Win10环境下Hadoop(单节点伪分布式)的安装与配置--bug(yarn的8088端口打不开+)
一、本文思路
- 【1】、配置java环境–JDK12(Hadoop的底层实现语言是java,hadoop运行需要JDK环境)
- 【2】、安装Hadoop
- 1、解压hadop
- 2、配置hadoop环境变量
- 3、配置Hadoop文件
二、所需下载文件
- 【1】JDK下载地址
【3】hadoop在windows上运行需要winutils支持和hadoop.dll等文件
- 在github仓库中找到对应版本的二进制库hadoop.dll和winutils.exe文件,然后把文件拷贝到hadoop解压的bin目录中去
- 【目前未找到对应的2.9.2版本,这一步未操作】
三、基础知识
- 【1】 Apache Hadoop系统的两个核心组件
- (1)用于存储数据的Hadoop分布式文件系统(HDFS)
- (2)用于实现数据处理的应用程序的Hadoop Yarn
四、JDK12安装配置过程
【1】JDK与JRE比较
- JDK:java安装工具包,包含JRE。因此只需下载JDK即可;
- JRE:java运行环境,用来运行JAVA程序的。
【2】JDK安装—选择默认安装目录即可。
【3】JDK配置–系统变量
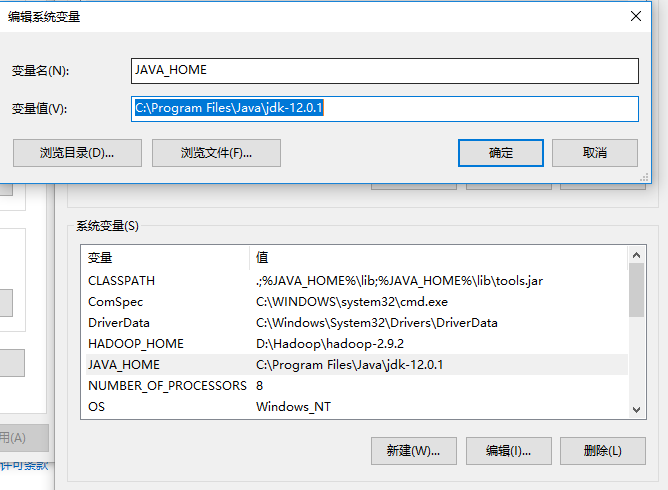
- (1)新建JAVA_HOME变量,变量值填写JDK的安装目录(我的是默认安装环境 C:\Program Files\Java\jdk-12.0.1)。
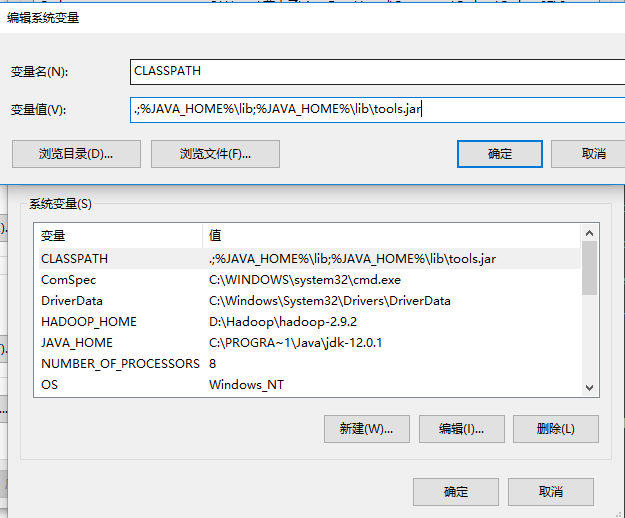
- (2)新建CLASSPATH变量,变量值 .;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar (注意前面有一个点)。
此处注意不要使用相对路径JAVA_HOME,因为重启电脑后cmd执行javac会失败
更改为:

- (3)在path变量值后加 %JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
此处注意不要使用相对路径JAVA_HOME,因为重启电脑后cmd执行javac会失败
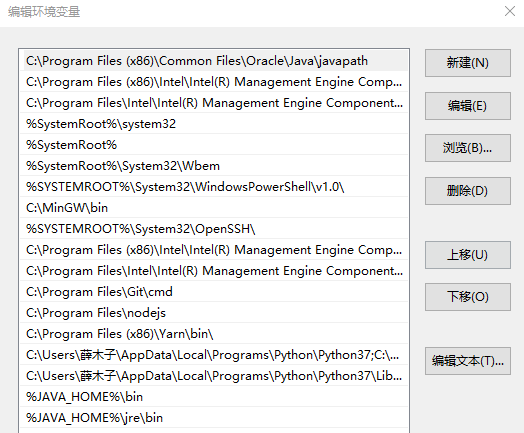
更改为:

- (4)此处注意的是jdk安装目录下是没有jre的,需要手动添加**
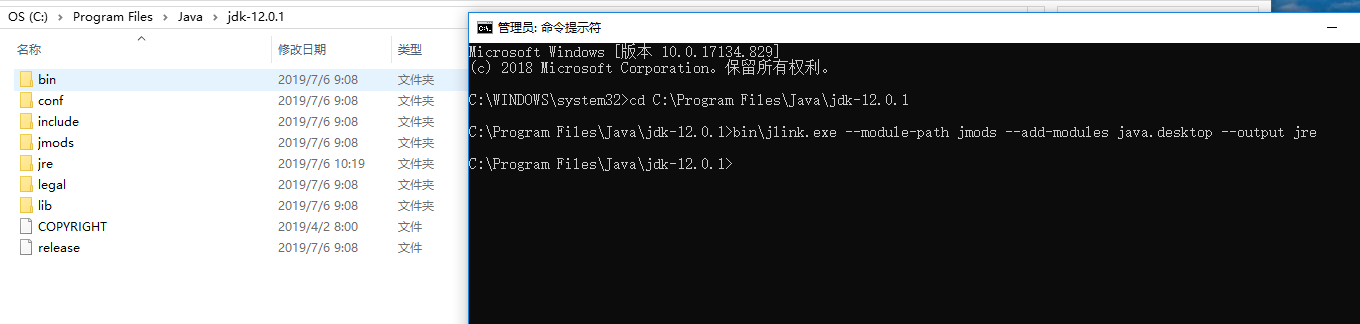
- 1、打开cmd
- 2、切换至jdk安装目录下 (我的是:C:\Program Files\Java\jdk-12.0.1)
- 3、执行 bin\jlink.exe –module-path jmods –add-modules java.desktop –output jre
- 4、结果如下图,在C:\Program Files\Java\jdk-12.0.1下出现jre即可。
- (5)检查是否配置成功,运行cmd,分别输入java, javac, java -version 三个都可执行即为安装配置成功。
五、Hadoop2.9.5安装配置过程
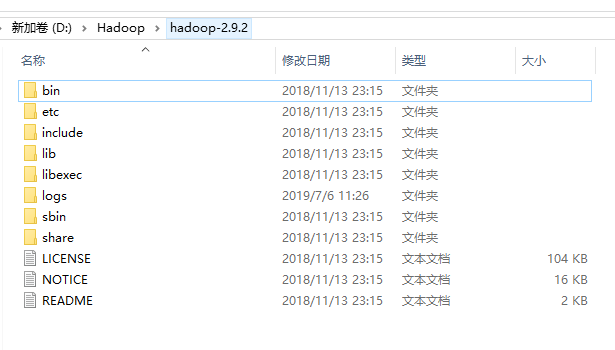
【1】Hadoop安装—下载的安装包直接解压即可(我的在 D:\Hadoop\hadoop-2.9.2 目录)
【2】Hadoop环境配置—系统变量
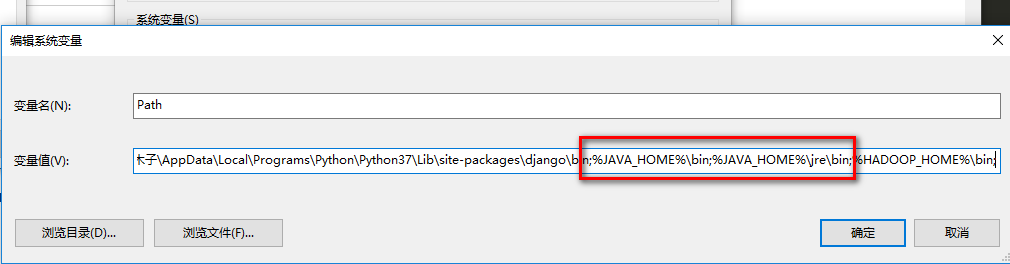
- (1)新建HADOOP_HOME变量,变量值D:\Hadoop\hadoop-2.9.2
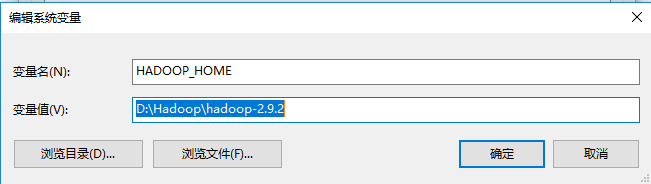
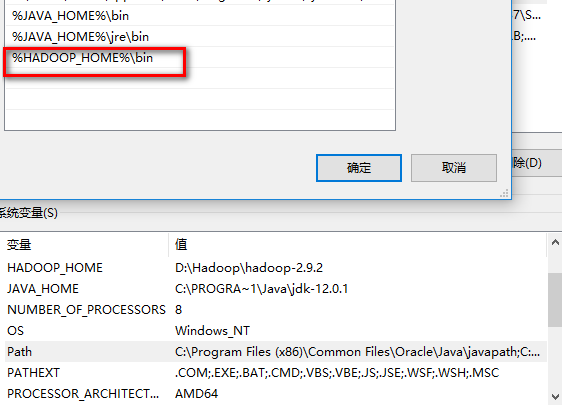
- (2)在path变量值后添加 %HADOOP_HOME%\bin;
- (3)此时测试hadoop是否安装成功会失败:原因是jdk的JAVA_HOME环境变量的配置路径不能有空格(C:\Program Files\Java\jdk-12.0.1),将其中的 Program Files 替换为 PROGRA~1即可。
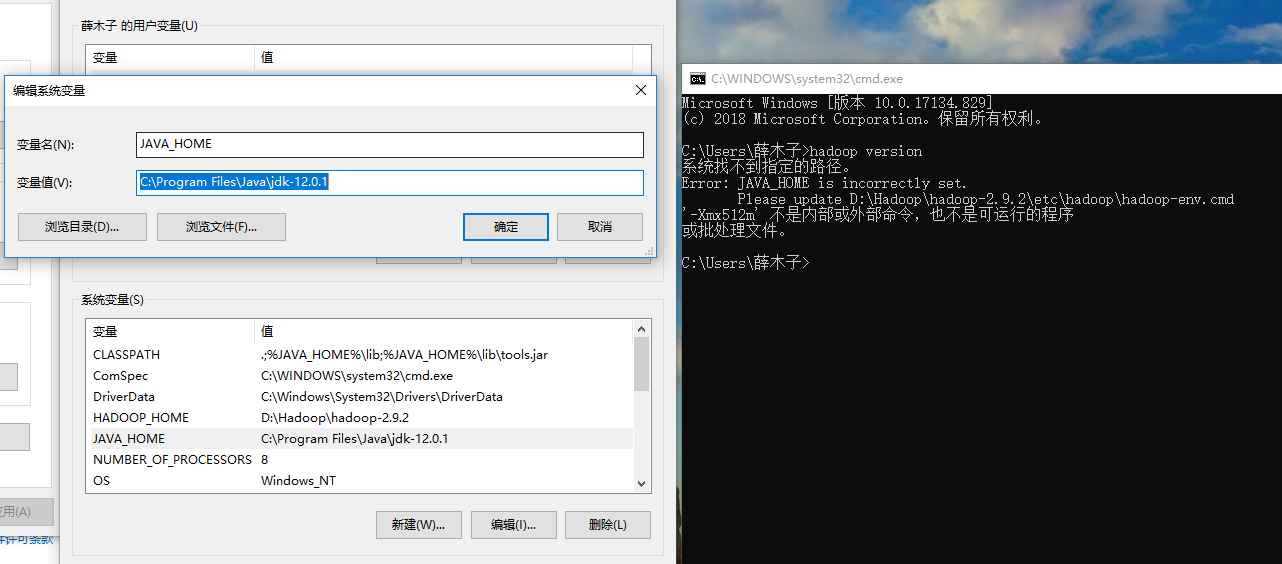
将其中的 Program Files 替换为 PROGRA~1即可
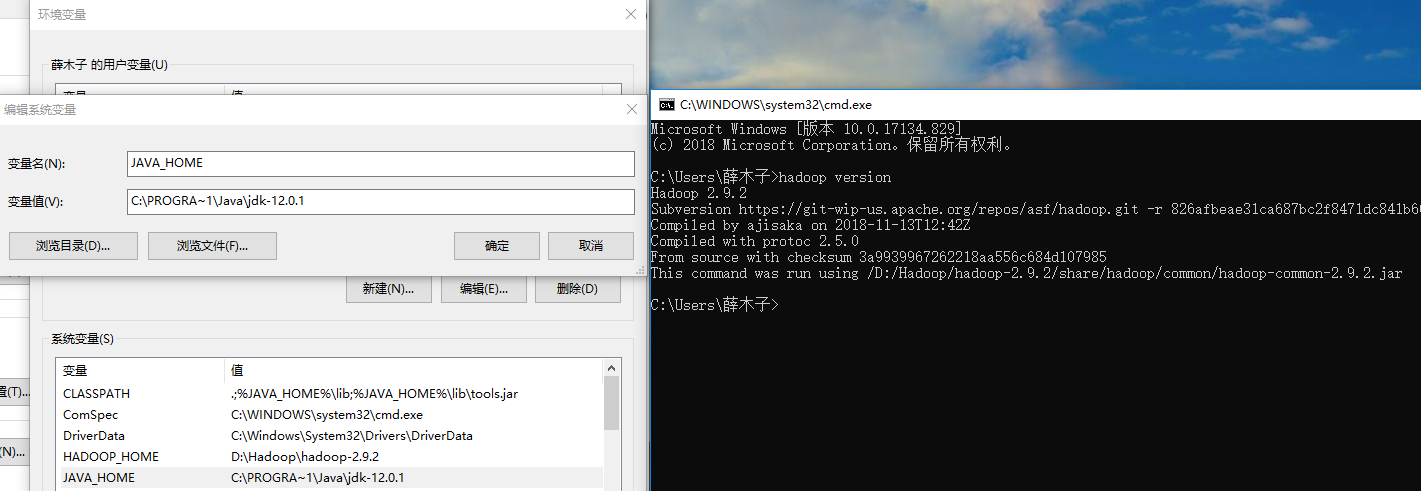
cmd下执行 hadoop version成功,说明hadoop环境配置成功。
【3】 Hadoop伪分布式文件配置
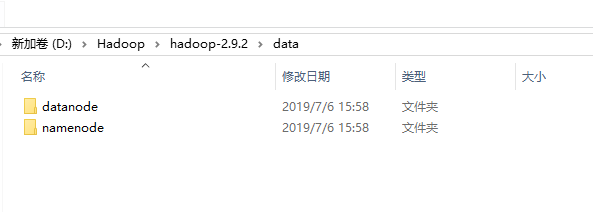
- (1)在hadoop根目录下新建文件夹data,然后在其下创建另个子文件夹datanode和namenode
- (2)确认 ../etc/hadoop/core-site.xml中有如下代码
core-site.xml代码:
<configuration>
<!--fs.defaultFS属性,为NameNode(HDFS元数据的服务器)指定主机名和请求端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- (3)确认../etc/hadoop/mapred-site.xml (如不存在该文件,则将mapred-site.xml.template文件更改为mapred-site.xml)中有如下代码:
mapred-site.xml代码:
<configuration>
<!-- 为MapReduce指定框架名,值为Yarn,告知Mapreduce它将作为Yarn的应用程序运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- (4) 确认../etc/hadoop/hdfs-site.xml中有如下代码 (namenode和datanode是(1)中新建文件的地址)
hdfs-site.xml代码:—cuowu
<configuration>
<!-- hdfs默认为系统文件系统中的每个文件保存3份副本,以作冗余备份,单机版hadoop没有备份需要,设置dfs.replication为1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 此处直接用window下的地址 D:\Hadoop\hadoop-2.9.2\data\namenode 会报错,应改为正斜杠,且磁盘名称前也需要一个正斜杠 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/Hadoop/hadoop-2.9.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/Hadoop/hadoop-2.9.2/data/datanode</value>
</property>
</configuration>
- (5)确认../etc/hadoop/yarn-site.xml中有如下代码
yarn-site.xml代码:
<configuration>
<!-- 属性yarn.nodemanager.aux-services告诉NodeManager需要实现一个名为 mapreduce.shuffle的辅助服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
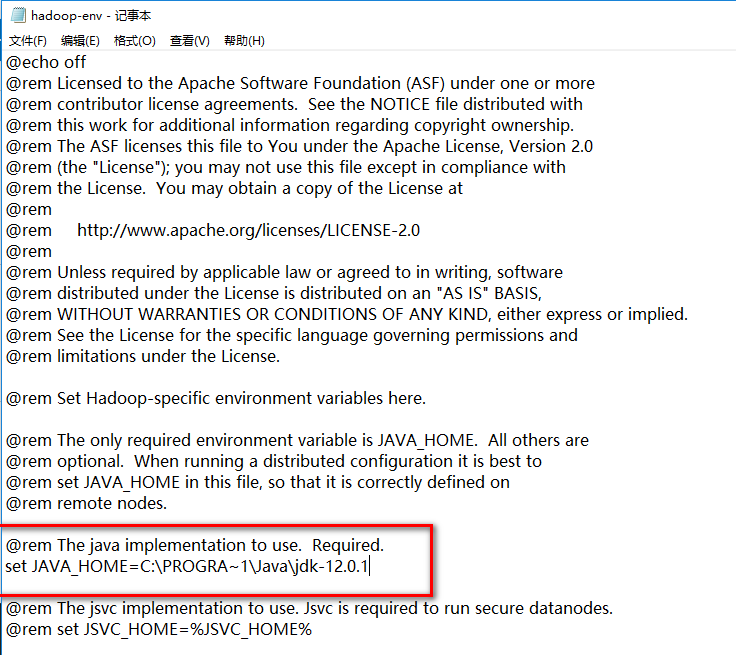
- (6) ../etc/hadoop/hadoop-env.cmd(修改JDK的安装路径)
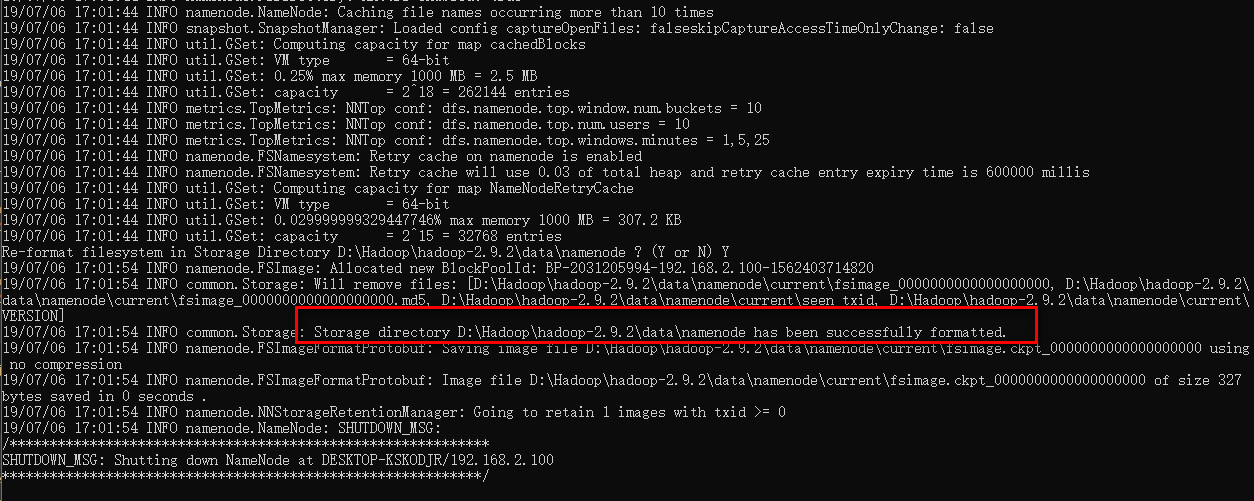
- (7)格式化HDFS文件系统(节点格式化),通过cmd进入文件夹 D:\Hadoop\hadoop-2.9.2\bin
后运行
hdfs namenode -format
执行成功结果:
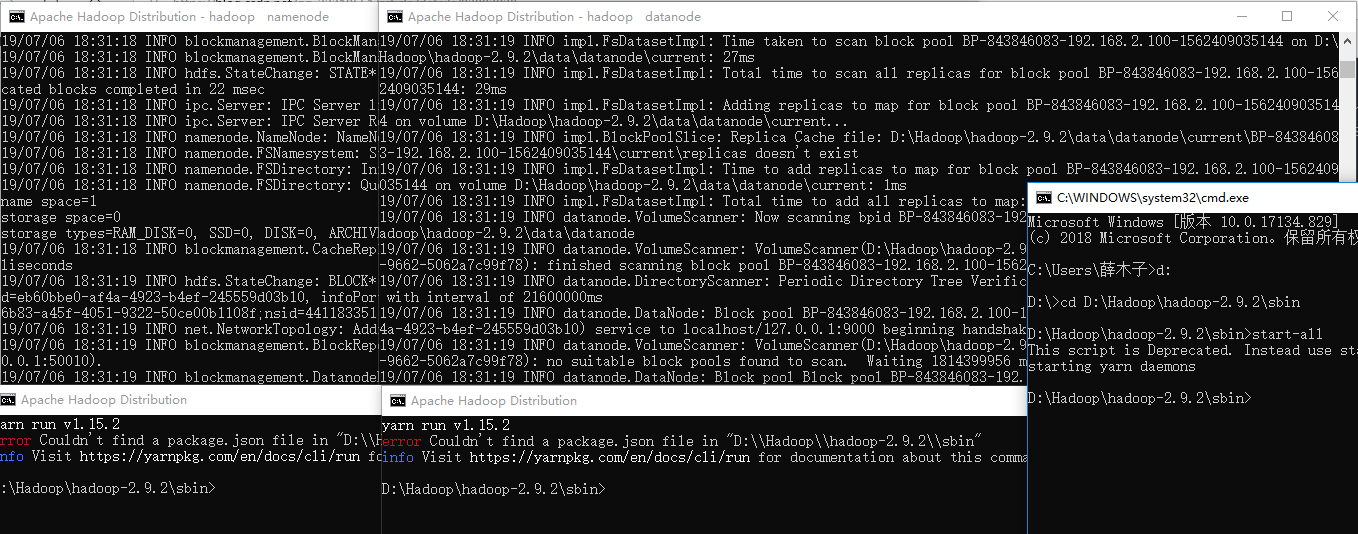
然后进入sbin文件输入:start-all.cmd 之后会有四个窗口跳出来,分别是 * Hadoop Namenode * Hadoop datanode * YARN Resource Manager * YARN Node Manager
(8)hadoop自带的web控制台GUI
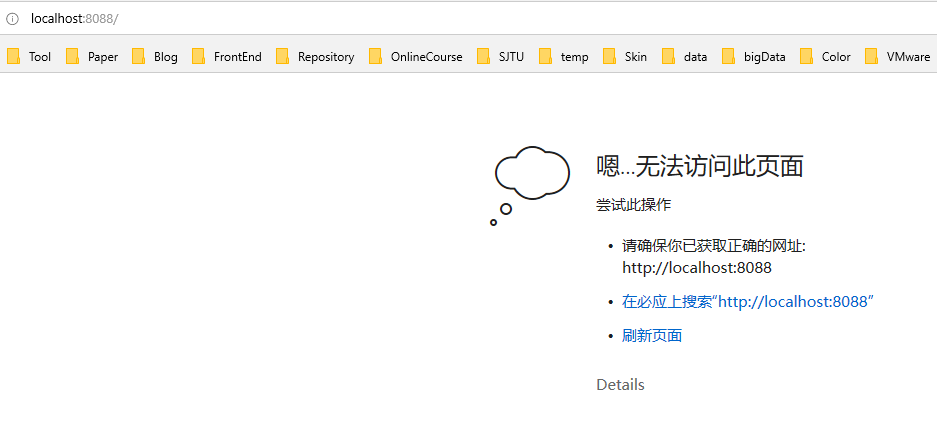
资源管理GUI(yarn的web界面) : http://localhost:8088
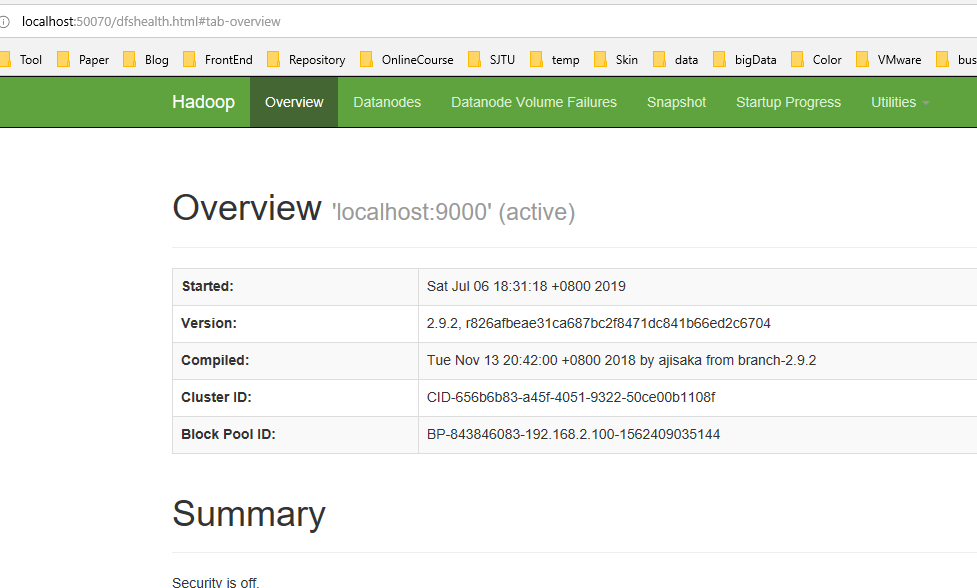
- 节点管理GUI(hdfs的web界面): http://localhost:50070
六、我的问题
五中步骤(7)中格式化hdfs、再输入start-all命令后只出现两个窗口,关于Yarn部分的窗口出现error,http://localhost:8088界面打不开
Win10环境下Hadoop(单节点伪分布式)的安装与配置--bug(yarn的8088端口打不开+)的更多相关文章
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的 了解java的安装配置 学习配置对自己节点的免密码登陆 了解hdfs的配置和相关命令 了解yarn的配置 实验原理 1.Hadoop安装 Hadoop的安装对一个初学者来说是一个很头疼的事情 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- Hadoop单节点启动分布式伪集群
emm~ 写这篇博客只是手痒,因为开发环境用单节点就够了,生产环境肯定是真实集群,所以这个伪分布式纯属娱乐而已. 配置HDFS1. 安装好一台hadoop,可以参考这篇博客.2. 在hadoop目录下 ...
- 单节点伪分布式Hadoop配置
本文所用软件版本: VMware-workstation-full-11.1.0 jdk-6u45-linux-i586.bin ubuntukylin-14.04-desktop-i386.iso ...
- Hbase入门教程--单节点伪分布式模式的安装与使用
Hbase入门简介 HBase是一个分布式的.面向列的开源数据库,该技术来源于 FayChang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就像 ...
- lnmp环境下piwiki网站流量分析工具的安装及配置
piwiki统计网站的安装 Piwik是一个PHP和MySQL的开放源代码的Web统计软件. 它给你一些关于你的网站的实用统计报告,比如网页浏览人数, 访问最多的页面, 搜索引擎关键词等等- Piwi ...
- Hadoop 在windows 上伪分布式的安装过程
第一部分:Hadoop 在windows 上伪分布式的安装过程 安装JDK 1.下载JDK http://www.oracle.com/technetwork/java/javaee/d ...
随机推荐
- 无法将“vue”项识别为 cmdlet、函数、脚本文件或可运行程序的名称
状况 如果在使用 vue 初始化项目的时候提示: vue : 无法将“vue”项识别为 cmdlet.函数.脚本文件或可运行程序的名称.请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次. ...
- 记录一下前端性能优化-为何操作DOM会变慢?
对于大多数前端来说,性能优化的方法可能包括以下这些: 减少HTTP请求(合并css.js,雪碧图/base64图片) 压缩(css.js.图片皆可压缩) 样式表放头部,脚本放底部 使用CDN(这部分, ...
- SpringBoot+MyBatis整合报错Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required
项目启动的时候报这个错误,这个问题我百度了一天,果然不出意外的还是没能解决,其中有一篇文章相对来说还是有点用的:https://blog.csdn.net/qq8693/article/details ...
- github 加速方法
登录网址:https://github.com.ipaddress.com/codeload.github.com#ipinfo 更改hosts:
- Alpha阶段项目复审(鸽牌开发小分队)
团队:鸽牌开发专业小分队 项目:必备记 集合帖:集合帖 项目复审: 团队名字 项目链接 优点 缺点和bug报告 最终名次 歪瑞古德小队 海岛漂流 1.功能齐全,上手简单2.界面简洁美观3.想法新颖,可 ...
- Python输入input、输出print
1.输入input input是用于输入数据给变量.通过键盘输入的是字符串,如果需要其他格式,需要做转换.比如int.float类型数据,int() 如下是一个例子: 如果a不进行int转换,那么输入 ...
- Spring Cloud--尚硅谷2020最新版
Spring Cloud 初识Spring Cloud与微服务 在传统的软件架构中,我们通常采用的是单体应用来构建一个系统,一个单体应用糅合了各种业务模块.起初在业务规模不是很大的情况下,对于单体应用 ...
- 图解 K8s 核心概念和术语
我第一次接触容器编排调度工具是 Docker 自家的 Docker Swarm,主要解决当时公司内部业务项目部署繁琐的问题,我记得当时项目实现容器化之后,花在项目部署运维的时间大大减少了,当时觉得这玩 ...
- Python 中的数字到底是什么?
花下猫语:在 Python 中,不同类型的数字可以直接做算术运算,并不需要作显式的类型转换.但是,它的"隐式类型转换"可能跟其它语言不同,因为 Python 中的数字是一种特殊的对 ...
- CMOS设计手册—基础篇
模拟CMOS 衬底噪声:由于相邻的电阻互相注入电流而产生的衬底噪声.解决方法:在两个电阻之间加入一个P+注入区(作为P衬底晶圆的衬底接触).P+注入区保护电路免受载流子的影响,由于注入区是一个环形,所 ...