【转帖】mysql一个索引块有多少指针_深刻理解MySQL系列之索引
索引
查找一条数据的过程
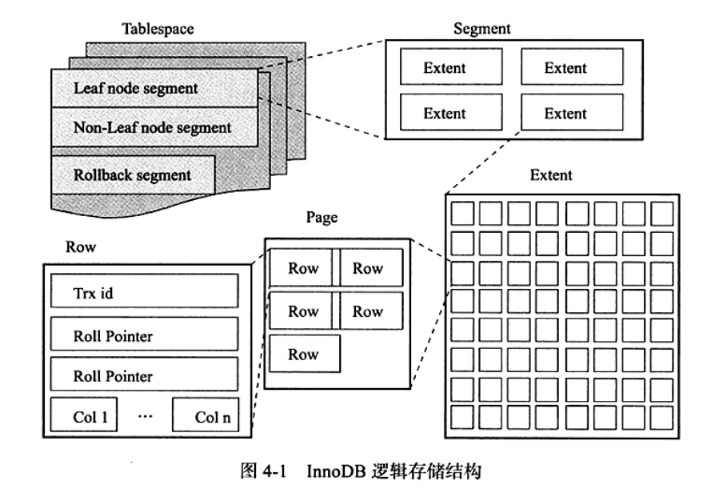
先看下InnoDB的逻辑存储结构:node
表空间:能够看作是InnoDB存储引擎逻辑结构的最高层,全部的数据都存放在表空间中。默认有个共享表空间ibdata1。若是启用innodb_file_per_table参数,须要注意每张表的表空间内存放的只是数据、索引和插入缓冲Bitmap页,其余类的数据,如回滚信息、插入缓冲索引页、系统事务信息、二次写缓冲等仍是存放在原来共享表空间中。数据库
段:
表空间是由各个段组成,常见的段有数据段、索引段、回滚段等。数据段即为B+树叶子节点(Leaf node segment),索引段即为B+树非叶子节点(Non-leaf node segment)
区性能
区:是由连续页组成的空间,在任何状况下每一个区大小都为1MB。默认状况下,存储引擎页的大小为16KB,即一个区中一共有连续64个连续的页。而为保证页的连续性,InnoDB存储引擎一次从磁盘申请4-5个区。优化
页:
页(也能够称块),是InnoDB磁盘管理的最小单位。默认每一个页大小16KB。1.2x版本后也能够经过参数innodb_page_size设置为4k、8k、16k3d
如查一条数据:select * from user where id=5;指针
这里id是主键,咱们经过这棵B+树来查找,首先会去找到根页,每张表的根页位置在表空间文件中是固定的;找到根页后经过二分查找法,定位到id=5的数据应该在指针P5指向的页中,那么进一步去page number=5的页中查找,一样经过二分查询法便可找到id=5的记录:blog
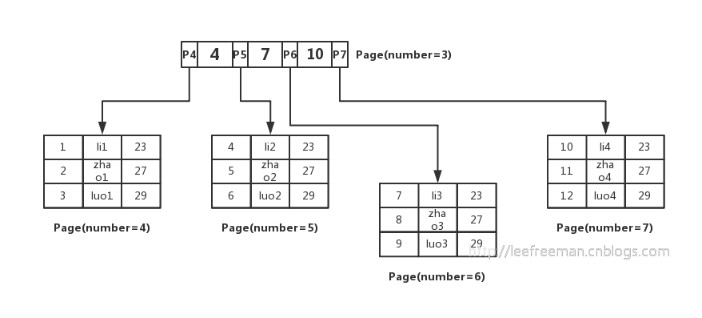
计算一棵B+树能够存放多少行数据
也能够经过命令查看InnoDB每页默认16KB:排序
show variables like 'innodb_page_size';索引
先计算非叶子节点, 假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节事务
而一个页中能存放多少这样的单元,其实就表明有多少指针,即16384/14=1170。
那么能够算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。
根据一样的原理咱们能够算出一个高度为3的B+树能够存放:1170117016=21902400条这样的记录。
因此在InnoDB中B+树高度通常为1-3层,它就能知足千万级的数据存储。
索引一些概念
聚簇索引(clustered index): 就是将索引和数据放到一块儿,找到索引也就找到了数据;以下图叶子节点存放一行全部数据。
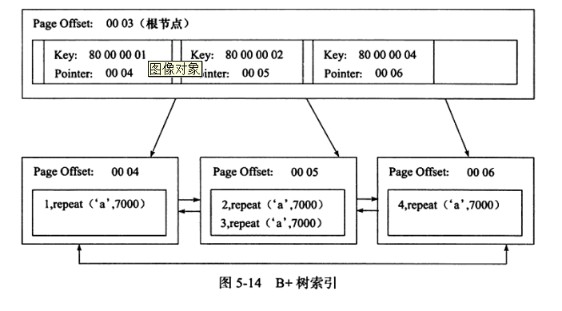
辅助索引(Secondary Index或非聚簇索引): 就是将数据和索引分开,查找时须要先查找到索引,而后经过索引回表找到相应的数据。
回表:先经过数据库索引扫描出数据所在的行,再经过行主键id取出索引中未提供的数据,即基于非主键索引的查询须要多扫描一棵索引树。
以下图,辅助索引查找后,会再回表到聚簇索引,最后找到数据。
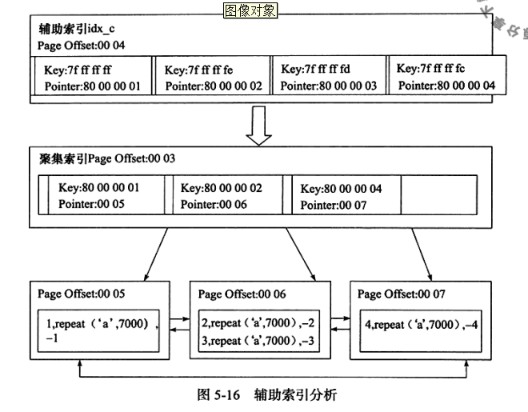
InnoDB有且只有一个聚簇索引,而MyISAM中都是非聚簇索引。
联合索引:指对表上多个列进行索引。
联合索引的最左前缀匹配原则: 对多个字段同时创建的组合索引(有顺序,ABC,ACB是彻底不一样的两种联合索引) 以联合索引(a,b,c)为例,创建这样的索引至关于创建了索引a、ab、abc三个索引。另外组合索引实际仍是一个索引,并不是真的建立了多个索引,只是产生的效果等价于产生多个索引。
覆盖索引: 即从辅助索引中就能够获得查询的记录,而不须要查询聚簇索引中的记录。
使用覆盖好处:
辅助索引不包含整行记录的全部信息,故其大小要远小于聚簇索引,减小大量IO操做。
对某些统计(如count(id))并不会经过查询聚簇索引来进行统计,减小IO操做
惟一索引:以惟一列生成的索引,该列不容许有重复值,但容许有空值(NULL)
索引下推:MySQL 5.6引入了索引下推优化,能够在索引遍历过程当中,对索引中包含的字段先作判断,过滤掉不符合条件的记录,减小回表字数。
为何选B+树,而不是B树
B树无论叶子节点仍是非叶子节点,都会保存数据,这样致使在非叶子节点中能保存的指针数量变少
指针少的状况下要保存大量数据,只能增长树的高度,致使IO操做变多,查询性能变低;
为何InnoDB只有一个聚簇索引,而不将全部索引都使用聚簇索引?
由于聚簇索引是将索引和数据都存放在叶子节点中,若是全部的索引都用聚簇索引,则每个索引都将保存一份数据,会形成数据的冗余,在数据量很大的状况下,这种数据冗余是很消耗资源的。
什么状况下会发生明明建立了索引,可是执行的时候并无经过索引呢?
查询优化器。
一条SQL语句的查询,能够有不一样的执行方案,至于最终选择哪一种方案,须要经过优化器进行选择,选择执行成本最低的方案。
优化过程大体以下:
一、根据搜索条件,找出全部可能使用的索引
二、计算全表扫描的代价
三、计算使用不一样索引执行查询的代价
四、对比各类执行方案的代价,找出成本最低的那一个 。
索引的优缺点
索引的优势以下:
一、惟一索引能够保证每一行数据的惟一性
二、提升查询速度
三、加速表与表的链接
四、显著的减小查询中分组和排序的时间
五、经过使用索引,能够在查询的过程当中,使用优化隐藏器,提升系统的性能。
索引的缺点以下:
建立索引时,须要对表加锁,在锁表的同时,可能会影响到其余的数据操做
虽然索引大大提升了查询速度,同时却会下降更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。由于更新表时,MySQL 不只要保存数据,还要保存索引文件。
创建索引会占用磁盘空间的索引文件。通常状况这个问题不算严重,但若是你在一个大表上建立了多种组合索引,且伴随大量数据量插入,索引文件大小也会快速膨胀。
若是某个数据列包含许多重复的内容,为它创建索引就没有太大的实际效果。
对于很是小的表,大部分状况下简单的全表扫描更高效。
使用索引时的注意事项
原则:
不该该
一、索引不是越多越好。索引太多,维护索引须要时间跟空间
二、 频繁更新的数据,不宜建索引。
三、数据量小的表不必创建索引。
应该
一、重复率小的列建议生成索引。由于重复数据少,索引树查询更有效率,等价基数越大越好。
二、数据具备惟一性,建议生成惟一性索引。在数据库的层面,保证数据正确性
三、频繁group by、order by的列建议生成索引。能够大幅提升分组和排序效率
四、常常用于查询条件的字段建议生成索引。经过索引查询,速度更快
索引失效的场景
一、模糊搜索:左模糊或全模糊都会致使索引失效,好比'%a'和'%a%'。可是右模糊是能够利用索引的,好比'a%'
二、隐式类型转换:好比select * from t where name = xxx , name是字符串类型,可是没有加引号,因此是由MySQL隐式转换的,因此会让索引失效
三、当语句中带有or的时候:好比select * from t where name=‘sw’ or age=14
四、不符合联合索引的最左前缀匹配:(A,B,C)的联合索引,你只where了C或B或只有B,C
其余注意事项:
索引不会包含有 null 值的列,只要列中包含有 null值都将不会被包含在索引中。
使用短索引。短索引不只能够提升查询速度并且能够节省磁盘空间和 I/O 操做
索引列排序。查询只使用一个索引,所以若是 where 子句中已经使用了索引的话,那么 order by 中的列是不会使用索引的。所以数据库默认排序能够符合要求的状况下不要使用排序操做;尽可能不要包含多个列的排序,若是须要最好给这些列建立复合索引。
不要在列上进行运算,这将致使索引失效而进行全表扫描
不使用 not in 和 <> 操做,这不属于支持的范围查询条件,不会使用索引。
【转帖】mysql一个索引块有多少指针_深刻理解MySQL系列之索引的更多相关文章
- 手把手教你使用FineUI开发一个b/s结构的取送货管理信息系统系列博文索引
近阶段接到一些b/s类型的软件项目,但是团队成员之前大部分没有这方面的开发经验,于是自己选择了一套目前网上比较容易上手的开发框架(FineUI),计划录制一套视频讲座,来讲解如何利用FineUI快速开 ...
- 与众不同 windows phone 8.0 & 8.1 系列文章索引
[源码下载] [与众不同 windows phone 7.5 (sdk 7.1) 系列文章索引] 与众不同 windows phone 8.0 & 8.1 系列文章索引 作者:webabcd ...
- 对C语言中指针的入门理解
通过一个例子引出对指针的概念理解 1,例子 #include<stdio.h> int main(void) { ; //小张的身高 ; //小李的身高 ; //小王的身高 int *xi ...
- 如果一个文件块有130M,请问有多少个mapper
如果一个文件块有130M,请问有多少个mapper 130M的文件将被分成2个mapper. 原因:根据FileInputFormat类 有一个成员变量 private static final do ...
- Mysql高手系列 - 第22篇:深入理解mysql索引原理,连载中
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 欢迎大家加我微信itsoku一起交流java.算法.数据库相关技术. 这是Mysql系列第22篇. 背景 使用mys ...
- 深入理解MySQL系列之索引
索引 查找一条数据的过程 先看下InnoDB的逻辑存储结构: 表空间:可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中.默认有个共享表空间ibdata1.如果启用innodb ...
- MySQL 中索引是如何实现的,有哪些类型的索引,如何进行优化索引
MySQL 中的索引 前言 索引的实现 哈希索引 全文索引 B+ 树索引 索引的分类 聚簇索引(clustered index) 非聚簇索引(non-clustered index) 联合索引 覆盖索 ...
- (转)理解MySQL——索引与优化
参考资料:http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html ———————————— 全文: 写在前面:索引对查询的速度有着 ...
- 理解MySQL——索引与优化
转自:理解MySQL——索引与优化 写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存 ...
- 1020理解MySQL——索引与优化
转自http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html 写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性 ...
随机推荐
- 文心一言 VS 讯飞星火 VS chatgpt (34)-- 算法导论5.3 1题
一.Marceau 教授不同意引理 5.5 证明中使用的循环不变式.他对第1次送代之前循环不变式是否为真提出质疑.他的理由是,我们可以很容易宣称一个空数组不包含0排列.因此一个空的子数组包含一个0排列 ...
- 一文为你详解Unique SQL原理和应用
摘要:以一定的算法结合解析树中的各结点,计算出来一个整数值,用来唯一标识这一类SQL,这个整数值被称为Unique SQL ID,Unique SQL ID相同的SQL语句属于同一个"Uni ...
- 云图说 | Workflow:流水线工具,助您高效完成AI开发
摘要:Workflow是将ML Ops(机器学习和DevOps的组合实践)应用于ModelArts平台,可以让您更高效的完成AI开发. 本文分享自华为云社区<云图说 | 第263期 Workfl ...
- 云图说|云数据库RDS跨区域备份
摘要:云数据库RDS支持将备份文件存放到另一个区域存储,某一区域的实例故障后,可以在异地区域使用备份文件在异地恢复到新的RDS实例,用来恢复业务. 本文分享自华为云社区<云图说_云数据库RDS- ...
- MultipartFile与File的一些事
摘要:某段时间碰到了中转文件的需求,需要使用HttpClient中转一下文件,在实现这个需求的过程中就用得到了MultipartFile与File. 本文分享自华为云社区<MultipartFi ...
- APP加固原理与作用
APP加固原理与作用 引言 在移动应用开发中,APP加固是一种保护应用代码逻辑的重要措施.通过对应用文件进行隐藏.混淆和加密等操作,可以有效提高软件的逆向成本,降低被破解的几率.本文将介绍APP加固的 ...
- 火山引擎ByteHouse:ClickHouse如何保证海量数据一致性
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 背景 ClickHouse是一个开源的OLAP引擎,不仅被全球开发者广泛使用,在字节各个应用场景中也可以看到它的身 ...
- SE54视图簇
一.创建关联表 头表 行表 设置行表的外键 创建两张表的表维护生成器,此处不再展开 二.SE54视图簇 激活上述 三.创建事务代码维护 四.效果展示 定期更文,欢迎关注 TRANSLATE with ...
- LLVM 参考链接
https://www.llvm.org/ LLVM Essentials(Paperback) LLVM 编译器 https://www.cs.cmu.edu/afs/cs.cmu.edu/acad ...
- Windows 环境下安装与配置 Node.js
一.下载Node.js安装包 下载地址:http://nodejs.cn/download/ 本教程以msi安装包为例 点击Windows 安装包下载 二.安装Node.js 1.打开安装包 欢迎页: ...