k邻近算法(KNN)实例
一 k近邻算法原理
k近邻算法是一种基本分类和回归方法.
原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的
多数属于某个类,就把该输入实例分类到这个类中。
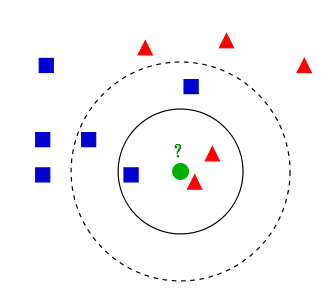
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类。
- 如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
参考一文搞懂k近邻(k-NN)算法(一) https://zhuanlan.zhihu.com/p/25994179
二 特点
优点:精度高(计算距离)、对异常值不敏感(单纯根据距离进行分类,会忽略特殊情况)、无数据输入假定
(不会对数据预先进行判定)。
缺点:时间复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
三 欧氏距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
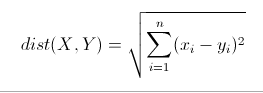
四 sklearn库中使用k邻近算法
- 分类问题:from sklearn.neighbors import KNeighborsClassifier
- 回归问题:from sklearn.neighbors import KNeighborsRegressor
五 使用sklearn的K邻近简单实例
1 数据蓝蝴蝶
#导包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
from sklearn.neighbors import KNeighborsClassifier #k邻近算法模型 #使用datasets创建数据
import sklearn.datasets as datasets
iris = datasets.load_iris() feature = iris['data']
target = iris['target'] #将样本打乱,符合真实情况 np.random.seed(1)
np.random.shuffle(feature)
np.random.seed(1)
np.random.shuffle(target) #训练数据
x_train = feature[:140]
y_train = target[:140]
#测试数据
x_test = feature[-10:]
y_test =target[-10:] #实例化模型对象&训练模型
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(x_train,y_train)
knn.score(x_train,y_train) print('预测分类:',knn.predict(x_test))
print('真实分类:',y_test)
2 根据身高、体重、鞋子尺码,预测性别
#导包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series #手动创建训练数据集
feature = np.array([[170,65,41],[166,55,38],[177,80,39],[179,80,43],[170,60,40],[170,60,38]])
target = np.array(['男','女','女','男','女','女']) from sklearn.neighbors import KNeighborsClassifier #k邻近算法模型 #实例k邻近模型,指定k值=3
knn = KNeighborsClassifier(n_neighbors=3) #训练数据
knn.fit(feature,target) #模型评分
knn.score(feature,target) #预测
knn.predict(np.array([[176,71,38]]))
3 手写数字识别
- 导包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier
- 查看单一图片特征
img=plt.imread('data/0/0_2.bmp')
plt.imshow(img)

- 提炼样本数据
feature=[]
target=[]
for i in range(10):
for j in range(500):
img_arr=plt.imread(f'data/{i}/{i}_{j+1}.bmp')
feature.append(img_arr)
target.append(i) #构建特征数据格式
feature=np.array(feature)
target=np.array(target) feature.shape #(5000, 28, 28) #输入数据必须是二维数组,必须对feature降维
#(1)降维方式一:mean() (2)降维方式二:reshape()
feature=feature.reshape(5000,28*28) #将样本打乱 (必须使用多个seed)
np.random.seed(5)
np.random.shuffle(feature)
np.random.seed(5)
np.random.shuffle(target) #数据分割为训练数据和测试数据
x_train=feature[:4950]
y_train=target[:4950]
x_test=feature[-50:]
y_test=target[-50:]
- KNN模型建立和评分
#训练模型
knn.fit(x_train,y_train) #评分
knn.score(x_train,y_train) #预测
# knn.predict(x_test)
- 真实预测手写数字图片的一般流程
# 读取图片数据
num_img_arr=plt.imread('../../数字.jpg')
plt.imshow(num_img_arr)
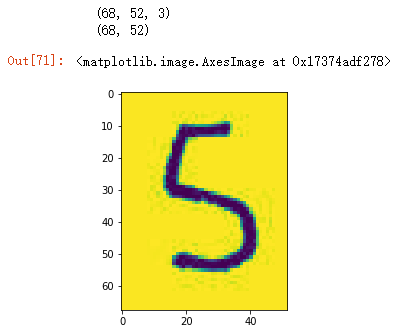
#图片截取数字5
five_arr=num_img_arr[90:158,80:132]
plt.imshow(five_arr)

#降维操作(five数组是三维的,需要进行降维,舍弃第三个表示颜色的维度)
print(five_arr.shape) #(65, 56, 3)
five=five_arr.mean(axis=2)
print(five.shape) #(65, 56)
plt.imshow(five)
# 图片压缩为像素28*28
import scipy.ndimage as ndimage
five = ndimage.zoom(five,zoom = (28/68,28/52))
five.shape #(28, 28) # 压缩后的5的显示
plt.imshow(five)
# 把数据降维为feature 数据格式
five.reshape(1,28*28)
#预测
knn.predict(five.reshape(1,28*28))

下载源数据和代码:https://github.com/angleboygo/data_ansys
k邻近算法(KNN)实例的更多相关文章
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
- 机器学习算法及代码实现–K邻近算法
机器学习算法及代码实现–K邻近算法 1.K邻近算法 将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近 ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)
一.前言 kaggle上有传统的手写数字识别mnist的赛题,通过分类算法,将图片数据进行识别.mnist数据集里面,包含了42000张手写数字0到9的图片,每张图片为28*28=784的像素,所以整 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
随机推荐
- BZOJ_3831_[Poi2014]Little Bird_单调队列优化DP
BZOJ_3831_[Poi2014]Little Bird_单调队列优化DP Description 有一排n棵树,第i棵树的高度是Di. MHY要从第一棵树到第n棵树去找他的妹子玩. 如果MHY在 ...
- B20J_2007_[Noi2010]海拔_平面图最小割转对偶图+堆优化Dij
B20J_2007_[Noi2010]海拔_平面图最小割转对偶图+堆优化Dij 题意:城市被东西向和南北向的主干道划分为n×n个区域.城市中包括(n+1)×(n+1)个交叉路口和2n×(n+1)条双向 ...
- ELK 架构之 Elasticsearch、Kibana、Logstash 和 Filebeat 安装配置汇总(6.2.4 版本)
相关文章: ELK 架构之 Elasticsearch 和 Kibana 安装配置 ELK 架构之 Logstash 和 Filebeat 安装配置 ELK 架构之 Logstash 和 Filebe ...
- CentOS7 安装Redis 单机版
1,下载Redis4.0.9 进入Redis中文网的下载页面 http://www.redis.cn/download.html 2,上传压缩包到linux系统 cd /user/local/java ...
- java IO流全面总结
流的概念和作用 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作. Ja ...
- Redis详解(二)------ redis的配置文件介绍
上一篇博客我们介绍了如何安装Redis,在Redis的解压目录下有个很重要的配置文件 redis.conf (/opt/redis-4.0.9目录下),关于Redis的很多功能的配置都在此文件中完成的 ...
- java基础(六)-----String性质深入解析
本文将讲解String的几个性质. 一.String的不可变性 对于初学者来说,很容易误认为String对象是可以改变的,特别是+链接时,对象似乎真的改变了.然而,String对象一经创建就不可以修改 ...
- String求求你别秀了
小鲁班今年计算机专业大四了,在学校可学了不少软件开发的东西,也自学了一些JAVA的后台框架,踌躇满志,一心想着找个好单位实习.当投递了无数份简历后,终于收到了一个公司发来的面试通知,小鲁班欣喜若狂. ...
- 【view绘制流程】理解
一.概述 View的绘制是从上往下一层层迭代下来的.DecorView-->ViewGroup(--->ViewGroup)-->View ,按照这个流程从上往下,依次measure ...
- Asp.NetCore轻松学-部署到 IIS 进行托管
前言 经过一段时间的学习,终于来到了部署服务这个环节,.NetCore 的部署方式非常的灵活多样,但是其万变不离其宗,所有的 Asp.NetCore 程序都基于端口的侦听,在部署的时候仅需要配置侦听地 ...