Kaggle-pandas(1)
Creating-reading-and-writing
教程
1.创建与导入
DataFrame
import pandas as pd
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
生成的表如下:
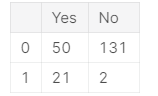
我们正在使用pd.DataFrame()构造函数来生成这些DataFrame对象。 声明新字典的语法是字典,其关键字是列名(在此示例中为Yes和No),其值是条目列表。 这是构造新DataFrame的标准方法,也是您最有可能遇到的一种方法。
字典列表构造函数将值分配给列标签,但仅对行标签使用从0(0、1、2、3,...)开始的递增计数。 有时这可以,但是通常我们会自己分配这些标签。
DataFrame中使用的行标签列表称为索引。 我们可以通过在构造函数中使用index参数来为其赋值:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])

Series
相比之下,系列是数据值的序列。 如果DataFrame是表,则Series是列表。 实际上,您可以创建一个只包含一个列表的列表:
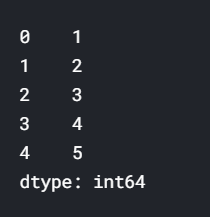
本质上,Series是DataFrame的单个列。 因此,您可以使用索引参数,以与以前相同的方式将列值分配给Series。 但是,系列没有列名,只有一个整体名:
Series和DataFrame密切相关。 认为DataFrame实际上只是一堆“胶合在一起”的Series很有帮助。 我们将在本教程的下一部分中看到更多信息。
2.读取数据文件
能够手动创建DataFrame或Series很方便。 但是,在大多数情况下,我们实际上不会手工创建自己的数据。 相反,我们将使用已经存在的数据。
数据可以多种不同形式和格式存储。 到目前为止,最基本的是不起眼的CSV文件。 当您打开CSV文件时,您将获得如下所示的内容:

因此,CSV文件是由逗号分隔的值表。 因此,名称为:“逗号分隔值(Comma-Separated Values")”或CSV。
现在让我们搁置玩具数据集,看看当我们将其读入DataFrame时真实数据集的外观。 我们将使用pd.read_csv()函数将数据读取到DataFrame中。
Kaggle-pandas(1)的更多相关文章
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- Kaggle入门教程
此为中文翻译版 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中最 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle之Grupo Bimbo Inventory Demand
Grupo Bimbo Inventory Demand kaggle比赛解决方案集合 Grupo Bimbo Inventory Demand 在这个比赛中,我们需要预测某个产品在某个销售点每周的需 ...
- kaggle之人脸特征识别
Facial_Keypoints_Detection github code facial-keypoints-detection, 这是一个人脸识别任务,任务是识别人脸图片中的眼睛.鼻子.嘴的位置. ...
随机推荐
- node+express4+multiparty实现简单文件上传
文件上传 var fs = require('fs'); var express = require('express'); var multiparty = require('multiparty' ...
- python 生成器(五):生成器实例(一)创建数据处理管道
问题 你想以数据管道(类似Unix管道)的方式迭代处理数据. 比如,你有个大量的数据需要处理,但是不能将它们一次性放入内存中. 解决方案 生成器函数是一个实现管道机制的好办法. 为了演示,假定你要处理 ...
- 轮播图-bxslider
bxSlider下载+参数说明 “bxSlider”就是一款响应式的幻灯片js插件 bxSlider特性 充分响应各种设备,适应各种屏幕: 支持多种滑动模式,水平.垂直以及淡入淡出效果: 支持图片.视 ...
- 使用Azure Application Insignhts监控ASP.NET Core应用程序
Application Insignhts是微软开发的一套监控程序.他可以对线上的应用程序进行全方位的监控,比如监控每秒的请求数,失败的请求,追踪异常,对每个请求进行监控,从http的耗时,到SQL查 ...
- Java 分布式任务调度平台:PowerJob 快速开始+配置详解
本文适合有 Java 基础知识的人群 作者:HelloGitHub-Salieri 引言 HelloGitHub 推出的<讲解开源项目>系列. 项目地址: https://github.c ...
- 一、Python系列——函数的应用之名片管理系统
card_list = [] def main_desk(): print('*'*50) print('欢迎使用[名片管理系统]V1.0') print('1.新建名片') print('2.显示全 ...
- IDEA 导入maven 项目,出现报错,不能运行之类的
选择pom.xml,右键选择 Add as Maven Project
- kubernetes系列(十七) - 通过helm安装dashboard详细教程
1. 前提条件 2. 配置https证书为secret 3. dashboard安装 3.1 helm拉取dashboard的chart 3.2 配置dashboard的chart包配置 3.3 he ...
- 016.Nginx HTTPS
一 HTTPS概述 1.1 HTTPS介绍 超文本传输安全协议HTTPS(Hypertext Transfer Protocol Secure)是超文本传输协议和SSL/TLS的组合,用以提供加密通讯 ...
- GitHub和码云gitee及远程仓库管理
目录 备注: 知识点 GitHub 码云(gitee.com) gitee的使用 本地版本库关联多个远程库 备注: 本文参考于廖雪峰老师的博客Git教程.依照其博客进行学习和记录,感谢其无私分享,也欢 ...