EasyNLP带你玩转CLIP图文检索
简介: 本文简要介绍CLIP的技术解读,以及如何在EasyNLP框架中玩转CLIP模型。
作者:熊兮、章捷、岑鸣、临在
导读
随着自媒体的不断发展,多种模态数据例如图像、文本、语音、视频等不断增长,创造了互联网上丰富多彩的世界。为了准确建模用户的多模态内容,跨模态检索是跨模态理解的重要任务,采用一种模态的数据作为数据,检索另一种模态的数据。其中,图文检索是跨模态检索的一种主流任务,广泛应用于各种网络应用中,其难点在于跨模态的表示鸿沟(Representation Gap)。具体来说,文本和图像的数据处于不同的向量空间,无法直接去度量他们的相似性。OpenAI提出了CLIP(Contrastive Language-Image Pre-training)模型,在大规模图文数据集上进行了对比学习训练,在多个数据集上的准确度表明,CLIP优于各种基于ImageNet的模型,也具有良好的零样本学习(Zero-shot Learning)能力。
EasyNLP是阿里云机器学习PAI 团队基于 PyTorch 开发的易用且丰富的中文NLP算法框架,支持常用的中文预训练模型和大模型落地技术,并且提供了从训练到部署的一站式 NLP 开发体验。EasyNLP 提供了简洁的接口供用户开发 NLP 模型,包括NLP应用 AppZoo 和预训练 ModelZoo,同时提供技术帮助用户高效的落地超大预训练模型到业务。由于跨模态理解需求的不断增加,EasyNLP也将支持各种跨模态模型,特别是中文领域的跨模态模型,推向开源社区,希望能够服务更多的 NLP 和多模态算法开发者和研究者,也希望和社区一起推动 NLP /多模态技术的发展和模型落地。
本文简要介绍CLIP的技术解读,以及如何在EasyNLP框架中玩转CLIP模型。
CLIP模型详解
CLIP的模型结构相对比较简单,体现了“大道至简”的设计原则,其模型框架图如下图所示:
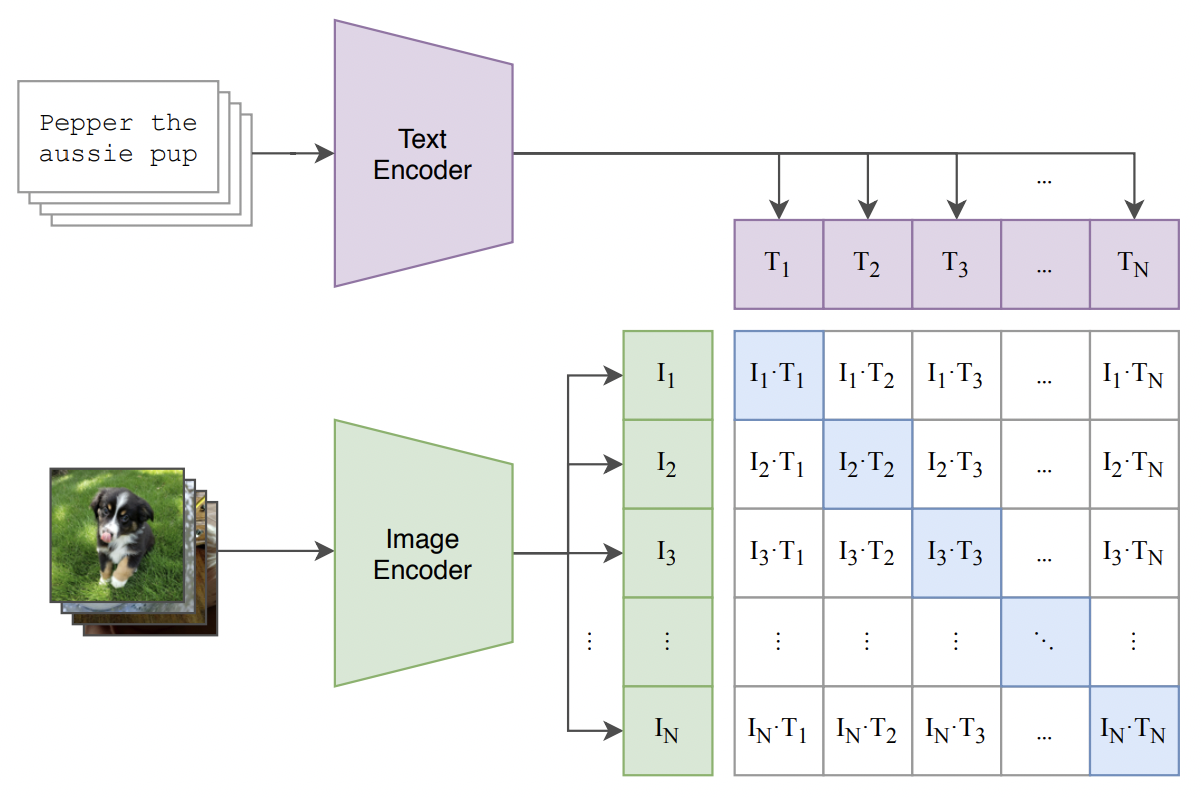
为了建立图像和文本的关联性,CLIP首先分别构建了图像和文本的Encoder,分别对图像和文本进行特征抽取。对于图像而言,CLIP使用的Backbone可以是经典的ResNet系列模型,也可以是更先进的Transfomer类模型,例如VIT等;对于文本,CLIP一般使用BERT类模型进行特征抽取,也包括RoBERTa等。在特征抽取之后,CLIP分别对提取的向量进行Normalization,从而可以直接进行内积相似度计算。在模型Loss Function层面,由于图像和文本向量都进行了Normalization,我们直接使用相乘来计算余弦距离,使得同一图文对的结果趋近于1,不同图文对的结果趋近于0;并且使用对比学习损失InfoNCE进行损失计算。
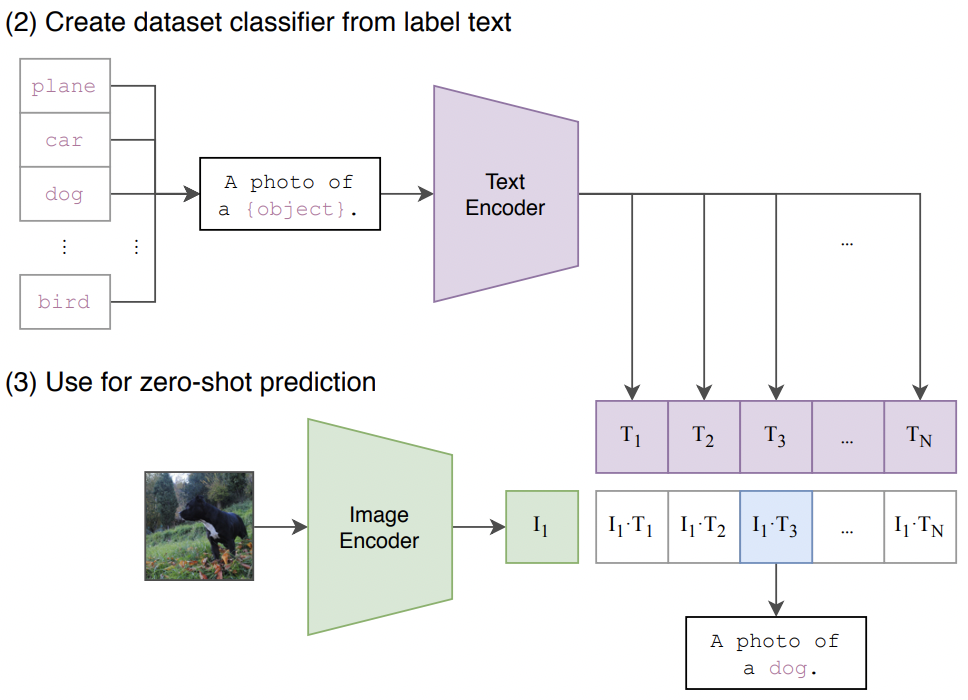
当模型预训练结束后,我们可以直接使用CLIP进行图文的检索,因为CLIP已经将图文的表示映射到同一个向量空间。CLIP的另一个优势在于可以进行Zero-shot Classification。如下图所示,我们设计输入文本“A photo of a {object}.”,并且使用目标图像作为输出。如果文本“A photo of a dog.”于当前图像最匹配(余弦相似度最高),我们可以说明,当前图像的物体是“dog”。由此可见,预训练后的CLIP模型可以直接用于图像分类,而不需要额外的训练。
CLIP模型的训练过程也可以直接参考原作者给出的伪代码实现:

EasyNLP中CLIP模型的实现
在EasyNLP框架中,我们在模型层构建了CLIP模型的Backbone,核心代码如下所示:
self.text_model = CLIPTextTransformer(text_config)
self.vision_model = CLIPVisionTransformer(vision_config) self.visual_projection = nn.Linear(self.vision_embed_dim, self.projection_dim, bias=False)
self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim, bias=False
其中,CLIPTextTransformer和CLIPVisionTransformer分别是基于BERT和VIT的特征提取器。前向传播的过程也比较简洁:
vision_outputs = self.vision_model(...)
text_outputs = self.text_model(...) image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
image_embeds = image_embeds / image_embeds.norm(dim=-1, keepdim=True) text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
text_embeds = text_embeds / text_embeds.norm(dim=-1, keepdim=True) logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
loss = clip_loss(logits_per_text)
此外,由于CLIP模型本身具备文本和图像的编码器,我们直接调用他们的前向推理函数就可以实现特征的提取。对于文本我们有:
text_outputs = self.text_model(...)
pooled_output = text_outputs[1]
text_features = self.text_projection(pooled_output)
对图像的操作也与文本类似:
vision_outputs = self.vision_model(...)
pooled_output = vision_outputs[1]
image_features = self.visual_projection(pooled_output)
此外,我们在多个公开数据集上验证了EasyNLP框架中CLIP模型在各种任务上的精度。以零样本学习为例,我们使用EasyNLP加载了开源的openai/clip-vit-large-patch14模型,对比了Top-1精度和CLIP官方论文的结果,如下所示:
|
数据集 |
Top-1 Accuracy (复现结果) |
CLIP 论文汇报结果 |
|
Food101 |
90.9 |
92.9 |
|
CIFAR100 |
78.6 |
77.9 |
|
EuroSAT |
60.1 |
59.9 |
|
Oxford Pets |
93.0 |
93.5 |
|
Fllickr30k-TR |
85.3 |
88.0 |
|
Fllickr30k-IR |
65.0 |
68.7 |
我们的实验也说明,如果采用特定数据集的数据对CLIP进行进一步Fine-tune,CLIP能取得更好的效果。以Fllickr30k数据集为例,CLIP模型在零样本学习和Fine-tune对比结果如下:
|
img2txt (r1/r5/r10) |
img2txt mean |
txt2img (r1/r5/r10) |
txt2img mean |
|
|
CLIP Fine-tune |
91.0/99.0/99.7 |
95.57 |
76.38/94.06/97.28 |
89.24 |
|
CLIP Zero-shot |
85.3/97.40/99.2 |
94.0 |
65.02/87.2/92.0 |
81.41 |
我们也在中文数据集上进行了预训练,并且评测了模型在COCO-CN和Fllickr30k-CN数据集上的效果。模型的设置与WukongViT对齐(详见参考文献),进行了复现,结果如下所示:
|
数据集 |
模型 |
img2txt mean |
txt2img mean |
|
COCO-CN |
WukongViT |
96.4 |
89.8 |
|
CLIP |
96.1 |
88.4 |
|
|
Fllickr30k-CN |
WukongViT |
85.9 |
87.8 |
|
CLIP |
86.0 |
86.1 |
由上述结果可见,EasyNLP框架训练的CLIP模型在下游任务的Finetune结果与WukongViT基本对齐。结果少量差异性的原因在于:1. MindSpore与PyTorch的内部实现差异性(WukongViT作者采用MindSpore实现)以及2. 超参数和随机种子的选择。
为了方便用户的使用,EasyNLP进一步提供了AppZoo层面的接口,使得用户可以在不实现任何代码的情况下调用CLIP模型,这一部分内容在下一节介绍。
CLIP模型使用教程
以下简要介绍在EasyNLP框架使用CLIP模型。由于用户数据一般于CLIP预训练数据在分布上存在差距。我们提供CLIP模型的训练和向量提取功能
安装EasyNLP
用户可以直接参考链接的说明安装EasyNLP算法框架。
数据准备
首先准备训练数据与验证数据,为tsv文件。这一文件包含以制表符\t分隔的两列,第一列为文本,第二列为图片的base64编码。用于提取向量接入向量检索系统的输入文件为单列,仅包含文本或图片的base64编码。
为了方便开发者,我们也提供了转换图片到base64编码的示例代码:
import base64
from io import BytesIO
from PIL import Image img = Image.open(fn)
img_buffer = BytesIO()
img.save(img_buffer, format=img.format)
byte_data = img_buffer.getvalue()
base64_str = base64.b64encode(byte_data) # bytes
下列文件已经完成预处理,可用于测试:
# train
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/CLIP/MUGE_MR_train_base64_part.tsv # valid
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/CLIP/MUGE_MR_valid_base64_part.tsv # text
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/CLIP/MUGE_MR_test_base64_part_text.tsv # image
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/CLIP/MUGE_MR_test_base64_part_image.tsv
模型训练和评测
我们采用以下命令对CLIP模型进行fine-tune:
easynlp \
--mode train \
--worker_gpu=1 \
--tables=./MUGE_MR_train_base64_part.tsv,./MUGE_MR_valid_base64_part.tsv \
--input_schema=text:str:1,image:str:1 \
--first_sequence=text \
--second_sequence=image \
--checkpoint_dir=./clip_model/ \
--learning_rate=1e-4 \
--epoch_num=1 \
--random_seed=42 \
--logging_steps=100 \
--save_checkpoint_steps 200 \
--sequence_length=32 \
--micro_batch_size=32 \
--app_name=clip \
--save_all_checkpoints \
--user_defined_parameters='pretrain_model_name_or_path=clip_chinese_roberta_large_with_vit_large fix_vision=True mode=finetune'
训练完成后模型被保存到./clip_model/。训练结束后,我们可以对模型进行评估:
easynlp \
--mode evaluate \
--worker_gpu=1 \
--tables=./MUGE_MR_valid_base64_part.tsv \
--input_schema=text:str:1,image:str:1 \
--first_sequence=text \
--second_sequence=image \
--checkpoint_dir=./clip_model/ \
--random_seed=42 \
--logging_steps=100 \
--save_checkpoint_steps=500 \
--sequence_length=32 \
--micro_batch_size=32 \
--app_name=clip
文本或图片特征提取
模型训练完毕后,我们可以将其用于文本或图片的特征提取,示例如下:
- 提取文本特征
easynlp \
--mode predict \
--worker_gpu=1 \
--tables=./MUGE_MR_test_base64_part_text.tsv \
--input_schema=text:str:1 \
--output_schema=text_feat \
--outputs=./text_feat.tsv \
--first_sequence=text \
--checkpoint_dir=./clip_model/ \
--random_seed=42 \
--logging_steps=100 \
--save_checkpoint_steps=500 \
--sequence_length=32 \
--micro_batch_size=2 \
--app_name=clip
- 提取图片特征
easynlp \
--mode predict \
--worker_gpu=1 \
--tables=./MUGE_MR_test_base64_part_image.tsv \
--input_schema=image:str:1 \
--output_schema=image_feat \
--outputs=./image_feat.tsv \
--first_sequence=image \
--checkpoint_dir=./clip_model/ \
--random_seed=42 \
--logging_steps=100 \
--save_checkpoint_steps=500 \
--sequence_length=32 \
--micro_batch_size=2 \
--app_name=clip
提取出的特征存储在一个tsv文件中,每行对应输入中的一个文本或一个图片,维度之间采用制表符\t分隔。
未来展望
在未来,我们计划在EasyNLP框架中公开以PyTorch实现的CLIP模型,覆盖各个常见中文领域,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型(特别是中文模型),来支持各种NLP和多模态任务。此外,阿里云机器学习PAI团队也在持续推进中文多模态模型的自研工作,欢迎用户持续关注我们,也欢迎加入我们的开源社区,共建中文NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger. Ilya Sutskever. Learning transferable visual models from natural language supervision. arXiv
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. arXiv
- Jiaxi Gu, Xiaojun Meng, Guansong Lu, Lu Hou, Minzhe Niu, Xiaodan Liang, Lewei Yao, Runhui Huang, Wei Zhang, Xin Jiang, Chunjing Xu, Hang Xu. Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework. arXiv
阿里灵杰回顾
原文链接:http://click.aliyun.com/m/1000346337/
本文为阿里云原创内容,未经允许不得转载。
EasyNLP带你玩转CLIP图文检索的更多相关文章
- 带你玩转Visual Studio
带你玩转Visual Studio 带你新建一个工程 工程目录下各文件的含义 解决方案与工程 在这之前先了解一个概念:解决方案与工程. 解决方案(Solution):一个大型项目的整体的工作环境: 工 ...
- 来吧!带你玩转 Excel VBA
来吧!带你玩转 Excel VBA 从错失良机到艰辛的DOS征程,从坎坷购机自学路到转机起程,从爱好到事业,他从一个完全不懂电脑的人到VBA高级应用者,一切全是自学…… 我是罗刚君,来自四川的一个小县 ...
- 转: 带你玩转Visual Studio——带你理解多字节编码与Unicode码
上一篇文章带你玩转Visual Studio——带你跳出坑爹的Runtime Library坑帮我们理解了Windows中的各种类型C/C++运行时库及它的来龙去脉,这是C++开发中特别容易误入歧途的 ...
- iOS开发——高级UI&带你玩转UITableView
带你玩装UITableView 在实际iOS开发中UITableView是使用最多,也是最重要的一个控件,如果你不会用它,那别说什么大神了,菜鸟都不如. 其实关于UItableView事非常简单的,实 ...
- acdream 瑶瑶带你玩激光坦克 (模拟)
瑶瑶带你玩激光坦克 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 256000/128000KB (Java/Others) Submi ...
- Android SurfaceView实战 带你玩转flabby bird (下)
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/43063331,本文出自:[张鸿洋的博客] 1.概述 在Android Surfa ...
- B - 瑶瑶带你玩激光坦克
B - 瑶瑶带你玩激光坦克 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 256000/128000KB (Java/Others) S ...
- 分分钟带你玩转 Web Services【2】CXF
在实践中一直在使用 JAX-WS 构建 WebService 服务,服务还是非常稳定.高效的. 但还是比较好奇其他的 WebService 开源框架,比如:CXF/Axis2/Spring WS等. ...
- wing带你玩转自定义view系列(2) 简单模仿qq未读消息去除效果
上一篇介绍了贝塞尔曲线的简单应用 仿360内存清理效果 这一篇带来一个 两条贝塞尔曲线的应用 : 仿qq未读消息去除效果. 转载请注明出处:http://blog.csdn.net/wingicho ...
- wing带你玩转自定义view系列(1) 仿360内存清理效果
本篇是接自 手把手带你做自定义view系列 宗旨都是一样,带大家一起来研究自定义view的实现,与其不同的是本系列省去了简单的坐标之类的讲解,重点在实现思路,用简洁明了的文章,来与大家一同一步步学习. ...
随机推荐
- 高级java进阶之类的卸载
首先来了解一下jvm(java虚拟机)中的几个比较重要的内存区域 方法区:在java的虚拟机中有一块专门用来存放已经加载的类信息.常量.静态变量以及方法代码的内存区域,叫做方法区. 常量池:常量池是方 ...
- 【leetcode 1799 N次操作后的最大分数和】状态压缩
回溯会超时,状态压缩 class Solution { public int maxScore(int[] nums) { int len = nums.length; int size = 1 &l ...
- python基础六(函数基础及参数使用)
一. 函数定义 1.什么是函数 函数就相当于具备某一功能的工具 函数的使用必须遵循一个原则: 先定义 后调用2.为何要用函数 代码冗余,程序的组织结构不清晰,可读性差 可维护性.扩展性差3.如何用函数 ...
- Informix日志报错:Could not do a physical-order read to fetch netxt row
jmeter请求接口,1线程不报错,2线程及以上报错"无法执行查询",看后台日志,报错Could not do a physical-order read to fetch net ...
- Moe RE - 【bugku】
发现好像没人写wp,虽然很简单但是写一个.... 题目 分析 下载文件打开,习惯首先丢到Exeinfo PE里看看有没有壳 没有壳的样子 那放心丢到IDA(64-bit)里面 一进去就看到很有嫌疑的字 ...
- KingbaseES V8R6集群运维案例之---在线扩容节点通讯故障问题
案例说明: KingbaseES V8R6集群节点之间通过ssh或securecmdd工具通讯,默认节点之间通过公钥和私钥方式认证,可以密码通讯:在执行集群节点扩容时,出现以下故障,节点之间仍需要输入 ...
- KingbaseES V8R6 逻辑恢复到新的 schema
前言 本文介绍一下KingbaseES V8R6版本中逻辑恢复时,将原有的对象恢复到新的schema. sys_restore命令中如果只加入了-g(原schema) -G(新schema)参数 那么 ...
- arch xfce启用自动挂载usb设备,自动访问usb设备,自动连接usb设备
1.安装gvfs sudo pacman -S gvfs GVFS(Gnome Virtual File System)是一个用于 GNOME 桌面环境的虚拟文件系统,它提供了一种统一的方式来访问和管 ...
- mybatis添加maven依赖
1 <dependencies> 2 <!--导入Mybatis依赖包--> 3 <dependency> 4 <groupId>org.mybatis ...
- 提升系统管理:监控和可观察性在DevOps中的作用
在不断发展的DevOps世界中,深入了解系统行为.诊断问题和提高整体性能的能力是首要任务之一.监控和可观察性是促进这一过程的两个关键概念,为系统的健康和性能提供了宝贵的可见性.虽然这些术语经常可以互换 ...