CPU推理|使用英特尔 Sapphire Rapids 加速 PyTorch Transformers
在 最近的一篇文章 中,我们介绍了代号为 Sapphire Rapids 的第四代英特尔至强 CPU 及其新的先进矩阵扩展 (AMX) 指令集。通过使用 Amazon EC2 上的 Sapphire Rapids 服务器集群并结合相应的英特尔优化库,如 英特尔 PyTorch 扩展 (IPEX),我们展示了如何使用 CPU 进行高效的分布式大规模训练,与上一代至强 (Ice Lake) 相比,Sapphire Rapids 实现了 8 倍的加速,取得了近线性的扩展比。
本文我们将重点关注推理。使用基于 PyTorch 的 Hugging Face transformers 模型,我们首先在 Ice Lake 服务器上分别测量它们在长、短两种文本序列上的性能。然后,我们在 Sapphire Rapids 服务器和最新版本的 Hugging Face Optimum Intel 上执行相同的测试,并比较两代 CPU 的性能。这里,Optimum Intel 是一个专用于英特尔平台的硬件加速开源库。
让我们开始吧!
为什么你应该考虑使用 CPU 推理
在决定使用 CPU 还是 GPU 进行深度学习推理时需要考虑多个因素。最重要的当然是模型的大小。一般来说,较大的模型能更多地受益于 GPU 提供的强大算力,而较小的模型可以在 CPU 上高效运行。
另一个需要考虑的因素是模型和推理任务本身的并行度。GPU 为大规模并行处理而设计,因此它们可能对那些可以高度并行化的任务更高效。而另一方面,如果模型或推理任务并没有特别高的并行度,CPU 可能是更有效的选择。
成本也是一个需要考虑的重要因素。GPU 可能很昂贵,而使用 CPU 可能是一种性价比更高的选择,尤其是在业务应用并不需要极低延迟的情况下。此外,如果你需要能够轻松扩缩推理实例的数量,或者如果你需要能够在各种平台上进行推理,使用 CPU 可能是更灵活的选择。
现在,让我们开始配置我们的测试服务器。
配置我们的测试服务器
和上一篇文章一样,我们将使用 Amazon EC2 实例:
- 一个基于 Ice Lake 架构
c6i.16xlarge实例, - 一个基于 Sapphire Rapids 架构的
r7iz.16xlarge-metal实例。你可以在 AWS 网站上获取有关新 r7iz 系列的更多信息。
两个实例都有 32 个物理核 (因此有 64 个 vCPU)。我们将用相同的方式来设置它们:
- Ubuntu 22.04 和 Linux 5.15.0 (
ami-0574da719dca65348), - PyTorch 1.13 与 IPEX (Intel Extension for PyTorch) 1.13,
- Transformers 4.25.1。
唯一的区别是在 r7iz 实例上我们多装一个 Optimum Intel 库。
以下是设置步骤。像往常一样,我们建议使用虚拟环境来保证环境纯净。
sudo apt-get update
# 安装 libtcmalloc,获取更好性能
sudo apt install libgoogle-perftools-dev -y
export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so"
sudo apt-get install python3-pip -y
pip install pip --upgrade
export PATH=/home/ubuntu/.local/bin:$PATH
pip install virtualenv
virtualenv inference_env
source inference_env/bin/activate
pip3 install torch==1.13.0 -f https://download.pytorch.org/whl/cpu
pip3 install intel_extension_for_pytorch==1.13.0 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install transformers
# 仅需在 r7iz 实例上安装
pip3 install optimum [intel]
在两个实例上完成上述步骤后,我们就可以开始运行测试了。
对流行的 NLP 模型进行基准测试
在这个例子中,我们将在文本分类任务上对几个 NLP 模型进行基准测试: distilbert-base-uncased, bert-base-uncased 和 roberta-base。你可以在 Github 上找到 完整脚本。当然,你也可以用你自己的模型随意尝试!
models = ["distilbert-base-uncased", "bert-base-uncased", "roberta-base"]
我们使用序列长度分别为 16 和 128 的两种句子来测试,同时我们也将在这两种句子上分别测量单句推理和批量推理的平均预测延迟和 p99 预测延迟。该测试方案模拟了真实场景,因此可以较好地近似在真实场景中的预期加速比。
sentence_short = "This is a really nice pair of shoes, I am completely satisfied with my purchase"
sentence_short_array = [sentence_short] * 8
sentence_long = "These Adidas Lite Racer shoes hit a nice sweet spot for comfort shoes. Despite being a little snug in the toe box, these are very comfortable to wear and provide nice support while wearing. I would stop short of saying they are good running shoes or cross-trainers because they simply lack the ankle and arch support most would desire in those type of shoes and the treads wear fairly quickly, but they are definitely comfortable. I actually walked around Disney World all day in these without issue if that is any reference. Bottom line, I use these as the shoes they are best; versatile, inexpensive, and comfortable, without expecting the performance of a high-end athletic sneaker or expecting the comfort of my favorite pair of slippers."
sentence_long_array = [sentence_long] * 8
基准测试功能非常简单。在几次预热迭代后,我们使用 pipeline API 运行 1000 次预测,把预测时间存下来,并计算它们的均值和 p99 值。
import time
import numpy as np
def benchmark (pipeline, data, iterations=1000):
# 预热 100 次
for i in range (100):
result = pipeline (data)
times = []
for i in range (iterations):
tick = time.time ()
result = pipeline (data)
tock = time.time ()
times.append (tock - tick)
return "{:.2f}".format (np.mean (times) * 1000), "{:.2f}".format (
np.percentile (times, 99) * 1000
)
在 c6i (Ice Lake) 实例上,我们只使用普通的 Transformers pipeline。
from transformers import pipeline
for model in models:
print (f"Benchmarking {model}")
pipe = pipeline ("sentiment-analysis", model=model)
result = benchmark (pipe, sentence_short)
print (f"Transformers pipeline, short sentence: {result}")
result = benchmark (pipe, sentence_long)
print (f"Transformers pipeline, long sentence: {result}")
result = benchmark (pipe, sentence_short_array)
print (f"Transformers pipeline, short sentence array: {result}")
result = benchmark (pipe, sentence_long_array)
print (f"Transformers pipeline, long sentence array: {result}")
在 r7iz (Sapphire Rapids) 实例上,我们同时使用普通 pipeline 和 Optimum pipeline。在 Optimum pipeline 中,我们启用 bfloat16 模式以利用到 AMX 指令,并将 jit 设置为 True 以使用即时编译进一步优化模型。
import torch
from optimum.intel import inference_mode
with inference_mode (pipe, dtype=torch.bfloat16, jit=True) as opt_pipe:
result = benchmark (opt_pipe, sentence_short)
print (f"Optimum pipeline, short sentence: {result}")
result = benchmark (opt_pipe, sentence_long)
print (f"Optimum pipeline, long sentence: {result}")
result = benchmark (opt_pipe, sentence_short_array)
print (f"Optimum pipeline, short sentence array: {result}")
result = benchmark (opt_pipe, sentence_long_array)
print (f"Optimum pipeline, long sentence array: {result}")
为简洁起见,我们先看下 distilbert-base-uncased 的 p99 结果。你可以在文章末尾找到所有测例的完整结果。
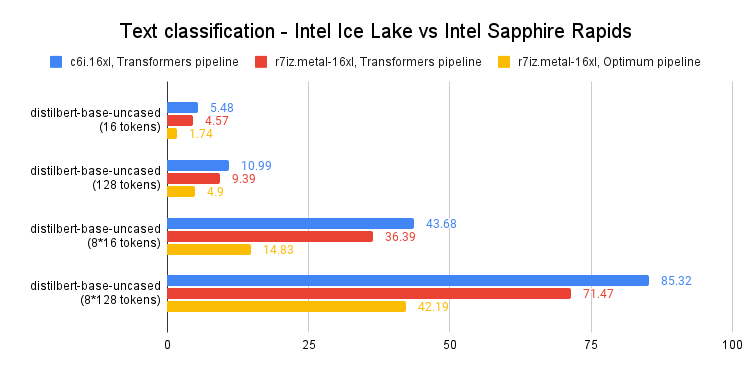
如上图所示,与上一代至强 CPU 相比,Sapphire Rapids 上单个句子的预测延迟加速了 60-65%。也就是说,由于结合了英特尔 Sapphire Rapids 平台以及 Hugging Face Optimum 的优化,你只需对代码进行很少改动就可将预测速度提高 3 倍。
这让我们即使在长文本序列上也可以达到 个位数的预测延迟。在 Sapphire Rapids 之前,这样的性能只有通过 GPU 才能实现。
结论
第四代英特尔至强 CPU 提供了出色的推理性能,尤其是在与 Hugging Face Optimum 结合使用时。这是深度学习在更易得和更具成本效益的道路上的又一个进步,我们期待与英特尔的朋友们在这条道路上继续合作。
以下是一些可帮助你入门的其他资源:
如果你有任何问题或反馈,我们很乐意在 Hugging Face 论坛 上与你交流。
感谢阅读!
附录: 完整结果
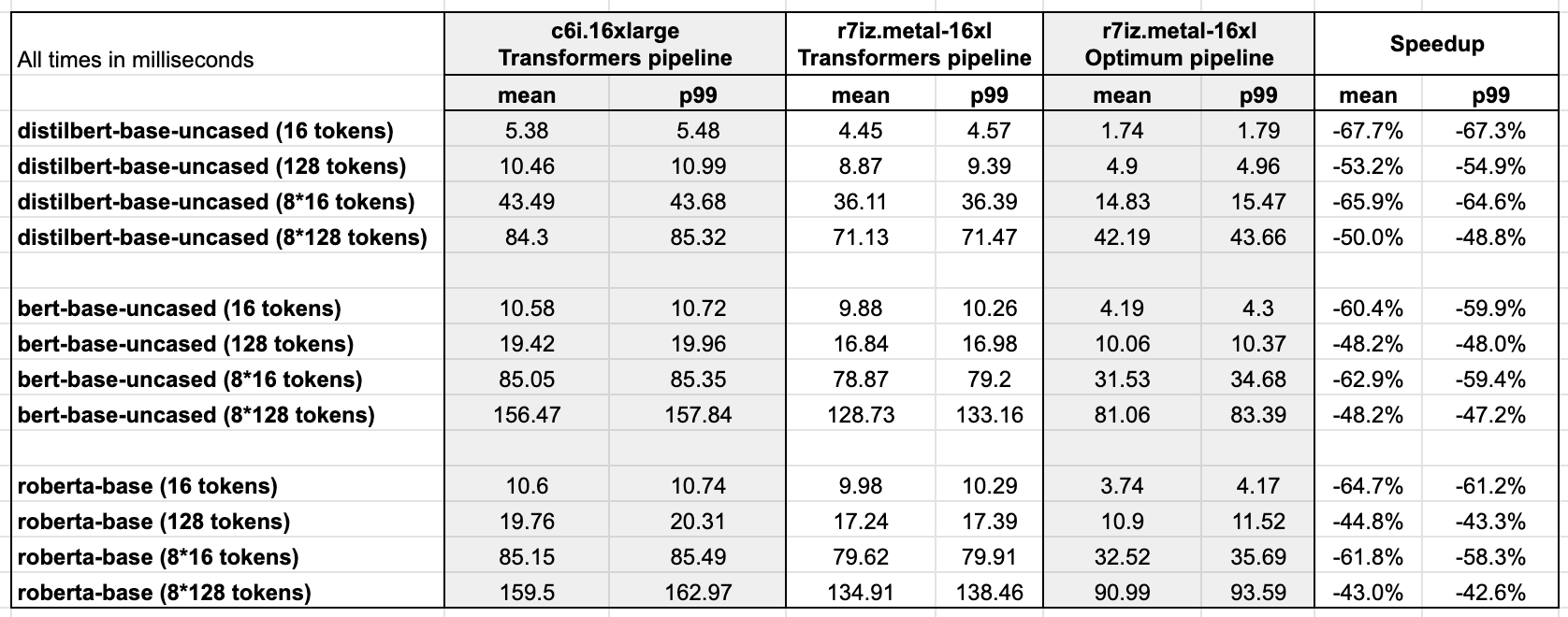
基准测试软件环境:
- Ubuntu 22.04 with libtcmalloc
- Linux 5.15.0 patched for Intel AMX support
- PyTorch 1.13 with Intel Extension for PyTorch
- Transformers 4.25.1
- Optimum 1.6.1
- Optimum Intel 1.7.0.dev0
英文原文: https://hf.co/blog/intel-sapphire-rapids-inference
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校、排版: zhongdongy (阿东)
CPU推理|使用英特尔 Sapphire Rapids 加速 PyTorch Transformers的更多相关文章
- 使用英特尔 Sapphire Rapids 加速 PyTorch Transformers 模型
大约一年以前,我们 展示 了如何在第三代 英特尔至强可扩展 CPU (即 Ice Lake) 集群上分布式训练 Hugging Face transformers 模型.最近,英特尔发布了代号为 Sa ...
- 英特尔与 Facebook 合作采用第三代英特尔® 至强® 可扩展处理器和支持 BFloat16 加速的英特尔® 深度学习加速技术,提高 PyTorch 性能
英特尔与 Facebook 曾联手合作,在多卡训练工作负载中验证了 BFloat16 (BF16) 的优势:在不修改训练超参数的情况下,BFloat16 与单精度 32 位浮点数 (FP32) 得到了 ...
- 在英特尔 CPU 上加速 Stable Diffusion 推理
前一段时间,我们向大家介绍了最新一代的 英特尔至强 CPU (代号 Sapphire Rapids),包括其用于加速深度学习的新硬件特性,以及如何使用它们来加速自然语言 transformer 模型的 ...
- 面向英特尔® x86 平台的 Unity* 优化指南: 第 1 部分
原文地址 目录 工具 Unity 分析器 GPA 系统分析器 GPA 帧分析器 如要充分发挥 x86 平台的作用,您可以在项目中进行多种性能优化,以最大限度地提升性能. 在本指南中,我们将展示 Uni ...
- [转帖]英特尔的 ME 或侵犯 Minix3 的自由软件许可证
英特尔的 ME 或侵犯 Minix3 的自由软件许可证 [日期:2017-12-11] 来源:Linux公社 作者:非非然 [字体:大 中 小] https://www.linuxidc.com/L ...
- 英特尔® 图形性能分析器(Intel® GPA)
英特尔图形性能分析器概述 英特尔 GPA 是一套软件工具,它能提供平台级游戏性能分析功能,优化应用性能. 英特尔 GPA 包含以下组件: 英特尔 GPA 监控器 - 将英特尔 GPA 连接至应用(处于 ...
- 英特尔® 至强® 平台集成 AI 加速构建数据中心智慧网络
英特尔 至强 平台集成 AI 加速构建数据中心智慧网络 SNA 通过 AI 方法来实时感知网络状态,基于网络数据分析来实现自动化部署和风险预测,从而让企业网络能更智能.更高效地为最终用户业务提供支撑. ...
- 国产CPU走到十字路口:谁来取代英特尔芯片?(少写了一个OpenPower)
国内的几支CPU研发力量各自选择的指令体系都有自己的优点和问题,选择其中的哪一支都会有对应的成本和风险.最终谁能担大任,且拭目以待. 文 | 瞭望智库特约科技观察员 王强 用上内置国产CPU的个人电脑 ...
- 【硬件】- 英特尔CPU命名中的产品线后缀
产品线后缀是CPU命名体系里最复杂最难懂的,在英特尔冗长的产品线中,CPU的后缀也是千变万化.不带后缀的CPU一般就是最普通的桌面级处理器,不管是性能还是价格都比较中庸,比如当前性价比较高的Core ...
- 【硬件】- 英特尔CPU命名规则
前言 一款Intel CPU的命名,一般由5个部分组成:品牌,品牌标识符,Gen标识,SKU数值,产品线后缀. 以下图为例: 品牌 英特尔旗下处理器有许多子品牌,包括我们熟悉的凌动(ATOM).赛扬( ...
随机推荐
- 使用ResponseSelector实现校园招聘FAQ机器人
本文主要介绍使用ResponseSelector实现校园招聘FAQ机器人,回答面试流程和面试结果查询的FAQ问题.FAQ机器人功能分为业务无关的功能和业务相关的功能2类. 一.data/nlu.y ...
- 快速排序(quick_sort)
快速排序大体分为三个步骤: 1.确定分界点 q[(l+r) >> 1] 或者 q[(l+r+1) >> 1] ,两者得看情况而定,不能用 q[l] 或者 q[r] 了 因为会超 ...
- 手撕Vuex-安装模块方法
前言 经过上一篇文章的介绍,我们实现了将模块安装到 store 中,那么本章我们就来介绍一下怎么安装模块当中的方法也就是 actions.mutations.getters. 所以本次文章的目标就是将 ...
- DiscuzQ官方最新v3.0.220211源码编译搭建教程和官方部署教程,适合二开(已本地编译通过,无任何错误)
经过长达半个月的研究! 完成这篇DiscuzQ官方最新版本v3.0.220211的源码编译和官方部署教程.适合喜欢二次开发的小伙伴们,已经通过本地编译测试,保证没有任何错误. 具体教程在我搭建的dzq ...
- java笔记——面向对象
1.概述:面向对象是基于面向过程的编程思想 举例:把大象装进冰箱 2.开发:不断的创建对象,使用对象,指挥对象做事情 3.面向对象特征:封装 , 继承 , 多态 4.类和对象的关系: 类是一组相关的属 ...
- PageHelper插件注意事项
PageHelper插件注意事项 使用PageHelper.startPage后要紧跟查询语句 下面的代码就有可能出问题: PageHelper.startPage(10, 10); if(param ...
- Typora的安装与使用教程
一.安装 1.下载 下载地址:Typora 官方中文站 二.安装 1.无脑下一步即可. 三.使用教程 1.Typora系统设置 一般导出使用PDF文件比较好,性价比比较高. 2.其他设置 以下所有设置 ...
- Grafana系列-Loki-基于日志实现告警
系列文章 Loki 系列文章 前言 实际应用中除了基于 Metrics 告警, 往往还有基于日志的告警需求, 可以作为基于 Metrics 告警之外的一个补充. 典型如基于 NGINX 日志的错误率告 ...
- 无序对的GCD
求\(\sum_{i = 1}^n \sum_{j = i+1}^n GCD(a_i, a_j)\) \(N\)为上确界,\(n\)为\(a\)数组元素个数,\(D\)为约数个数. 方法一 \(1.\ ...
- 单元测试框架pytest
1.什么是pytest pytest是一个非常成熟的全功能的Python测试框架,主要有以下特点: 简单灵活,容易上手,文档丰富 支持参数化,可以细粒度地控制要测试的测试用例 能够支持简单的单元测试和 ...