flink scala 从Oracle同步数据到MySql
pom
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<!-- Scala Library, provided by Flink as well. -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>compile</scope>
</dependency>
<!-- Add connector dependencies here. They must be in the default scope (compile). -->
<!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
-->
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.1.0.7.0-Production</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
</dependencies>
Job_Data_Oracle_To_MySql.scala
package org.myorg.quickstart
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet, Timestamp}
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
object Job_Data_Oracle_To_MySql {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.addSource(new OracleSource)
.name("OracleSource")
.addSink(new MySqlSink)
.name("MySqlSink")
.setParallelism(1)
env.execute("Data From Oracle To MySql")
}
def NowDate(): String = {
val now: Date = new Date()
val dateFormat: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
val date = dateFormat.format(now)
return date
}
}
case class TB_TEST01(ID: Int, NAME: String, CTIME: Date)
class OracleSource extends RichSourceFunction[TB_TEST01] {
var conn: Connection = _
var selectStmt: PreparedStatement = _
var isRunning: Boolean = true
override def open(parameters: Configuration): Unit = {
// 加载驱动
Class.forName("oracle.jdbc.driver.OracleDriver")
// 数据库连接
conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521/orcl", "lxw", "123456")
selectStmt = conn.prepareStatement("select * from TB_TEST01")
}
override def run(sourceContext: SourceFunction.SourceContext[TB_TEST01]): Unit = {
while (isRunning) {
var resultSet: ResultSet = selectStmt.executeQuery()
while (resultSet.next()) {
var ID: Int = resultSet.getInt("ID")
var NAME: String = resultSet.getString("NAME")
var CTIME: Date = resultSet.getTimestamp("CTIME")
sourceContext.collect(TB_TEST01(ID, NAME, CTIME))
}
println(Job_Data_Oracle_To_MySql.NowDate() + "暂停5秒")
Thread.sleep(5000)
}
}
override def close(): Unit = {
selectStmt.close()
conn.close()
}
override def cancel(): Unit = {
isRunning = false
}
}
class MySqlSink extends RichSinkFunction[TB_TEST01] {
var conn: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
override def open(parameters: Configuration): Unit = {
Class.forName("com.mysql.cj.jdbc.Driver")
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&useSSL=false&autoReconnect=true&serverTimezone=UTC"
, "root"
, "123456")
insertStmt = conn.prepareStatement("INSERT INTO `test`.`tb_test01`(`id`, `name`, `ctime`) VALUES (?, ?, ?)")
updateStmt = conn.prepareStatement("UPDATE `test`.`tb_test01` SET `name` = ?, `ctime` =? WHERE `id` = ?")
}
override def invoke(value: TB_TEST01, context: SinkFunction.Context[_]): Unit = {
// 执行更新语句
updateStmt.setString(1, value.NAME)
updateStmt.setTimestamp(2, new Timestamp(value.CTIME.getTime))
updateStmt.setInt(3, value.ID)
updateStmt.execute()
//如果update没有更新 即 没有查询到数据 即 没有该id 那么执行插入
if (updateStmt.getUpdateCount == 0) {
println(Job_Data_Oracle_To_MySql.NowDate() + "------------------插入数据>>" + value)
insertStmt.setInt(1, value.ID)
insertStmt.setString(2, value.NAME)
insertStmt.setTimestamp(3, new Timestamp(value.CTIME.getTime))
insertStmt.execute()
} else {
println(Job_Data_Oracle_To_MySql.NowDate() + "------------------更新数据>>" + value)
}
}
}
控制台输出
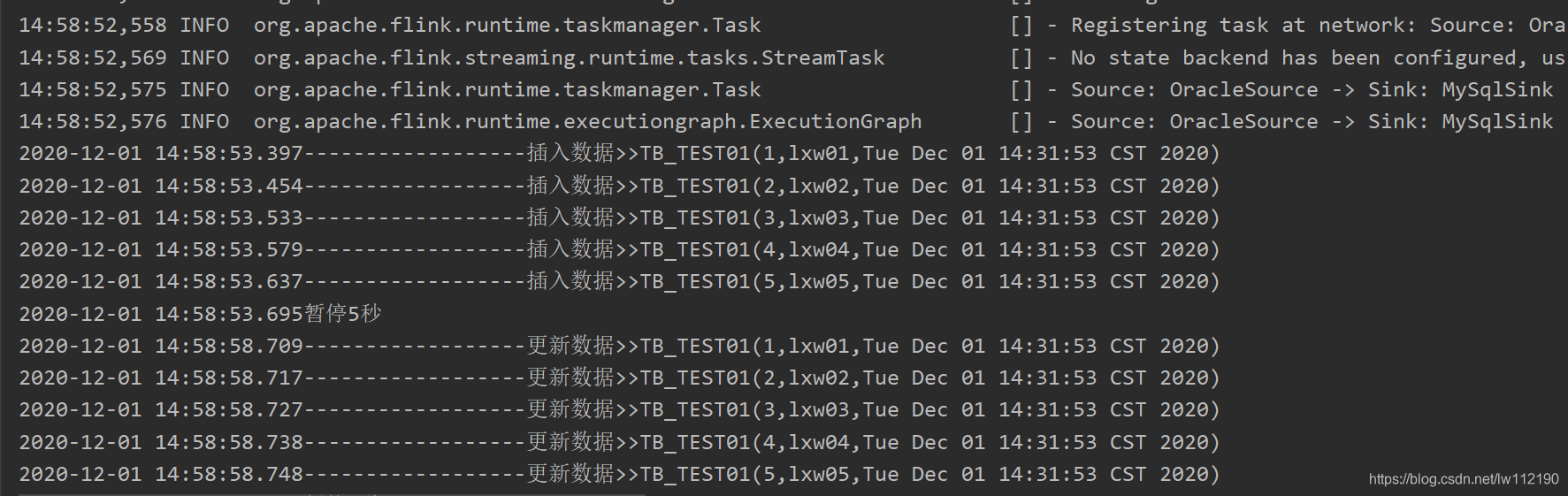
Oracle中

MySql中

flink scala 从Oracle同步数据到MySql的更多相关文章
- Flink 异步IO访问外部数据(mysql篇)
接上篇:[翻译]Flink 异步I / O访问外部数据 最近看了大佬的博客,突然想起Async I/O方式是Blink 推给社区的一大重要功能,可以使用异步的方式获取外部数据,想着自己实现以下,项目上 ...
- 定时执行rsync同步数据以及mysql备份
需求:把机器A中的附件.图片等,备份到备份机B中.将数据库进行备份 附件备份 在A中,启动rsync服务,编辑/etc/xinetd.d/rsync文件,将其中的disable=yes改为disabl ...
- 大数据批量导入,解决办法,实践从定时从 sqlserver 批量同步数据到 mySql
c#代码,批量导入数据代码 public class MySql_Target : ZFCommon.DataAccesser.Base.DABase { public MySql_Target() ...
- ORACLE GOLDEN GATE oracle同步数据至kafka
一.服务器信息 ip 软件版本 ogg版本 软件包 操作系统版本 OGG安装路径 10.1.50.52 源 oracle11.2.0.4 12.2.0.1.1 V100692-01.zip cen ...
- 从Oracle同步数据到SQLServer——大小写敏感设置
Oracle默认是大小写敏感,而SQLServer默认大小写不敏感, 尤其是涉及主键字段时,注意请提前设置SQLServer对应的数据库表为大小写敏感,不然会报主键冲突的错误. 设置表内大小写敏感 A ...
- Clickhouse单机部署以及从mysql增量同步数据
背景: 随着数据量的上升,OLAP一直是被讨论的话题,虽然druid,kylin能够解决OLAP问题,但是druid,kylin也是需要和hadoop全家桶一起用的,异常的笨重,再说我也搞不定,那只能 ...
- 实现从Oracle增量同步数据到GreenPlum
简介: GreenPlum是一个基于PostgreSQL数据库开发的MPP架构的数据库仓库,适用于OLAP系统,支持50PB(1PB=1000TB)级海量数据的存储和处理. 背景: 目前有一个业务是需 ...
- 将数据从MySQL迁移到Oracle的注意事项
将数据从MySQL迁移到Oracle的注意事项1.自动增长的数据类型处理MYSQL有自动增长的数据类型,插入记录时不用操作此字段,会自动获得数据值.ORACLE没有自动增长的数据类型,需要建立一个自动 ...
- 使用MySQL Migration Toolkit快速将Oracle数据导入MySQL[转]
使用MySQL Migration Toolkit快速将Oracle数据导入MySQL上来先说点废话本人最近在学习一些数据库方面的知识,之前接触过Oracle和MySQL,最近又很流行MongoDB非 ...
- MYSQL数据库间同步数据
http://blog.csdn.net/swandy45/article/details/6982421 环境要求: Windows 操作系统 需要Mysql 3.23.15以后的版本. 假设数据库 ...
随机推荐
- 玩转 CMS2
玩转 CMS2 上篇研究了样式.请求.evn.mock,感觉对效率的提升没有太明显作用. 比如某个工作需要2天,现在1天可以干完,这就是很大的提升. 提高效率的方法有代码复用.模块化.低代码工具. 目 ...
- Java压缩和解压缩zip文件
介绍 Java提供的java.util.zip包只支持zip和gzip.至于更多格式的压缩可以选择apache的Commons Compress. 参考:https://o7planning.org/ ...
- Java集合框架学习(十) LinkedHashMap详解
LinkedHashMap介绍 1.Key和Value都允许null: 2.维护key的插入顺序: 3.非线程安全: 4.Key重复会覆盖.Value允许重复. 类定义 public class Li ...
- python第一章pta习题总结
chapter 1 一.选择判断部分 1.高级语言程序要被机器执行,只有用解释器来解释执行.(F) 计算机高级语言按程序的执行方式可以分为编译型和解释型两种. 执行方式 跨平台 特点 缺点 代表语言 ...
- AIGC程序员效能提升之道
得益于IT产业近几年的繁荣,老杨所在公司的业务也出奇的兴隆,每天干不完的工作背后,也意味着健康的消耗和体重的不断增加. 曾记否,刚毕业的老杨体重刚刚堪堪破百,同事们经常调侃他说是一阵风就能吹走,经过了 ...
- win32-使用EnumWindows比较两个窗口的Z轴
通过使用EnumWindows()和枚举窗口来手动确定EnumChildWindows()来直接确定哪个窗口在z轴上比另一个窗口高. struct myEnumInfo { HWND hwnd1; H ...
- 数据分析day02
案例 需求:双均线策略制定 1.使用tushare包获取某股票的历史行情数据 2.计算该股票历史数据的5日均线和30日均线 - 什么是均线? - 对于每一个交易日,都可以计算出前N天的移动平均值,然后 ...
- day05---系统的重要文件(3)
1) /usr/local 编辑 安装的软件 第三方软件安装位置 软件安装的三种方法 1.yum安装 自动解决依赖问题 yum [选项参数] 包名 第一个里程碑:我想要安装的软件的名字 或者是 知道命 ...
- Centos8上安装Redis5.X
一.下载Redis 下载地址:wget http://download.redis.io/releases/redis-5.0.7.tar.gz 解压:tar -xzvf redis-5.0.7.ta ...
- SpringCloud组件:Feign之日志输出
目录 Feign之日志输出 Feign日志输出说明 前期准备 构建项目 tairan-spring-cloud-feign-logger配置 源码位置 Feign之日志输出 在我们日常开发过程中,经常 ...