深入源码理解Spark RDD的数据分区原理
通过内存创建RDD的分区设置
1、示例代码
在创建RDD的时候,我们可以从内存中进行创建;输出保存为文件。为了演示效果,我们的示例代码如下:
import org.apache.spark.{SparkConf, SparkContext}
object Spark02RddParallelizeSet {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "C:\\Hadoop\\")
val spark = new SparkConf().setMaster("local[*]").setAppName("RddParallelizeSet")
val context = new SparkContext(spark)
val list = List(1, 2, 3, 4)
// TODO: 从内存创建RDD,并且设置并行执行的任务数量
// numSlices: Int = defaultParallelism
val memoryRDD = context.makeRDD(list, 1)
memoryRDD.saveAsTextFile("output")
val memoryRDD1 = context.makeRDD(list, 2)
memoryRDD1.saveAsTextFile("output1")
val memoryRDD2 = context.makeRDD(list, 3)
memoryRDD2.saveAsTextFile("output2")
val memoryRDD3 = context.makeRDD(list, 4)
memoryRDD3.saveAsTextFile("output3")
val memoryRDD4 = context.makeRDD(list, 5)
memoryRDD4.saveAsTextFile("output4")
// TODO: 结束
context.stop()
}
}
上面的代码里,我们从内存中创建了5个RDD,每个RDD设置了不同的分区数。
2、执行结果
(1)1个分区的RDD,效果如下图所示:
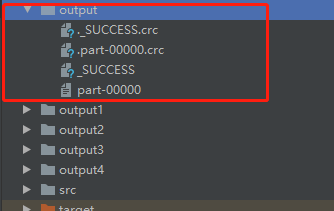
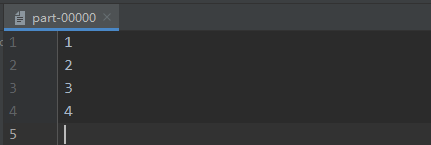
在output文件夹中,只包含了一个分区文件 part-00000 ,其文件内容如下图所示:
(2)2个分区的RDD,效果如下图所示:
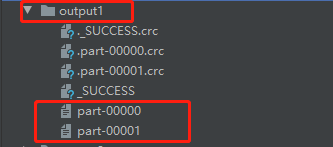
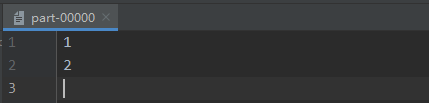
在output1文件夹中,包含了两个分区文件 part-00000 以及 part-00001,二者文件内容如下图所示:

(3)3个分区的RDD,效果如下图所示:
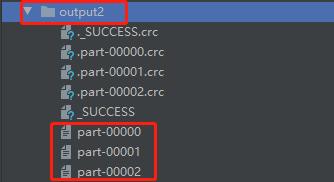
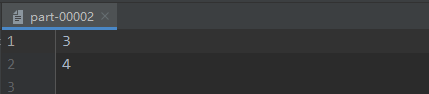
在output2文件夹中,包含了三个分区文件 part-00000 、part-00001、part-00002,三者文件内容如下图所示:


(4)4个分区的RDD,效果如下图所示:
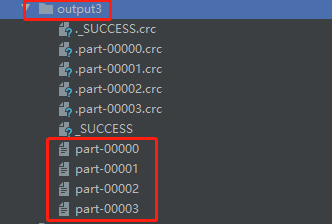
在output3文件夹中,包含了四个分区文件 part-00000、part-00001、part-00002、part-00003,四者文件内容如下图所示:




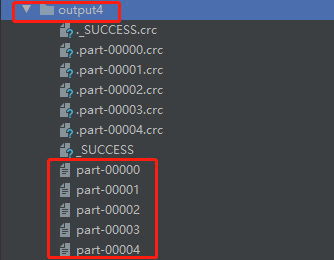
在output4文件夹中,包含了五个分区文件 part-00000、part-00001、part-00002、part-00003、part-00004,五者文件内容如下图所示:





3、分析结果
仔细看看上面图片中的结果,不难发现其中肯定深藏猫腻。不同分区数的设置,都存在不同的输出效果。要想深究其中缘由,有必要去了解Spark的在这一块的源码实现。进入到 makeRDD( ) 这个方法中,可以看到如下源码:
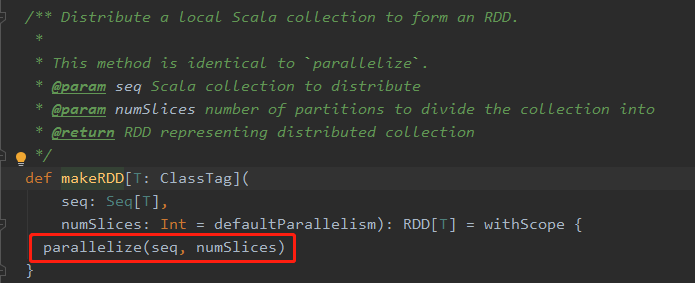
在图片中用红色方框框起来的部分,是一个方法,其中传入了两个参数,第一个 seq 就是在我们自己写的代码中,自己定义的那个 List;第二个 numSlices 就是我们自己写的代码中的那个分区数。
再点进 parallelize( seq, numSlices) 这个方法中去,可以看到如下源码:
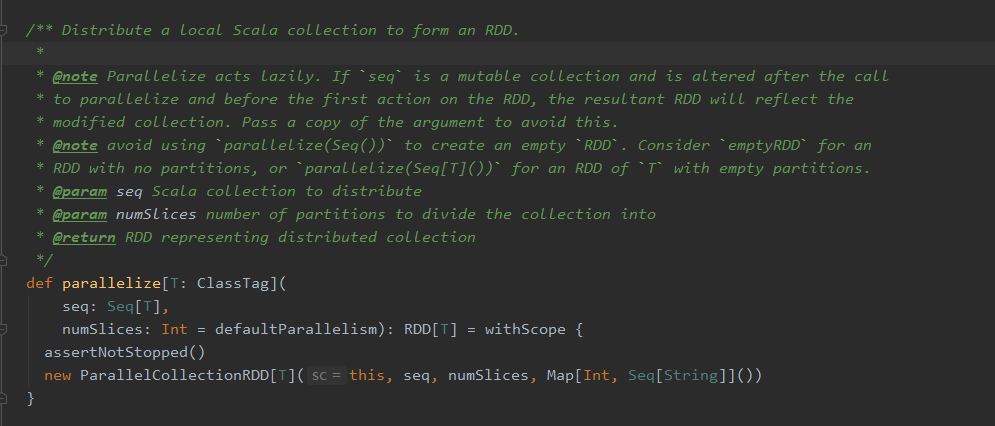
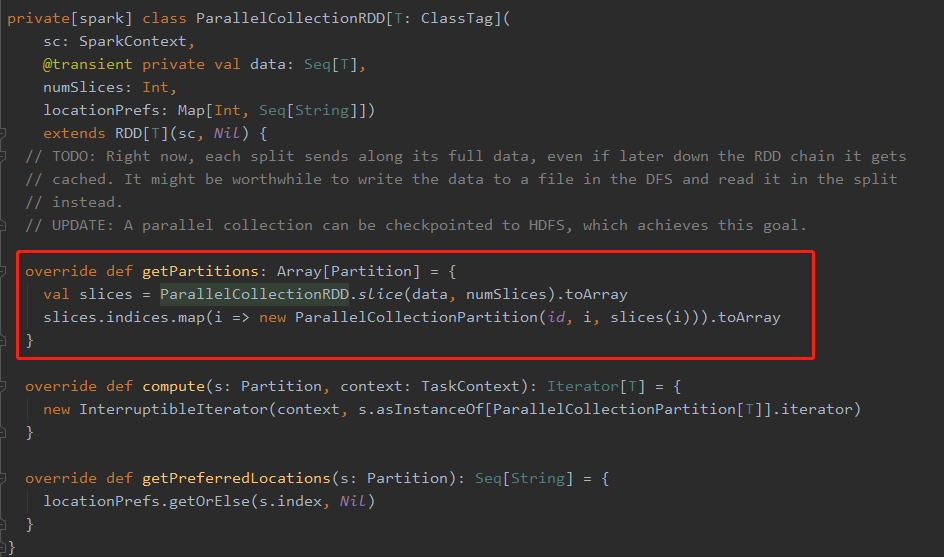
红色线框框出的这个名为 getPartitions 的方法,返回的是一个分区的数组,ParallelCollectionRDD.slice( ) 调用的是 ParallelCollectionRDD 伴生对象里面的一个方法,看样子应该是这个方法里的代码规定了怎么进行分区的划分了,于是,进到这个方法里面,果不其然,可以看到如下代码块:

在 slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] 这个方法中,我们可以看到一个关于 seq 这个传入的参数的模式匹配:
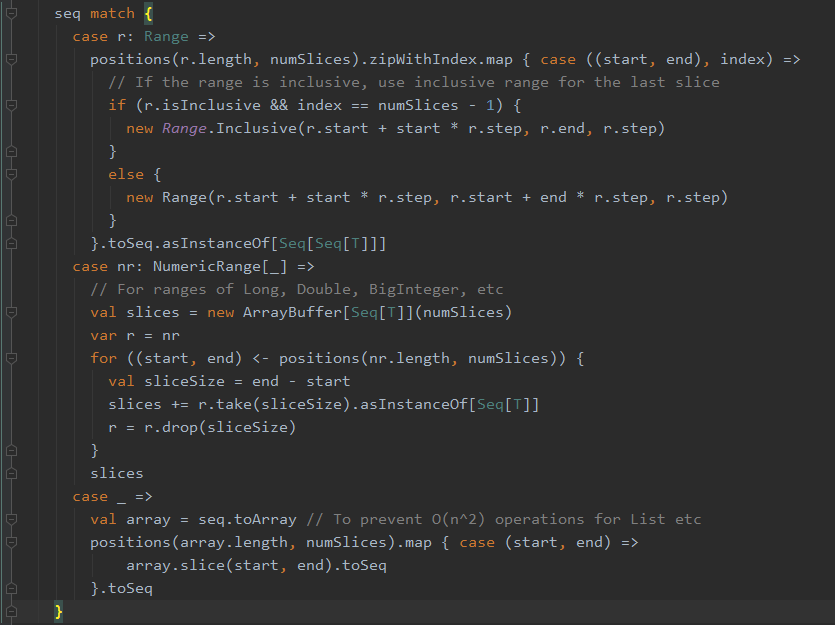
在上图的这一段代码中,模式匹配第一个匹配的是 Range 类型,很明显与我们传入的 List 类型不一致,因此 case r: Range 这一块的匹配代码可以跳过。第二个匹配的也是Range,相比于第一个匹配的Range 整形类型 而言,第二个则可以匹配更多种类型的 Range。当然第二个case也不是我们要看的。那么就剩下第三个 "case _" 这种情况了。
在第三个情况中,首先将 我们传入的 List 转换为了一个 array,为什么要有这一步,源码中也给出了注释:To prevent O(n ^ 2) operations for List etc。之后调用了positions( ) 方法,将转换后的数组的长度以及分区数量传入,该方法源码如下:
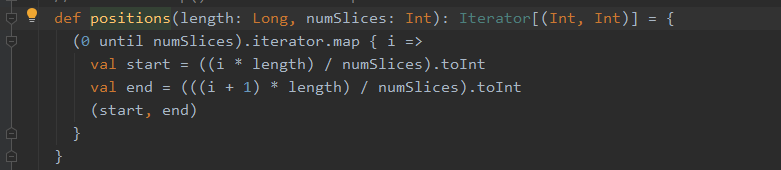
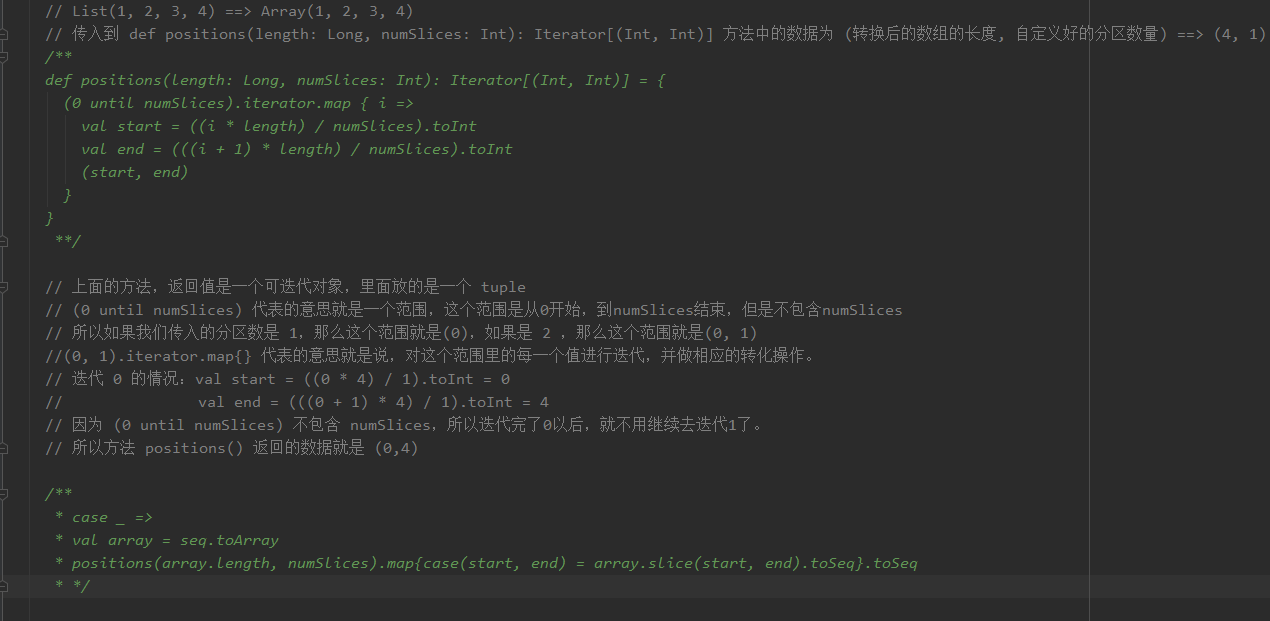
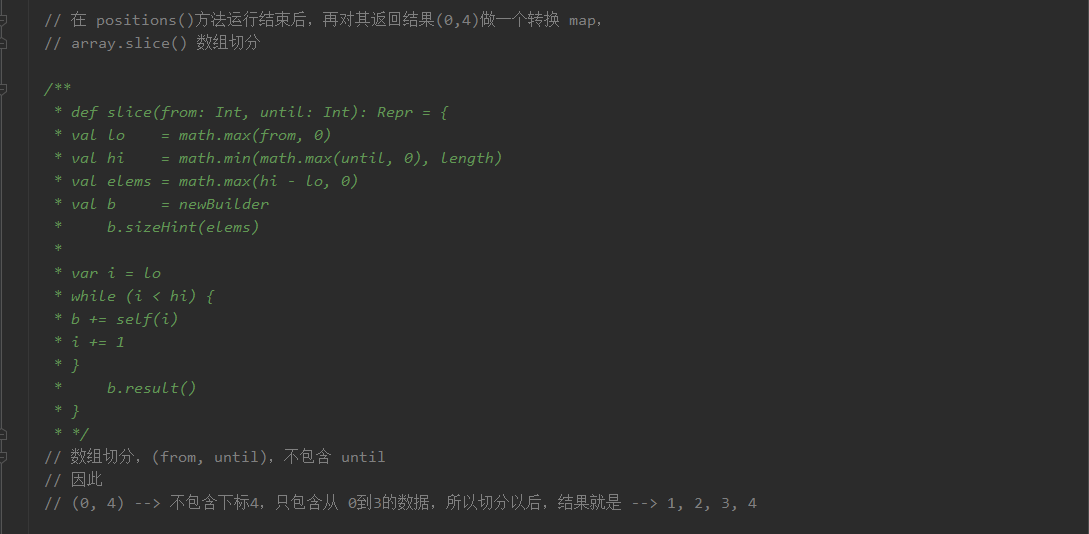
我的分析过程如下,数据是(1,2,3,4),分区数量是1的情况:
4、小结
深入源码理解Spark RDD的数据分区原理的更多相关文章
- Caffe源码理解2:SyncedMemory CPU和GPU间的数据同步
目录 写在前面 成员变量的含义及作用 构造与析构 内存同步管理 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 在Caffe源码理解1中介绍了Blob类,其中的数据成 ...
- 基于SpringBoot的Environment源码理解实现分散配置
前提 org.springframework.core.env.Environment是当前应用运行环境的公开接口,主要包括应用程序运行环境的两个关键方面:配置文件(profiles)和属性.Envi ...
- Pytorch学习之源码理解:pytorch/examples/mnists
Pytorch学习之源码理解:pytorch/examples/mnists from __future__ import print_function import argparse import ...
- [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler
[源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler 目录 [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampl ...
- [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader
[源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 目录 [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 0x00 摘要 0x01 ...
- HashMap源码理解一下?
HashMap 是一个散列桶(本质是数组+链表),散列桶就是数据结构里面的散列表,每个数组元素是一个Node节点,该节点又链接着多个节点形成一个链表,故一个数组元素 = 一个链表,利用了数组线性查找和 ...
- Fresco源码解析 - DataSource怎样存储数据
Fresco源码解析 - DataSource怎样存储数据 datasource是一个独立的 package,与FB导入的guava包都在同一个工程内 - fbcore. datasource的类关系 ...
- jedis的源码理解-基础篇
[jedis的源码理解-基础篇][http://my.oschina.net/u/944165/blog/127998] (关注实现关键功能的类) 基于jedis 2.2.0-SNAPSHOT ...
- HDFS源码分析心跳汇报之数据块汇报
在<HDFS源码分析心跳汇报之数据块增量汇报>一文中,我们详细介绍了数据块增量汇报的内容,了解到它是时间间隔更长的正常数据块汇报周期内一个smaller的数据块汇报,它负责将DataNod ...
随机推荐
- 水题-------判断Digit Generator
题目链接:https://vjudge.net/problem/UVA-1583 题意:给出一个数N,判断最小的数x使x+(x各位数字的和)=N 题解:这是一个暴力求解题,不过有技巧,x各位数字的和最 ...
- Js数组对象的属性值升序排序,并指定数组中的某个对象移动到数组的最前面
需求整理: 本篇文章主要实现的是将一个数组的中对象的属性值通过升序的方式排序,然后能够让程序可以指定对应的数组对象移动到程序的最前面. 数组如下所示: var arrayData= [{name: & ...
- Android 文件存储浅析
最近做的一个需求和文件存储有关系.由于之前没有系统梳理过,对文件存储方面的知识一直很懵懂.趁着周末有时间,赶紧梳理一波. 这首从网上找到的一张图,很好的概括了外部存储和内部存储. 下面我们再来具体介绍 ...
- pdfmake.js使用及其源码分析
公司项目在需要将页面的文本导出成DPF,和支持打印时,一直没有做过这样的功能,花了一点时间将其做了出来,并且本着开源的思想和技术分享的目的,将自己的编码经验分享给大家,希望对大家有用. 现在是有一个文 ...
- mysql字符集 utf8 和utf8mb4 的区别
一.导读我们新建mysql数据库的时候,需要指定数据库的字符集,一般我们都是选择utf8这个字符集,但是还会又一个utf8mb4这个字符集,好像和utf8有联系,今天就来解析一下这两者的区别. 二.起 ...
- IO—》递归
递归的概述 递归,指在当前方法内调用自己的这种现象 public void method(){ System.out.println(“递归的演示”); //在当前方法内调用自己 method(); ...
- Python字符串内建函数_上
Python字符串内建函数: 注:汉字属于字符(既是大写又是小写).数字可以是: Unicode 数字,全角数字(双字节),罗马数字,汉字数字. 1.capitalize( ): 将字符串第一个字母大 ...
- Vue无限滚动加载数据
Web项目经常会用到下拉滚动加载数据的功能,今天就来种草Vue-infinite-loading 这个插件,讲解一下使用方法! 第一步:安装 npm install vue-infinite-load ...
- Skill 中的通用输出格式规范
https://www.cnblogs.com/yeungchie/ Skill中的通用输出格式规范 Common Output Format Specifications Format Specif ...
- 6.6 省选模拟赛 线段 二维数点问题 树套树 CDQ分治
LINK:线段 还是太菜了 没看出这道题真正的模型 我真是一个典型的没脑子选手. 考虑如何查询答案. 每次在一个线段x的状态被更改后 可以发现有影响的是 和x相连那段极长连续1子段. 设这个子段左端点 ...