深度学习面试题17:VGGNet(1000类图像分类)
目录
VGGNet网络结构
论文中还讨论了其他结构
参考资料
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
VGGNet可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
|
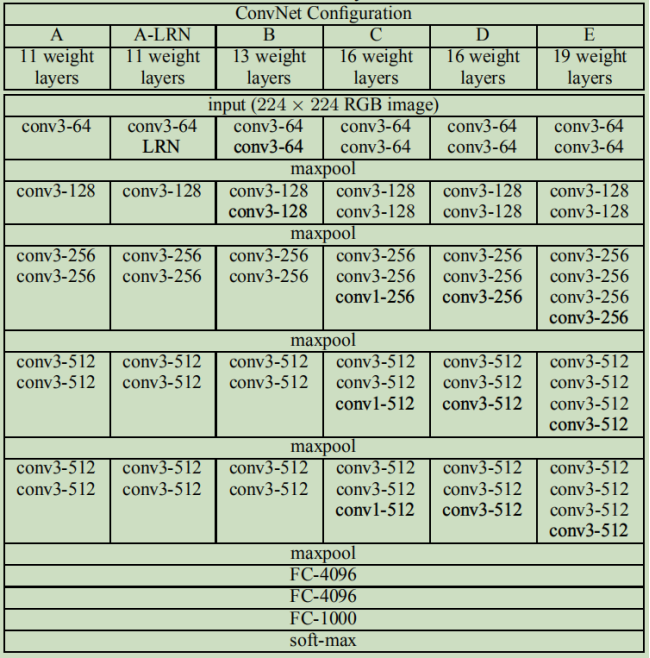
VGGNet网络结构 |
VGGNet比AlexNet的网络层数多,不再使用尺寸较大的卷积核,如11*11、7*7、5*5,而是只采用了尺寸为3*3的卷积核,VGG-16的卷积神经网络结构如下:

对应代码为:
import tensorflow as tf
import numpy as np # 输入
x = tf.placeholder(tf.float32, [None, 224, 224, 3])
# 第1层:与64个3*3*3的核,步长=1,SAME卷积
w1 = tf.Variable(tf.random_normal([3, 3, 3, 64]), dtype=tf.float32, name='w1')
conv1 = tf.nn.relu(tf.nn.conv2d(x, w1, [1, 1, 1, 1], 'SAME'))
# 结果为224*224*64 # 第2层:与64个3*3*64的核,步长=1,SAME卷积
w2 = tf.Variable(tf.random_normal([3, 3, 64, 64]), dtype=tf.float32, name='w2')
conv2 = tf.nn.relu(tf.nn.conv2d(conv1, w2, [1, 1, 1, 1], 'SAME'))
# 结果为224*224*64 # 池化1
pool1 = tf.nn.max_pool(conv2, [1, 2, 2, 1], [1, 2, 2, 1], 'VALID')
# 结果为112*112*64 # 第3层:与128个3*3*64的核,步长=1,SAME卷积
w3 = tf.Variable(tf.random_normal([3, 3, 64, 128]), dtype=tf.float32, name='w3')
conv3 = tf.nn.relu(tf.nn.conv2d(pool1, w3, [1, 1, 1, 1], 'SAME'))
# 结果为112*112*128 # 第4层:与128个3*3*128的核,步长=1,SAME卷积
w4 = tf.Variable(tf.random_normal([3, 3, 128, 128]), dtype=tf.float32, name='w4')
conv4 = tf.nn.relu(tf.nn.conv2d(conv3, w4, [1, 1, 1, 1], 'SAME'))
# 结果为112*112*128 # 池化2
pool2 = tf.nn.max_pool(conv4, [1, 2, 2, 1], [1, 2, 2, 1], 'VALID')
# 结果为56*56*128 # 第5层:与256个3*3*128的核,步长=1,SAME卷积
w5 = tf.Variable(tf.random_normal([3, 3, 128, 256]), dtype=tf.float32, name='w5')
conv5 = tf.nn.relu(tf.nn.conv2d(pool2, w5, [1, 1, 1, 1], 'SAME'))
# 结果为56*56*256 # 第6层:与256个3*3*256的核,步长=1,SAME卷积
w6 = tf.Variable(tf.random_normal([3, 3, 256, 256]), dtype=tf.float32, name='w6')
conv6 = tf.nn.relu(tf.nn.conv2d(conv5, w6, [1, 1, 1, 1], 'SAME'))
# 结果为56*56*256 # 第7层:与256个3*3*256的核,步长=1,SAME卷积
w7 = tf.Variable(tf.random_normal([3, 3, 256, 256]), dtype=tf.float32, name='w7')
conv7 = tf.nn.relu(tf.nn.conv2d(conv6, w7, [1, 1, 1, 1], 'SAME'))
# 结果为56*56*256 # 池化3
pool3 = tf.nn.max_pool(conv7, [1, 2, 2, 1], [1, 2, 2, 1], 'VALID')
# 结果为28*28*256 # 第8层:与512个3*3*256的核,步长=1,SAME卷积
w8 = tf.Variable(tf.random_normal([3, 3, 256, 512]), dtype=tf.float32, name='w8')
conv8 = tf.nn.relu(tf.nn.conv2d(pool3, w8, [1, 1, 1, 1], 'SAME'))
# 结果为28*28*512 # 第9层:与512个3*3*512的核,步长=1,SAME卷积
w9 = tf.Variable(tf.random_normal([3, 3, 512, 512]), dtype=tf.float32, name='w9')
conv9 = tf.nn.relu(tf.nn.conv2d(conv8, w9, [1, 1, 1, 1], 'SAME'))
# 结果为28*28*512 # 第10层:与512个3*3*512的核,步长=1,SAME卷积
w10 = tf.Variable(tf.random_normal([3, 3, 512, 512]), dtype=tf.float32, name='w10')
conv10 = tf.nn.relu(tf.nn.conv2d(conv9, w10, [1, 1, 1, 1], 'SAME'))
# 结果为28*28*512 # 池化4
pool4 = tf.nn.max_pool(conv10, [1, 2, 2, 1], [1, 2, 2, 1], 'VALID')
# 结果为14*14*512 # 第11层:与512个3*3*256的核,步长=1,SAME卷积
w11 = tf.Variable(tf.random_normal([3, 3, 512, 512]), dtype=tf.float32, name='w11')
conv11 = tf.nn.relu(tf.nn.conv2d(pool4, w11, [1, 1, 1, 1], 'SAME'))
# 结果为14*14*512 # 第12层:与512个3*3*512的核,步长=1,SAME卷积
w12 = tf.Variable(tf.random_normal([3, 3, 512, 512]), dtype=tf.float32, name='w12')
conv12 = tf.nn.relu(tf.nn.conv2d(conv11, w12, [1, 1, 1, 1], 'SAME'))
# 结果为14*14*512 # 第13层:与512个3*3*512的核,步长=1,SAME卷积
w13 = tf.Variable(tf.random_normal([3, 3, 512, 512]), dtype=tf.float32, name='w13')
conv13 = tf.nn.relu(tf.nn.conv2d(conv12, w13, [1, 1, 1, 1], 'SAME'))
# 结果为14*14*512 # 池化5
pool5 = tf.nn.max_pool(conv13, [1, 2, 2, 1], [1, 2, 2, 1], 'VALID')
# 结果为7*7*512 # 拉伸为25088
pool_l5_shape = pool5.get_shape()
num = pool_l5_shape[1].value * pool_l5_shape[2].value * pool_l5_shape[3].value
flatten = tf.reshape(pool5, [-1, num])
# 结果为25088*1 # 第14层:与4096个神经元全连接
fcW1 = tf.Variable(tf.random_normal([num, 4096]), dtype=tf.float32, name='fcW1')
fc1 = tf.nn.relu(tf.matmul(flatten, fcW1)) # 第15层:与4096个神经元全连接
fcW2 = tf.Variable(tf.random_normal([4096, 4096]), dtype=tf.float32, name='fcW2')
fc2 = tf.nn.relu(tf.matmul(fc1, fcW2)) # 第16层:与1000个神经元全连接+softmax输出
fcW3 = tf.Variable(tf.random_normal([4096, 1000]), dtype=tf.float32, name='fcW3')
out = tf.matmul(fc2, fcW3)
out=tf.nn.softmax(out) session = tf.Session()
session.run(tf.global_variables_initializer())
result = session.run(out, feed_dict={x: np.ones([1, 224, 224, 3], np.float32)})
# "打印最后的输出尺寸"
print(np.shape(result))
|
论文中还讨论了其他结构 |
|
参考资料 |
吴恩达深度学习
VGGNet-Very Deep Convolutional Networks for Large-Scale Image Recognition
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
《深-度-学-习-核-心-技-术-与-实-践》
大话CNN经典模型:VGGNet
深度学习面试题17:VGGNet(1000类图像分类)的更多相关文章
- 深度学习面试题13:AlexNet(1000类图像分类)
目录 网络结构 两大创新点 参考资料 第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,Alex Krizhevsky其实是Hinton的学生,这个团队领导者是 ...
- 深度学习Keras框架笔记之AutoEncoder类
深度学习Keras框架笔记之AutoEncoder类使用笔记 keras.layers.core.AutoEncoder(encoder, decoder,output_reconstruction= ...
- 深度学习Keras框架笔记之TimeDistributedDense类
深度学习Keras框架笔记之TimeDistributedDense类使用方法笔记 例: keras.layers.core.TimeDistributedDense(output_dim,init= ...
- 深度学习Keras框架笔记之Dense类(标准的一维全连接层)
深度学习Keras框架笔记之Dense类(标准的一维全连接层) 例: keras.layers.core.Dense(output_dim,init='glorot_uniform', activat ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- 深度学习面试题27:非对称卷积(Asymmetric Convolutions)
目录 产生背景 举例 参考资料 产生背景 之前在深度学习面试题16:小卷积核级联卷积VS大卷积核卷积中介绍过小卷积核的三个优势: ①整合了三个非线性激活层,代替单一非线性激活层,增加了判别能力. ②减 ...
- 深度学习面试题20:GoogLeNet(Inception V1)
目录 简介 网络结构 对应代码 网络说明 参考资料 简介 2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名.VGG获得了第二 ...
- 深度学习面试题12:LeNet(手写数字识别)
目录 神经网络的卷积.池化.拉伸 LeNet网络结构 LeNet在MNIST数据集上应用 参考资料 LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务.自那时起 ...
- 深度学习面试题26:GoogLeNet(Inception V2)
目录 第一层卷积换为分离卷积 一些层的卷积核的个数发生了变化 多个小卷积核代替大卷积核 一些最大值池化换为了平均值池化 完整代码 参考资料 第一层卷积换为分离卷积 net = slim.separab ...
随机推荐
- Anaconda-Jupyter notebook 如何安装 nbextensions
系统环境:windows 安装过程中,再次遇到了一地鸡毛,经过不断查询方法,发现前辈大牛们好棒棒! Step1:确定是已经安装好anaconda Step2:要在anaconda prompt模式下运 ...
- 【English】 Re-pick up English for learning big data (not updated regularly)
2019.10.6 parse:解析mean:平均数stddev:标准偏差 2019.10.7 bigdata platform:大数据平台 2019.10.14 allocate resource ...
- 多选文件批量上传前端(ajax*formdata)+后台(Request.Files[i])---input+ajax原生上传
1.配置Web.config;设定上传文件大小 <system.web> <!--上传1000M限制(https://www.cnblogs.com/Joans/p/4315411. ...
- TableCache设置过小造成MyISAM频繁损坏 与 把table_cache适当调小mysql能更快地工作
来源: 前些天说了一下如何修复损坏的MyISAM表,可惜只会修复并不能脱离被动的境地,只有查明了故障原因才会一劳永逸. 如果数据库服务非正常关闭(比如说进程被杀,服务器断电等等),并且此时恰好正在更新 ...
- c# 常见文件夹操作
- MySQL的My.cnf模板(转)
[client] default-character-set = utf8mb4 port = PORT socket = /srv/myPORT/run/mysql.sock [mysqld] us ...
- 个性化排序算法实践(五)——DCN算法
wide&deep在个性化排序算法中是影响力比较大的工作了.wide部分是手动特征交叉(负责memorization),deep部分利用mlp来实现高阶特征交叉(负责generalizatio ...
- spark context stop use with as
调用方法: with session.SparkStreamingSession('CC_Traffic_Realtime', ssc_time_windown) as ss_session: kaf ...
- 让 Python 代码更易维护的七种武器——代码风格(pylint、Flake8、Isort、Autopep8、Yapf、Black)测试覆盖率(Coverage)CI(JK)
让 Python 代码更易维护的七种武器 2018/09/29 · 基础知识 · 武器 原文出处: Jeff Triplett 译文出处:linux中国-Hank Chow 检查你的代码的质 ...
- python算法与数据结构-冒泡排序算法(32)
一.冒泡排序介绍 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要 ...