你知道MySQL的LRU链表吗?
相信大家对LRU链表是不陌生的,算是一种基础的数据结构!
LRU:Least Recently Used
一、简述传统的LRU链表
LRU:Least Recently Used
相信大家对LRU链表是不陌生的,它算是一种基础的数据结构吧,而且想必面试时也被问到过什么是LRU链表,甚至是让你手写一个LRU链表。
如果你读了上一篇:你有没有搞混查询缓存和BufferPool?谈谈看!
想必你已经知道了MySQL的Buffer Pool机制以及MySQL组织数据的最小单位是数据页。并且你也知道了 数据页在Buffer Pool中是以LRU链表的数据结构组织在一起的。
其实所谓的LRU链表本质上就是一个双向循环链表,如下图:

下面我们结合LRU链表和数据页机制描述一下MySQL加载数据的机制:
我们将从磁盘中读取的数据页称为young page,young page会被直接放在链表的头部。已经存在于LRU链表中数据页如果被使用到了,那么该数据页也被认为是young page而被移动到链表头部。这样链表尾部的数据就是最近最少使用的数据了,当Buffer Pool容量不足,或者后台线程主动刷新数据页时,就会优先刷新链表尾部的数据页。
二、传统LRU链表的不足
相信你之前肯定听说过操作系统级别的空间局部性原理:
spatial locality(空间局部性):也就是说读取一个数据,在它周围内存地址存储的数据也很有可能被读取到,于是操作系统会帮你预读一部分数据。
MySQL也是存在存在预读机制的!
- 当Buffer Pool中存储着一个区中13个连续的数据页时,你再去这个区里面读取,MySQL就会将这个区里面所有的数据页都加载进Buffer Pool中的LRU链表中。(然后可能你根本不会使用这些被预读的数据页)
- 当你顺序的访问了一个区中大于
innndb_read_ahead_threshold=56个数据页时,MySQL会自动帮你将下一个相邻区中的数据页读入LRU链表中。(这个机制默认是被关闭的) - 当你执行
select * from xxx;时,如果表中的数据页非常多,那这些数据页就会一一将Buffer Pool中的经常使用的缓存页挤下去,可能留在LRU链表中的全部是你不经常使用的数据。
综上你可以看到,所谓的预读机制的优势,实际上违背了LRU去实现将最近最少使用的数据页刷入磁盘的设计初衷。
三、MySQL的LRU链表
接下来我们看下MySQL的Buffer Pool是如何定制LRU链表的,已经LRU帮InnoDB解决了什么问题。
当业务进行大量的CRUD时,需要不断的将数据页读取到buffer pool中的LRU链表中。
MySQL的LRU链表长下面这样。
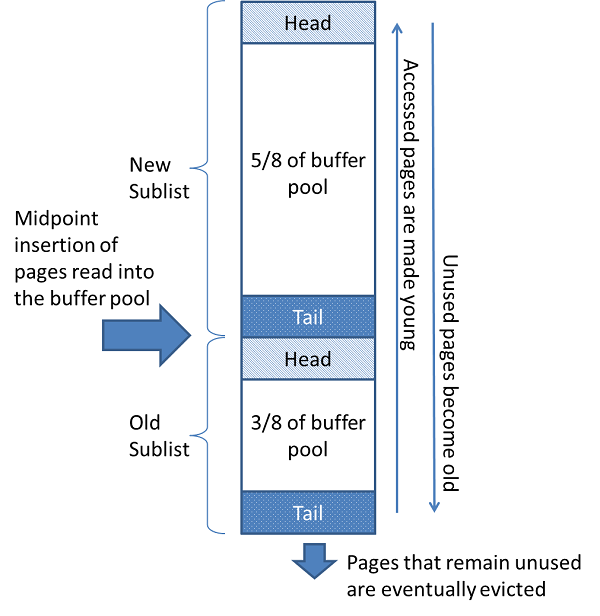
LRU链表被MidPoint分成了New Sublist和Old Sublist两部分。
其中New Sublist大概占比5/8,Old Sublist占比3/8。
New Sublist存储着young page,而Old Sublist存储着Old Page。
我们可以通过如下的方式查看MidPoint的默认值。

用户可以根据自己的业务动态的调整这个参数!
这其实是一种冷热数据分离设计思想。他相对于传统的LRU链表有很大的优势
四、MySQL定制LRU链表的优势
而对于MySQLLRU链表来说,通过MidPoint将链表分成两部分。
从磁盘中新读出的数据会放在Old Sublist的头部。这样即使你真的使用select * from t;也不会导致New Sublist中的经常被访问的数据页被刷入磁盘中。
正常情况下,访问Old Sublist中的缓存页,那么该缓存页会被提升到New Sublist中成为热数据。
但是当你通过 select * from t 将一大批数据加载到Old Sublist时,然后在不到1s内你又访问了它,那在这段时间内被访问的缓存页并不会被提升为热数据。 这个1s由参数innodb_old_blocks_time控制。
另外:New SubList也是经过优化的,如果你访问的是New SubList的前1/4的数据,他是不会被移动到LRU链表头部去的。
当然你可能对什么是数据区并不了解,别急。白日梦将在第13篇文章中同你分享什么是数据区
五、推荐阅读
4、能谈谈year、date、datetime、time、timestamp的区别吗?
参考:
https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-performance-midpoint_insertion.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-performance-read_ahead.html
关注送书!《Netty实战》


文章公号号首发!连载中!关注微信公号回复:“抽奖” 可参加抽活动
你知道MySQL的LRU链表吗?的更多相关文章
- linux内存源码分析 - 内存回收(lru链表)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 对于整个内存回收来说,lru链表是关键中的关键,实际上整个内存回收,做的事情就是处理lru链表的收缩,所以 ...
- (转)linux内存源码分析 - 内存回收(lru链表)
原文:http://www.cnblogs.com/tolimit/p/5447448.html 概述 对于整个内存回收来说,lru链表是关键中的关键,实际上整个内存回收,做的事情就是处理lru链表的 ...
- mysql 原理 ~ LRU 算法与buffer_pool
一 简介:针对查询和事务的页在内存中的处理,是如何进行的 二 LRU算法 普通 : 实现的是末尾淘汰法,当整个链表已满时,淘汰尾部,将新的数据页加入头部 mysql_lru改进 : 分为两部分 yan ...
- mysql执行拉链表操作
拉链表需求: 1.数据量比较大 2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储 ...
- 用十一张图讲清楚,当你CRUD时BufferPool中发生了什么!以及BufferPool的优化!
一.收到了大佬们的建议 1.篇幅偏短,建议稍微加长一点. 这点说的确实挺对,有的篇幅确实比较短,针对这个提议我会考虑将相似的话题放在一篇文章中.但是这可能会导致我中断每天更新的步调,换成隔几天发一篇的 ...
- InnoDB学习(一)之BufferPool
我们知道InnoDB数据库的数据是持久化在磁盘上的,而磁盘的IO速度很慢,如果每次数据库访问都直接访问磁盘,显然严重影响数据库的性能.为了提升数据库的访问性能,InnoDB为数据库的数据增加了内存缓存 ...
- MySQL内核:InnoDB存储引擎 卷1
MySQL内核:InnoDB存储引擎卷1(MySQL领域Oracle ACE专家力作,众多MySQL Oracle ACE力捧,深入MySQL数据库内核源码分析,InnoDB内核开发与优化必备宝典) ...
- 快速入门系列--MySQL
一直说要好好复习一下Mysql都木有时间,终于赶上最近新购买了阿里云,决定使用CentOS去试试.NET Core等相关的开发,于是决定好好的回顾下这部分知识,由于Mysql的数据库引擎是插件式的,对 ...
- MySQL表定义缓存
表定义 MySQL的表包含表名,表空间.索引.列.约束等信息,这些表的元数据我们暂且称为表定义信息. 对于InnoDB来说,MySQL在server层和engine层都有表定义信息.server层的表 ...
随机推荐
- Python+Appium自动化测试(10)-TouchAction类与MultiAction类(控件元素的滑动、拖动,九宫格解锁,手势操作等)
滑动屏幕方法swipe一般用于对页面进行上下左右滑动操作,但自动化过程中还会遇到其他情况,如对控件元素进行滑动.拖拽操作,九宫格解锁,手势操作,地图的放大与缩小等.这些需要针对控件元素的滑动操作,或者 ...
- Git 看这一篇就够了
上一篇讲 Git 的文章发出来没想到效果特别好,很多读者都要求继续深入的写. 那今天齐姐简单讲下 Git 的实现原理,知其所以然才能知其然:并且梳理了日常最常用的 12 个命令,分为三大类分享给你. ...
- windbg加载符号表
0x00 前言 在使用windbg调试windows中的程序时会经常碰到一些系统的dll里面的一些函数调用,有些函数是没有具体函数名的,这对于调试非常不利,基于此,微软针对windows也发布了很多系 ...
- Docker下部署springboot项目
1.背景 如何在docker容器环境下部署一个springboot项目? 2.具体步骤 第一步:准备一个springboot项目的xxxx.jar包 jar包中用于测试的一个接口如下 第二步:编写Do ...
- centos8平台redis5的主从同步搭建及sentinel哨兵配置
一,规划三台redis的ip:一主二从 redismaster01: 172.18.1.1 主 redisslave01: 172.18.1.2 从 redisslave02: 172.18.1.3 ...
- centos8平台使用pstree查看进程树
一,pstree用途 Linux pstree命令将所有行程以树状图显示,树状图将会以 pid (如果有指定) 或是以 systemd 这个基本行程为根 (root) 说明:centos6及更旧版本为 ...
- sql分页 一条语句搞定
select top 每页条数 * from ( SELECT ROW_NUMBER() OVER (ORDER BY id desc) AS RowNumber,* FROM Article 条件 ...
- 第二个 SignalR,可以私聊的聊天室
一.简介 上一次,我们写了个简单的聊天室,接下来,我们来整一个可以私聊的聊天室. SignalR 官方 API 文档 需求简单分析: 1.私聊功能,那么要记录用户名或用户ID,用于发送消息. 2.怎么 ...
- Spring 事件监听
Spring 的核心是 ApplicationContext,它负责管理 Bean的完整生命周期:当加载 Bean 时,ApplicationContext 发布某些类型的事件:例如,当上下文启动时, ...
- js堆排序
堆的预备知识 堆是一个完全二叉树. 完全二叉树: 二叉树除开最后一层,其他层结点数都达到最大,最后一层的所有结点都集中在左边(左边结点排列满的情况下,右边才能缺失结点). 大顶堆:根结点为最大值,每个 ...