k 分算法是 k 越大越好吗?
引入
我们有二分算法,就是:
定义
二分查找(英语:binary search),也称折半搜索(英语:half-interval search)、对数搜索(英语:logarithmic search),是用来在一个有序数组中查找某一元素的算法。
过程
以在一个升序数组中查找一个数为例。
它每次考察数组当前部分的中间元素,如果中间元素刚好是要找的,就结束搜索过程;如果中间元素小于所查找的值,那么左侧的只会更小,不会有所查找的元素,只需到右侧查找;如果中间元素大于所查找的值同理,只需到左侧查找。
能不能有三分算法呢?正当我以为这是一个天才的想法时,我发现:
如果需要求出单峰函数的极值点,通常使用二分法衍生出的三分法求单峰函数的极值点。
三分法与二分法的基本思想类似,但每次操作需在当前区间 \([l,r]\)内任取两点 \(lmid,rmid(lmid < rmid)\)。如果 \(f(lmid)<f(rmid)\),则在 \([rmid,r]\)中函数必然单调递增,最小值所在点(下图中的绿点)必然不在这一区间内,可舍去这一区间。反之亦然。
以上皆来自OI-WIKI
注意,这里我指的三分并不是求单峰函数中的三分,它只能求单调函数,每次去掉三分之二的部分。
那么,既然有三分了,有没有四分、五分、六分甚至 \(k\) 分呢?\(k\) 分算法存在有意义吗(\(k>3\))?\(k\) 分算法是 \(k\) 越大越好吗?
于是,我的思索开始了。
本文仅代表个人观点,计算过程如有不严谨,希望您原谅并指出,时间复杂度忽略了部分时间,不代表最终结果。
最后 sto各位大佬
思索
\(k\) 分算法的复杂度为 \(k\log_kN\),那么我们就需要知道 \(k\) 取什么才能让它最小。
证明
下面我们证明
\]
在 \(k>1,N>1\) 情况下的极小值时 \(k\) 的取值。
当我们要证明一个函数的极小值时的取值时,我们可以通过求导的方式。那么我们不得不引出导数这个概念。
我懒得写,大家请看:这里
那么一句话总结,导数就是函数在某点的切线的斜率,例如下面这张图:
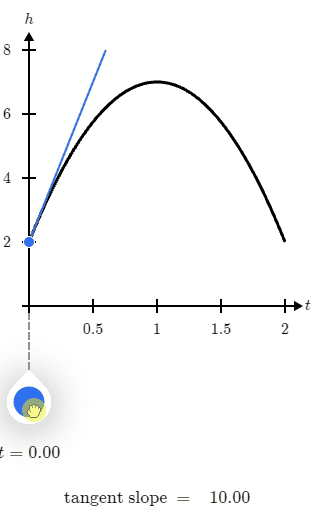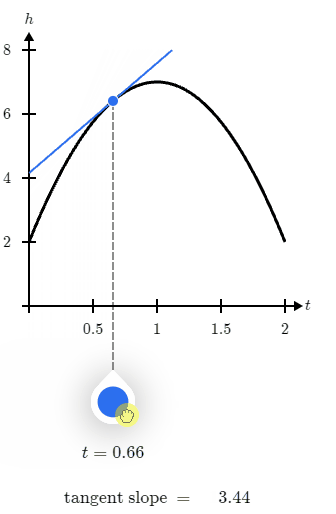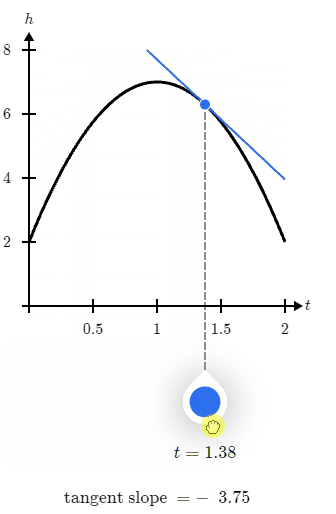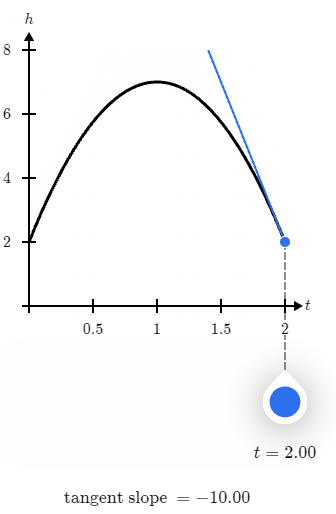
那么在导数函数结果等于0时,当前结果是极大值还是极小值呢?
极大值
噢,错啦
极小值
噢,错啦
其他(干脆你说你想看答案)
答对啦,正确答案是有可能是极大值也有可能是极小值(没想到吧)
往下翻
当导数函数结果等于0时,当前有可能是最大值也有可能是极小值,我们称这个点为临界点。我们可以检查临界点的邻域,即临界点的左右两侧。如果在临界点的左侧函数值递增,右侧函数值递减,则该点为最大值。如果在临界点的左侧函数值递减,右侧函数值递增,则该点为极小值。
接下来,我们的问题就变成了求:
\]
时 \(k\) 的取值。
$f'$ 是什么
就是 $f$ 函数的导数
根据换底公式, \(\log_kN = \frac{\ln N}{\ln k}\),我们可以将 \(f(k)\) 重写为 \(f(k) = \frac{k}{\ln k} \ln N\)。
换底公式证明
要证明 $\log_kN=\frac{\log_bN}{\log_bk}$ (换底公式)
$$
\text{设} y=\log_kN
$$
\]
\]
\]
\]
首先,可以使用乘法法则对函数 \(f(k)\) 进行求导。
根据乘法法则,若有两个函数 \(u(k)\) 和 \(v(k)\),那么:
\]
代入它,得到:
\]
其中,我们知道, \(N\) 是一个常数,那么 \(\ln N\) 也是一个常数。根据导数的定义,常数的导数为0。
你要我证明?
你看,常数的斜率不就是0吗
我们现在化简后知道:
\]
那么,\((\frac{k}{\ln k})'\) 又是多少呢?
这时,我们的任务变成了求 \((\frac{k}{\ln k})'\),可以使用除法法则进行求导。
根据除法法则,若有两个函数 \(u(k)\) 和 \(v(k)\),那么:
\]
代入它,得到:
\]
因为 \(k\) 是一个自变量,所以它的导数为1(可以画图看,它的斜率是不是1),同时根据导数表,我们知道 \(\ln(k)'=\frac{1}{k}\),代入得:
\]
再代回上面那个:
\]
求导完成,撒花!!!\(@0@)/
然后就简单了,因为
\]
所以:
\]
所以:
\]
因为 \(N > 1\),所以 \(\ln (k)-1=0\),\(\ln k=1\)
那么 \(k\) 是几?当然是 \(k=e\) 啦!!!
大家感兴趣的还可以尝试二阶导数,然后判断二阶导数是否大于0,当二阶导数大于零时,该点为极小值点;当该点的二阶导数小于零时,该点为极大值点。(费马引理)
下面补上二阶导数的计算过程:
因为 \((c\cdot u(k))'=c\cdot u'(k)\) (大家可以用乘法法则自己证一下,这里 \(c\) 为常数)
\]
\]
\]
根据除法法则:
\]
根据加减法则(\((u(k)-v(k))'=u'(k)-v'(k)\)):
\]
\]
\]
根据链式法则(设 \(y=f(u),u=g(k)\),则 \(y'(k)=f'(u)\cdot g'(k)\)),且因为 \((x^\alpha)'=\alpha x^{\alpha-1}\)
\]
\]
\]
\]
\]
我们发现,当 \(k=e\) 该二阶导数大于0,故该点为极小值点。
那么好了,当我们进行 \(e\) 分时时间复杂度最少,但是我们总不能进行 2.718 分吧?所以我们取一个整数值,2或者3。
代入后可以得到,3的斜率更小,故选择3。
upd:假的,二分更优,因为三分查询数组次数过多当数据大(10000组10000000的数据)时会慢几毫秒
k 分算法是 k 越大越好吗?的更多相关文章
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- [机器学习系列] k-近邻算法(K–nearest neighbors)
C++ with Machine Learning -K–nearest neighbors 我本想写C++与人工智能,但是转念一想,人工智能范围太大了,我根本介绍不完也没能力介绍完,所以还是取了他的 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- K临近算法
K临近算法原理 K临近算法(K-Nearest Neighbor, KNN)是最简单的监督学习分类算法之一.(有之一吗?) 对于一个应用样本点,K临近算法寻找距它最近的k个训练样本点即K个Neares ...
随机推荐
- 【从0开始编写webserver·基础篇#03】TinyWeb源码阅读,还是得看看靠谱的项目
[前言] 之前通过看书.看视频和博客拼凑了一个webserver,然后有一段时间没有继续整这个项目 现在在去看之前的代码,真的是相当之简陋,而且代码设计得很混乱,我认为没有必要继续在屎堆上修改了,于是 ...
- 一张图告诉你如何提高 API 性能
API 性能是指一个 API 在执行其功能时的效率和性能表现,通常用于衡量 API 的响应时间.吞吐量.可伸缩性和稳定性等方面的表现. API 性能的指标包括: 响应时间: API 的响应时间是指从发 ...
- 【Redis】基础命令
声明:本篇文章参考于该作者的# Redis从入门到精通:中级篇,大家有兴趣,去关注一下. 1.字符串(String) String(字符串)是Redis中最简单的一种数据结构,和MemCache数据结 ...
- Typecho handsome主题一言接口修改
说明 handsome主题默认使用的是 https://v1.hitokoto.cn 一言接口 博主感觉不是太满意,于是想换成自己的"一言"服务接口 首先需要自己搭建一个" ...
- Redis的设计与实现(4)-跳跃表
跳跃表 (skiplist) 是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的. 跳跃表支持平均 O(log N) 最坏 O(N) 复杂度的节点查找, ...
- 河南省第十四届icpc大学生程序设计竞赛-clk
这次比赛赛程比较长,520出发,521,回学校,出发的那一天有点热,感觉不是很好,而且那一天感觉有点生病,应该只是普通感冒,热身赛的时候被oier吊打,省实验真厉害,晚上回酒店后,我喊队友,补了前年的 ...
- Blazor前后端框架Known-V1.2.5
V1.2.5 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行. Gitee: https://gitee.com/known/Known Gith ...
- 进程相关API
ID与句柄 如果我们成功创建一个进程,CreateProcess函数会给我们返回一个结构体,包括四个数 据:进程编号(ID).进程句柄.线程编号(ID).线程句柄. 进程ID其实我们早见过了,通常我们 ...
- 关于NOI2010“超级钢琴”的反思
[NOI2010] 超级钢琴 题目描述 小 Z 是一个小有名气的钢琴家,最近 C 博士送给了小 Z 一架超级钢琴,小 Z 希望能够用这架钢琴创作出世界上最美妙的音乐. 这架超级钢琴可以弹奏出 \(n\ ...
- Flutter系列文章-Flutter进阶2
这一节我将再详细地为您介绍 Flutter 进阶主题,包括导航和路由.状态管理.异步处理.HTTP请求和Rest API,以及数据持久化.让我们逐个介绍这些主题. 1.导航和路由 在 Flutter ...