtx->height;
g_stFormat.display_area.top = 0; if (pCodecCtx->codec_id == AV_CODEC_ID_H264 || pCodecCtx->codec_id == AV_CODEC_ID_HEVC) {
if (pCodecCtx->codec_id == AV_CODEC_ID_H264)
h264bsfc = av_bitstream_filter_init("h264_mp4toannexb");
else
h264bsfc = av_bitstream_filter_init("hevc_mp4toannexb");
} return true;
}
这里面非常重要的一段代码是
if (pCodecCtx->codec_id == AV_CODEC_ID_H264 || pCodecCtx->codec_id == AV_CODEC_ID_HEVC) {
if (pCodecCtx->codec_id == AV_CODEC_ID_H264)
h264bsfc = av_bitstream_filter_init("h264_mp4toannexb");
else
h264bsfc = av_bitstream_filter_init("hevc_mp4toannexb");
}
网上有许多代码和伪代码都说实现了把数据源修改为FFmpeg,但我在尝试的时候发现cuvidCreateVideoParser创建的Parser的回调函数都没有调用。经过一番折腾,综合英伟达网站、stackoverflow和FFmpeg源码,才发现对H264数据要做一个处理才能把AVPacket有效的转为CUVIDSOURCEDATAPACKET。其中h264bsfc的定义为AVBitStreamFilterContext* h264bsfc = NULL;
2.AVPacket转CUVIDSOURCEDATAPACKET,并交给cuvidParseVideoData
void VideoSource::play_thread(LPVOID lpParam)
{
AVPacket *avpkt;
avpkt = (AVPacket *)av_malloc(sizeof(AVPacket));
CUVIDSOURCEDATAPACKET cupkt;
int iPkt = 0;
CUresult oResult;
while (av_read_frame(pFormatCtx, avpkt) >= 0){
if (bThreadExit){
break;
}
bStarted = true;
if (avpkt->stream_index == videoindex){ cuCtxPushCurrent(g_oContext); if (avpkt && avpkt->size) {
if (h264bsfc)
{
av_bitstream_filter_filter(h264bsfc, pFormatCtx->streams[videoindex]->codec, NULL, &avpkt->data, &avpkt->size, avpkt->data, avpkt->size, 0);
} cupkt.payload_size = (unsigned long)avpkt->size;
cupkt.payload = (const unsigned char*)avpkt->data; if (avpkt->pts != AV_NOPTS_VALUE) {
cupkt.flags = CUVID_PKT_TIMESTAMP;
if (pCodecCtx->pkt_timebase.num && pCodecCtx->pkt_timebase.den){
AVRational tb;
tb.num = 1;
tb.den = AV_TIME_BASE;
cupkt.timestamp = av_rescale_q(avpkt->pts, pCodecCtx->pkt_timebase, tb);
}
else
cupkt.timestamp = avpkt->pts;
}
}
else {
cupkt.flags = CUVID_PKT_ENDOFSTREAM;
} oResult = cuvidParseVideoData(oSourceData_.hVideoParser, &cupkt);
if ((cupkt.flags & CUVID_PKT_ENDOFSTREAM) || (oResult != CUDA_SUCCESS)){
break;
}
iPkt++;
//printf("Succeed to read avpkt %d !\n", iPkt);
checkCudaErrors(cuCtxPopCurrent(NULL));
}
av_free_packet(avpkt);
} oSourceData_.pFrameQueue->endDecode();
bStarted = false;
}
这里FFmpeg读取数据包后,对H264和HEVC格式,有一个重要的处理,就是前面提到的,
if (h264bsfc)
{
av_bitstream_filter_filter(h264bsfc, pFormatCtx->streams[videoindex]->codec, NULL, &avpkt->data, &avpkt->size, avpkt->data, avpkt->size, 0);
}
这个处理的含义见雷霄华的博客http://blog.csdn.net/leixiaohua1020/article/details/39767055。
这样,通过FFmpeg,CUVID就可以对流进行处理了。个人尝试过读取本地文件和rtsp流。FFmpeg读取rtsp流的方式竟然只需要把文件改为rtsp流的地址就可以,以前没做过流式的,我还以为会很复杂的。
3.一点数据
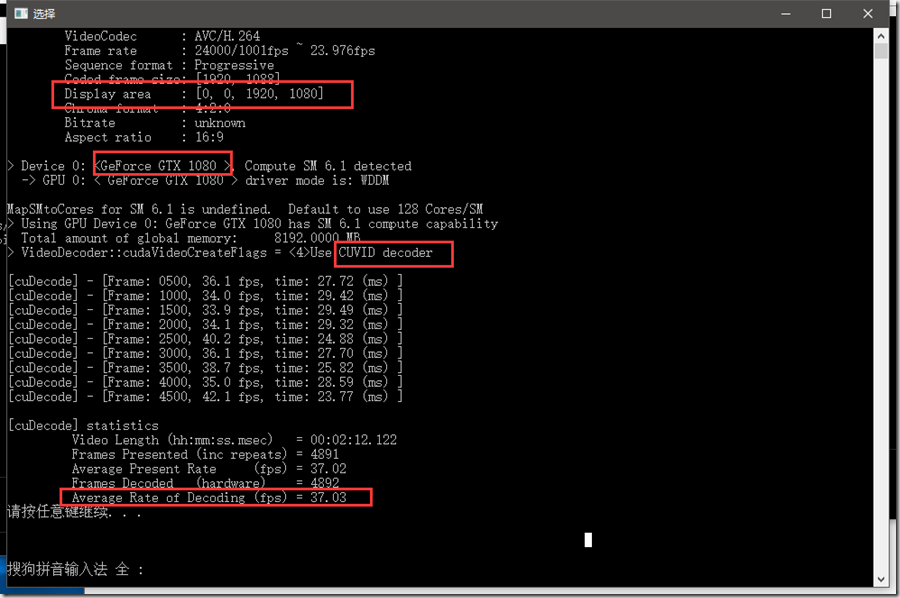
这是在GTX 1080上把解码进程(没做显示)开了20路解码得到的数据。20路1920X1080解码还能到平局37fps,这显卡也是6得不行。
【视频开发】【CUDA开发】英伟达CUVID硬解,并通过FFmpeg读取文件的更多相关文章
- 英伟达CUVID硬解,并通过FFmpeg读取文件
虽然FFmpeg本身有cuvid硬解,但是找不到什么好的资料,英伟达的SDK比较容易懂,参考FFmpeg源码,将NVIDIA VIDEO CODEC SDK的数据获取改为FFmpeg获取,弥补原生SD ...
- CUDA学习笔记4:CUDA(英伟达显卡统一计算架构)代码运行时间测试
CUDA内核运行时间的测量函数 cudaEvent_t start1; cudaEventCreate(&start1); cudaEvent_t stop1; cudaEventCreate ...
- CUDA学习笔记2:CUDA(英伟达显卡统一计算架构)与已有的VS项目结合
一.步骤 1.先新建一个简单的控制台应用程序,项目名称为Mytest,如下图所示: 2.在项目中添加一个名为Test.cu文件,如下图所示: 3.在解决方案资源管理器中选择该项目并点击右键,在弹出的菜 ...
- 【并行计算与CUDA开发】英伟达硬件加速编解码
硬件加速 并行计算 OpenCL OpenCL API VS SDK 英伟达硬件编解码方案 基于 OpenCL 的 API 自己写一个编解码器 使用 SDK 中的编解码接口 使用编码器对于 OpenC ...
- 【并行计算-CUDA开发】英伟达硬件解码器分析
这篇文章主要分析 NVCUVID 提供的解码器,里面提到的所有的源文件都可以在英伟达的 nvenc_sdk 中找到. 解码器的代码分析 SDK 中的 sample 文件夹下的 NvTranscoder ...
- 【并行计算-CUDA开发】从熟悉到精通 英伟达显卡选购指南
举报 说到显卡,就不免令人想到英伟达和AMD两家面向个人消费级和企业级最大的显示芯片生产企业,英伟达和AMD,今天小编为大家简单的介绍一下英伟达的显卡选购方面的攻略,为一些想要购买显卡的用户提供一些参 ...
- 英伟达GPU 嵌入式开发平台
英伟达GPU 嵌入式开发平台 1. JETSON TX1 开发者组件 JETSON TX1 开发者组件是视觉计算的全功能 开发平台,旨在让您能够快速地安装和运行. 该组件带有 Lin ...
- 第一篇:CUDA 6.0 安装及配置( WIN7 64位 / 英伟达G卡 / VS2010 )
前言 本文讲解如何在VS 2010开发平台中搭建CUDA开发环境. 当前配置: 系统:WIN7 64位 开发平台:VS 2010 显卡:英伟达G卡 CUDA版本:6.0 若配置不同,请谨慎参考本文. ...
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
随机推荐
- java处理异常的机制关键字为throw和throws
在异常处理的过程中,throws和throw的区别是? throws:是在方法上对一个方法进行声明,而不进行处理,而是向上传,谁调用谁处理. throw:是在具体的抛出一个异常类型. throws的栗 ...
- Docker 基本操作(附 redis、nginx部署)
下载安装 Docker 也有一个月了.中间看过几次也没有深入的了解研究.就只是拉取了两个镜像简单的看了看. 昨天因一个项目中需要用到 Redis ,因为是 Windows 系统,看了下安装包比较老了有 ...
- Python应用之-修改通讯录
#-*- coding:utf-8 -*- import sqlite3 #打开本地数据库用于存储用户信息 conn = sqlite3.connect('mysql_person.db') #在该数 ...
- RDD&Dataset&DataFrame
Dataset创建 object DatasetCreation { def main(args: Array[String]): Unit = { val spark = SparkSession ...
- Otsu 类间方差法
又称最大类间方差法.是由日本学者大津(Nobuyuki Otsu)于1979年提出的[1],是一种自适合于双峰情况的自动求取阈值的方法.又叫大津法,简称Otsu. 算法提出初衷是是按图像的灰度特性 ...
- WinDbg常用命令系列---清屏
.cls (Clear Screen) .cls命令清除调试器命令窗口显示. .cls 环境: 模式 用户模式下,内核模式 目标 实时. 崩溃转储 平台 全部 清屏前 清屏后
- Nodejs中的路径问题
一.path核心模块 ①path.basename(path[,ext])获取一个路径中的文件名 var path=require('path'); console.log(path.basename ...
- A simple dispiction of dijkstra
前言 \(SPFA\)算法由于它上限 \(O(NM) = O(VE)\)的时间复杂度,被卡掉的几率很大.在算法竞赛中,我们需要一个更稳定的算法:\(dijkstra\). 什么是\(dijkstra\ ...
- (LIS)最长上升序列(DP+二分优化)
求一个数列的最长上升序列 动态规划法:O(n^2) //DP int LIS(int a[], int n) { int DP[n]; int Cnt=-1; memset(DP, 0, sizeof ...
- GoCN每日新闻(2019-09-30)
GoCN每日新闻(2019-09-30) 1. 使用Sqlmock测试数据库 https://medium.com/ralali-engineering/testing-database-using- ...