自然语言处理(NLP) - 前预训练时代的自监督学习
前预训练时代的自监督学习自回归、自编码预训练的前世

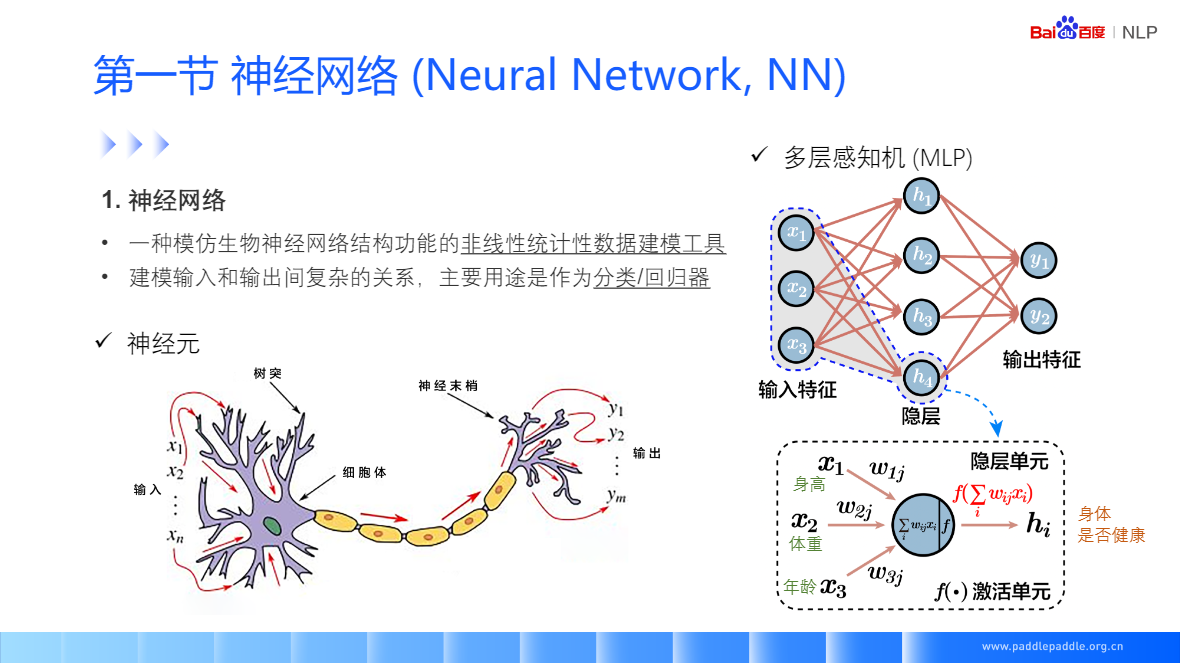
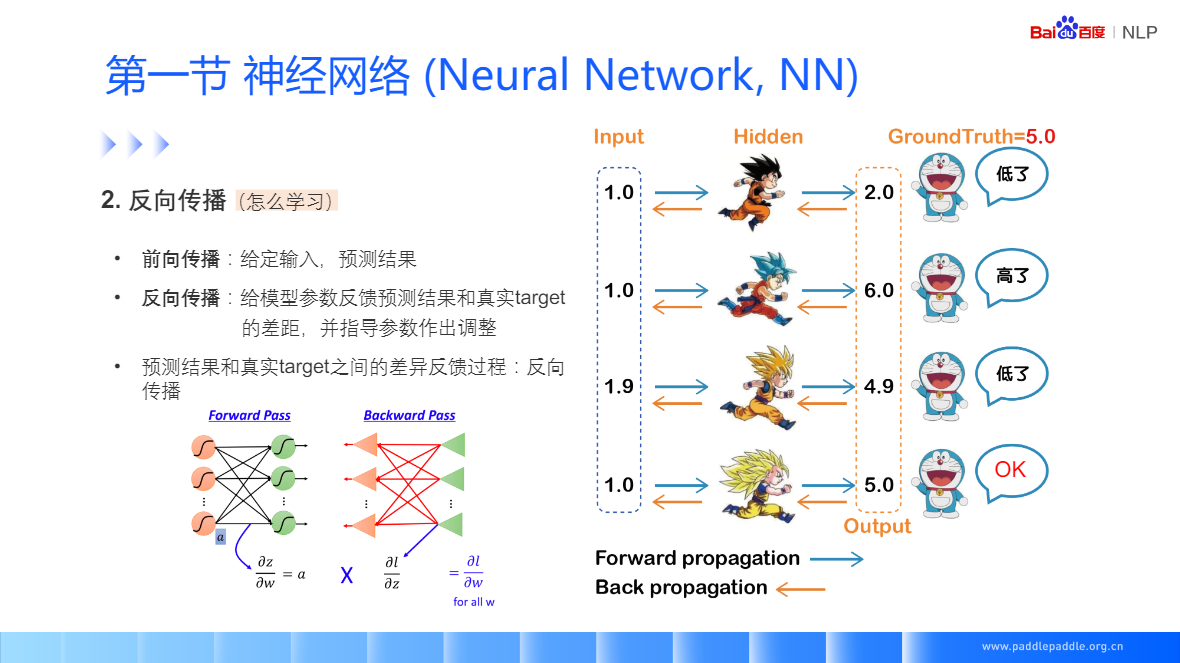
神经网络(Neural Network, NN)
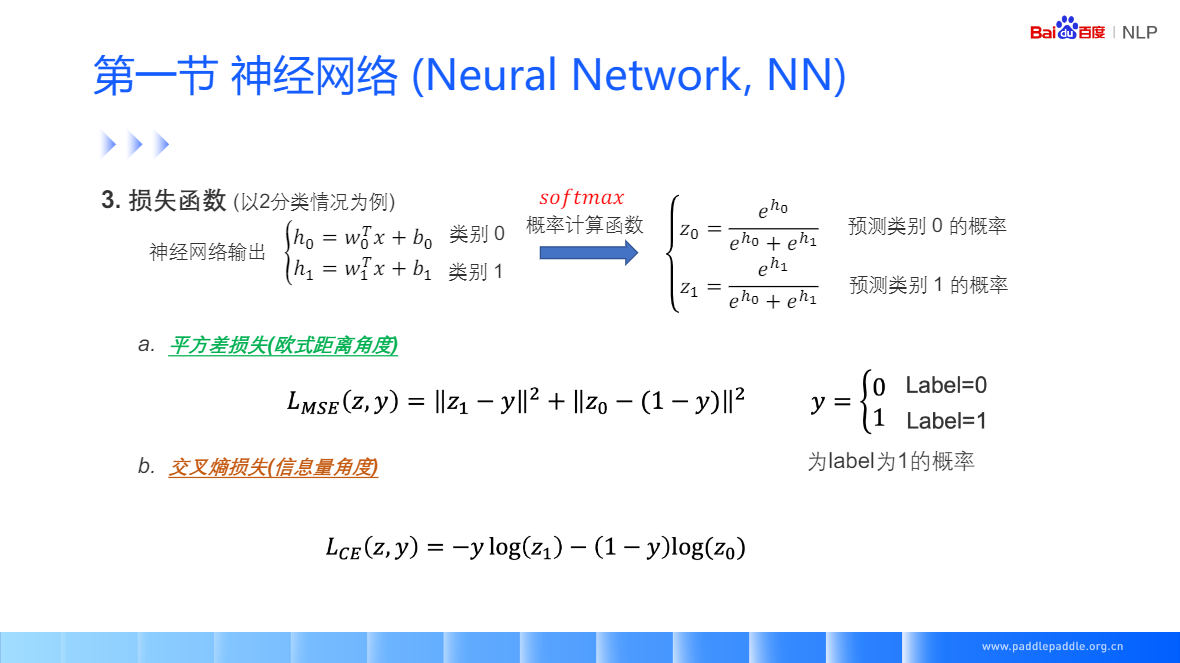
损失函数,度量神经网络的预测结果和真实结果相差多少
- 平方差损失(欧式距离角度)预测概率分部和实际标签概率的欧式距离
- 交叉熵损失(信息量角度)预测概率分部和真实概率分部的差异,指导神经网络学习时,更加稳定
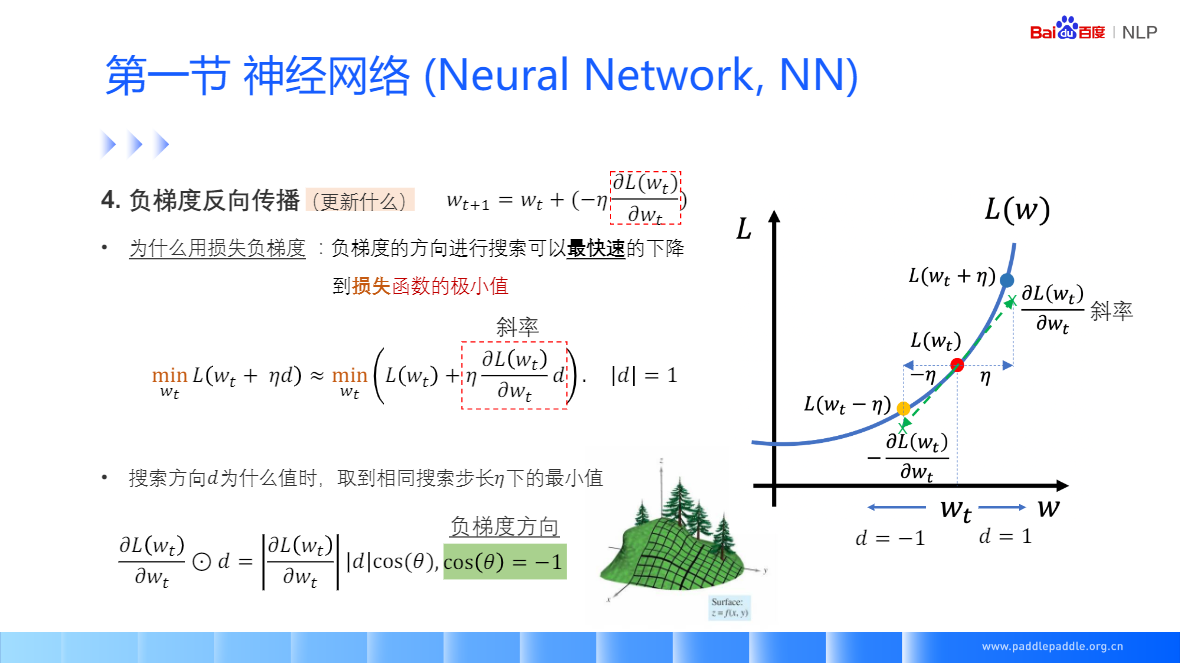
对参数W更新损失的负梯度
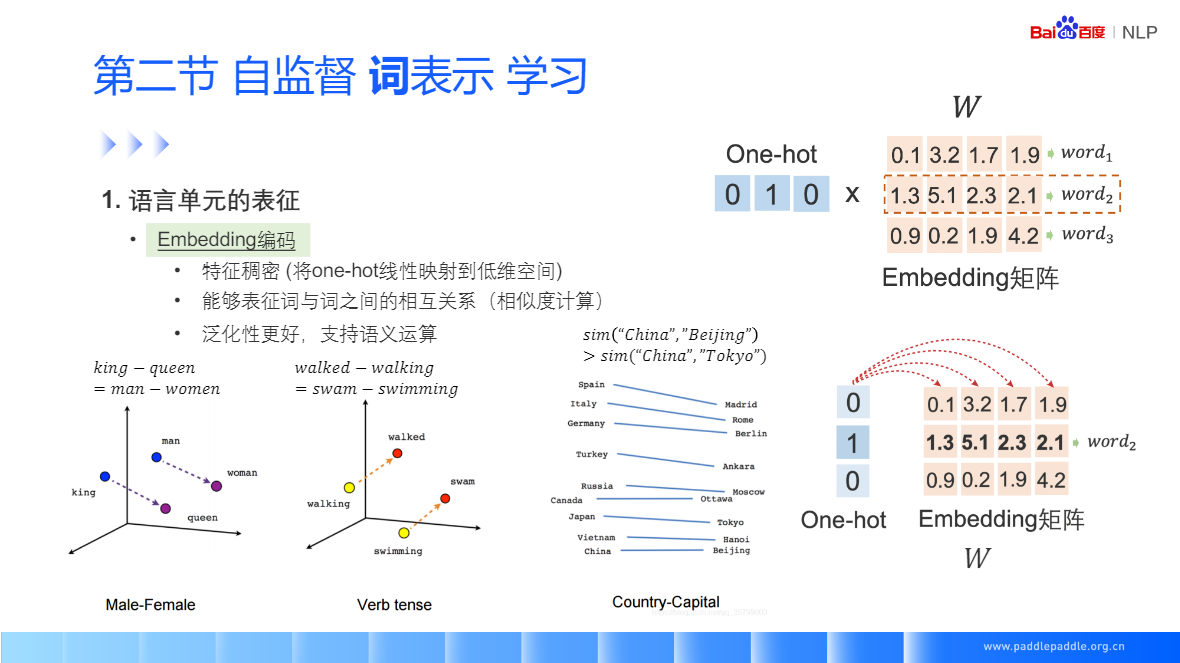
One-hot 人为规定,不需要学习,在推荐里有非常多的用处,(可以理解成完全命中)

词向量需要学习,可以很好的泛化结果,泛化性能比 one-hot 更好(可以理解成泛化关系的建模)
评估模型的好坏:有全体指标,以及一些公开的数据集,去评估词向量的相关性

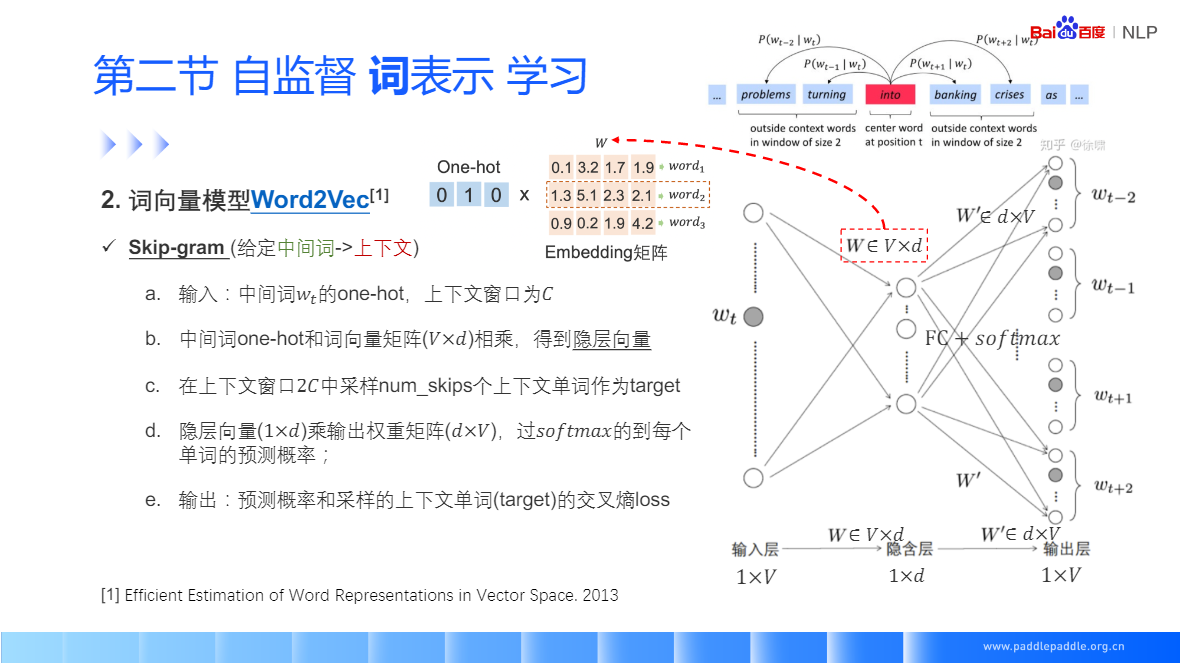
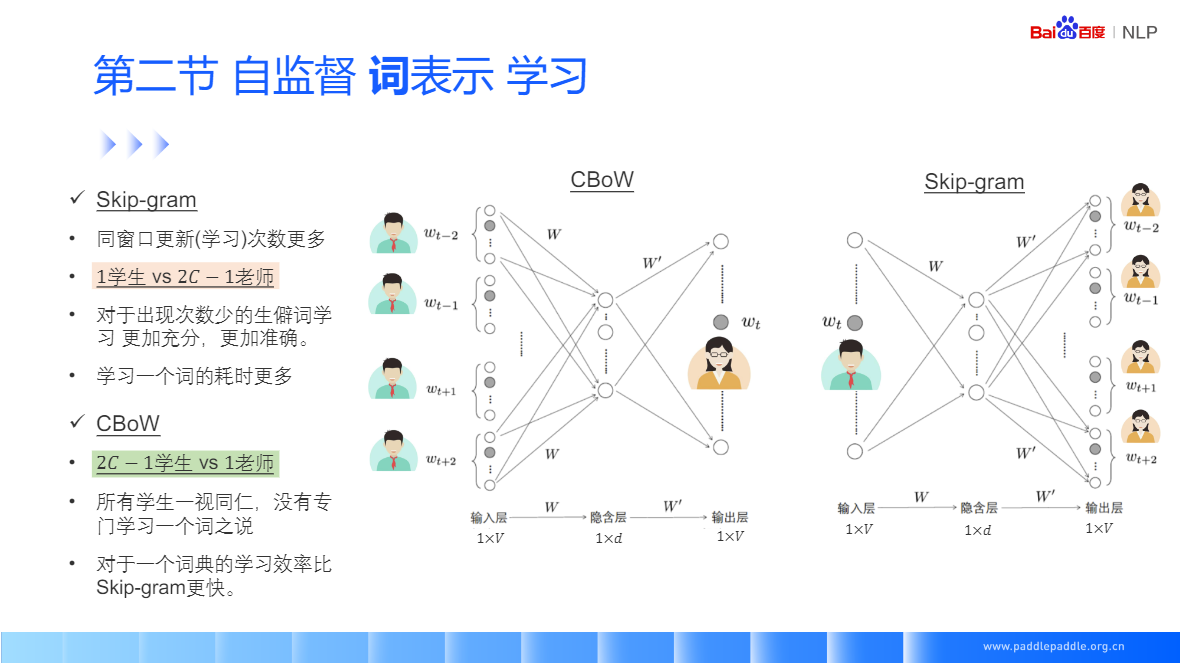
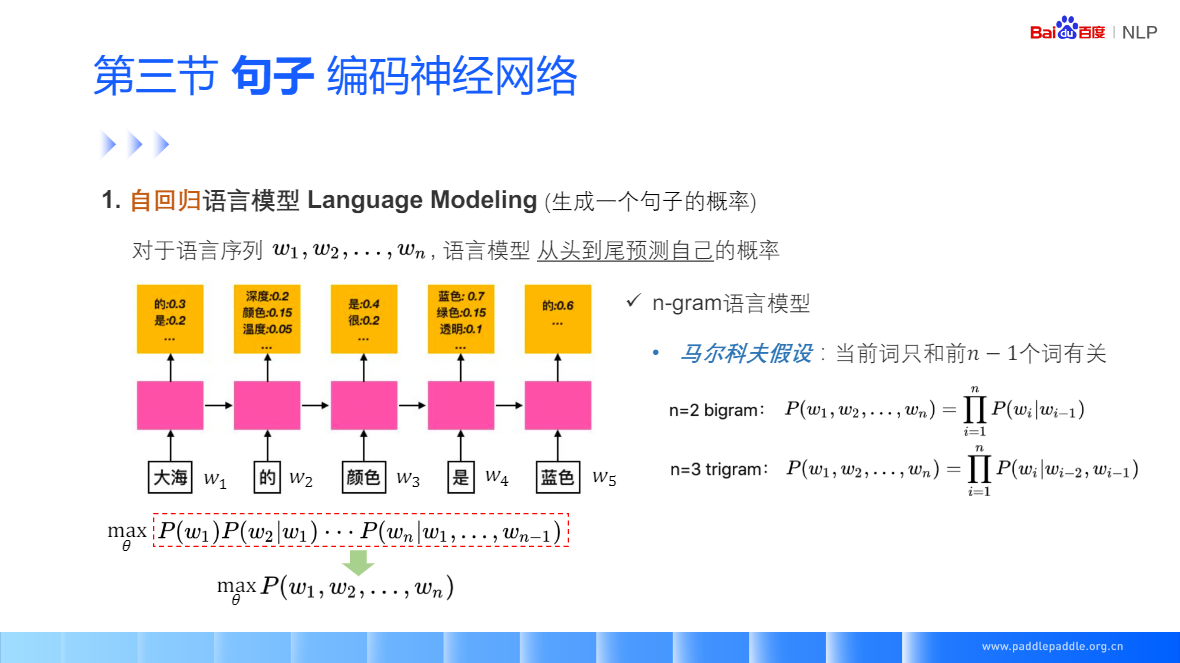
Skip-gram: 给定一个中间值,预测上下文窗口中的一个词

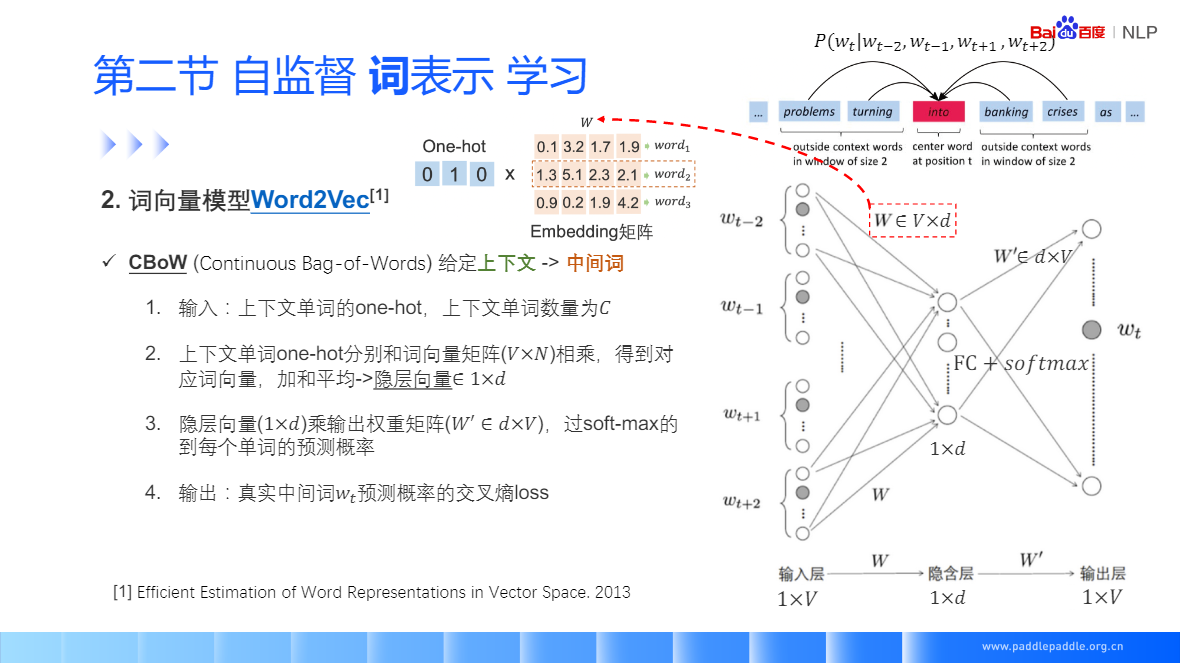
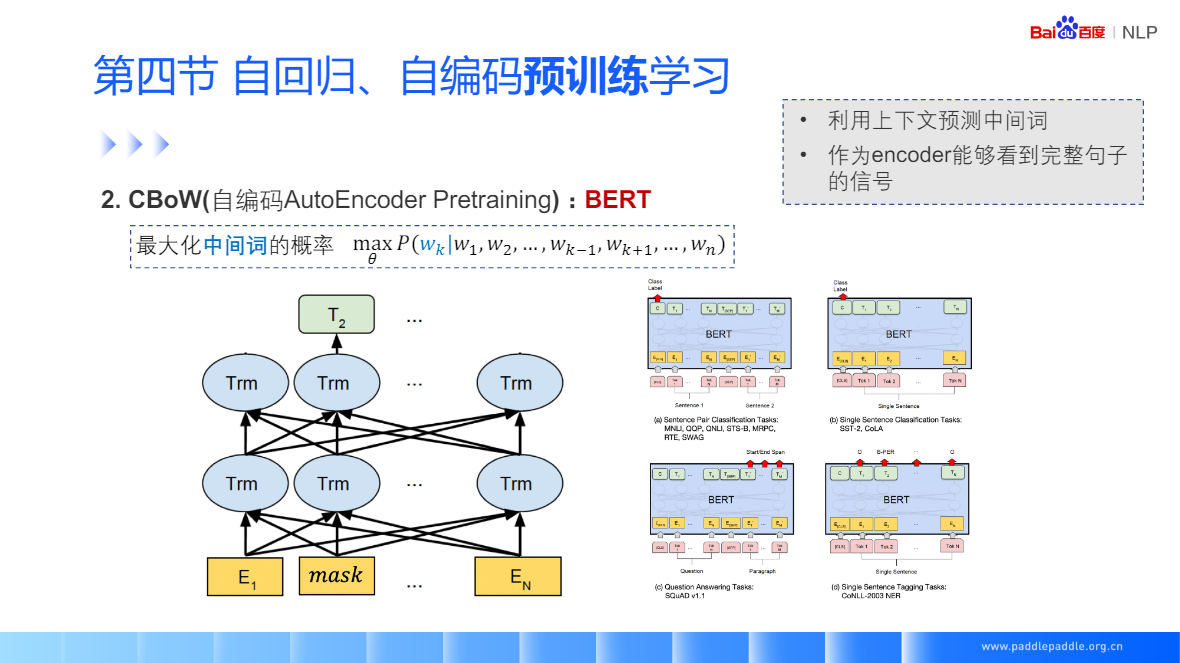
CBoW:给定一个上下文词,预测中间值
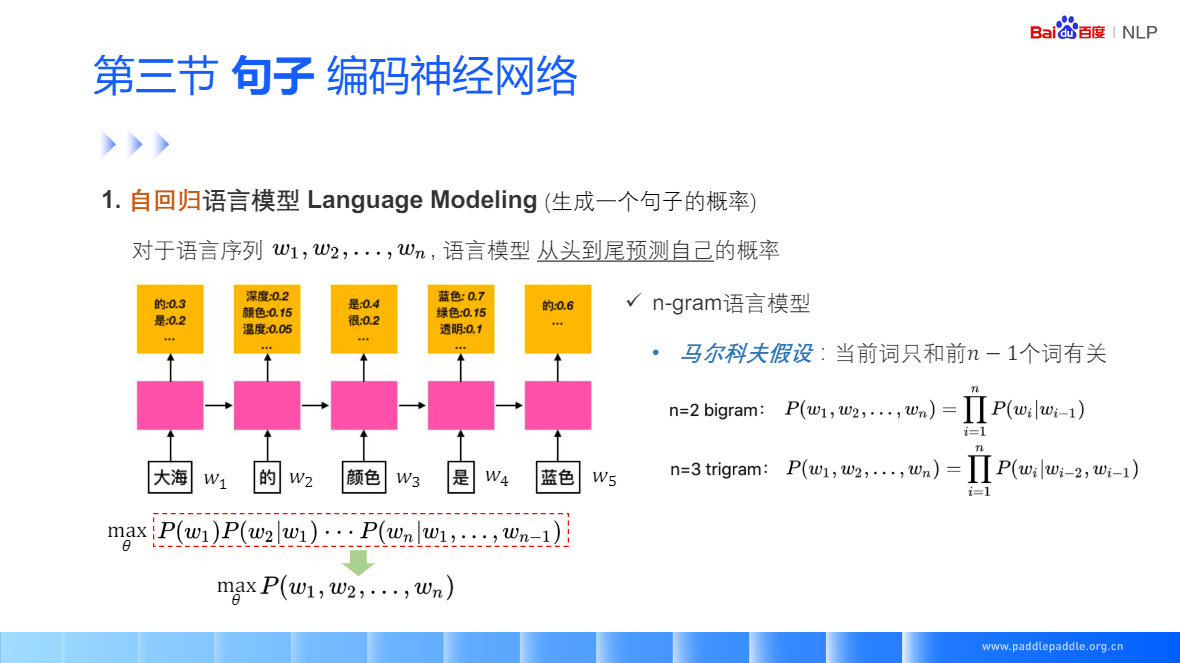
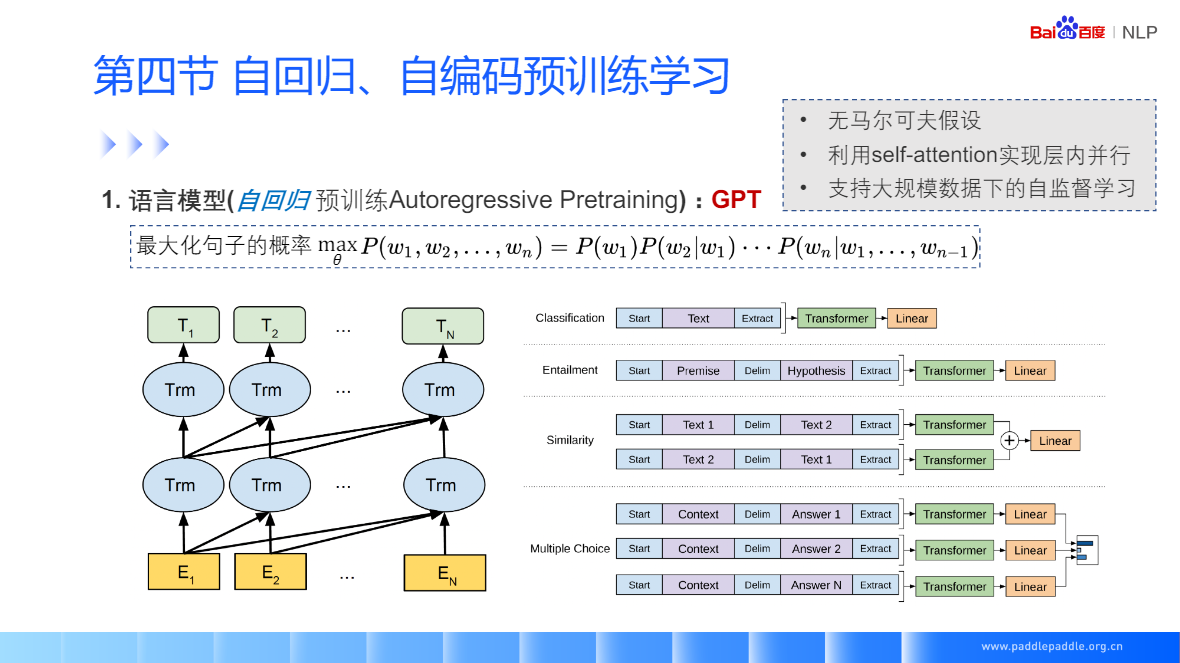
RNN 抛开马尔科夫假设,
Self-Attention:每个单词和整句所有话进行匹配,来获取当前单词对每个单词的重视程度,利用这个重视程序,对整句话的每个单词进行加权,加权的结果用于表示当前这个单词
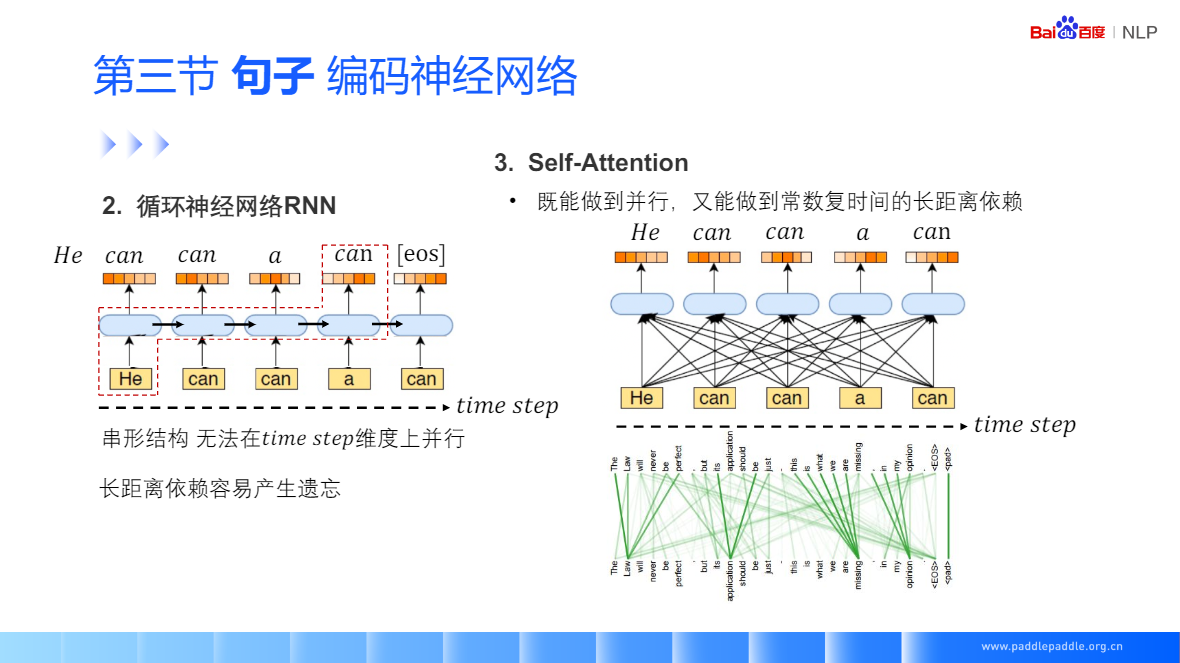
Self-Attention:也是非常流行的 Transformer 的核心模块,
Seft-Attention 没有考虑单词的顺序,所以为了更精装的表示位置信息,需要对句子的输入加个位置的序号 Positional Embedding
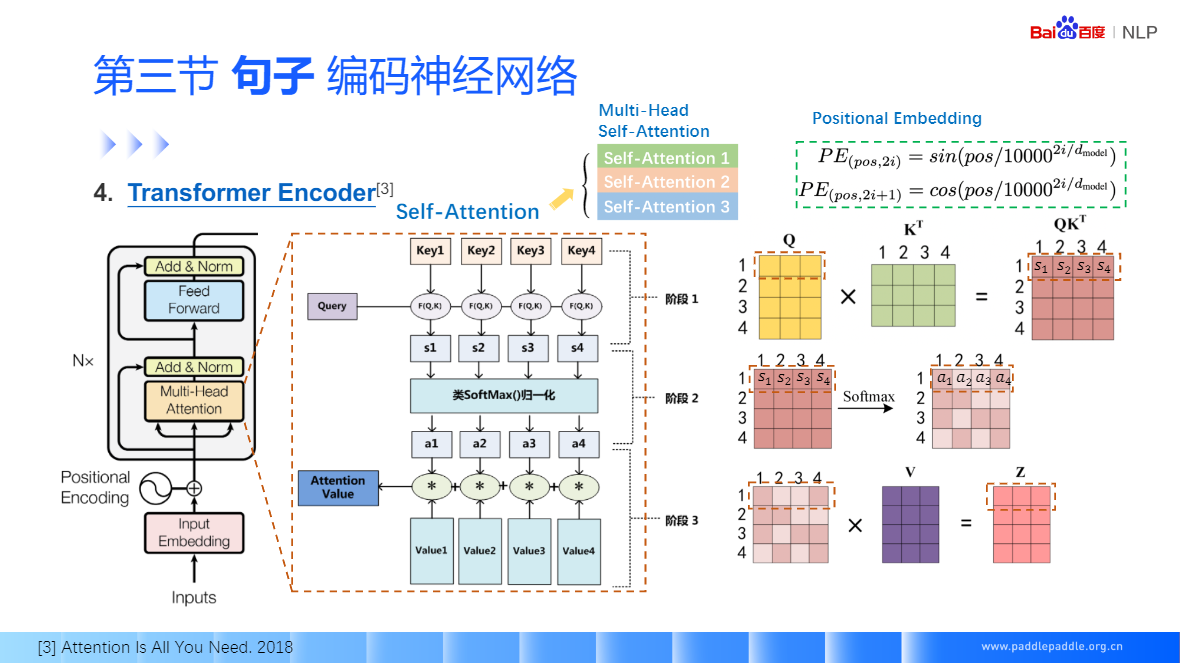
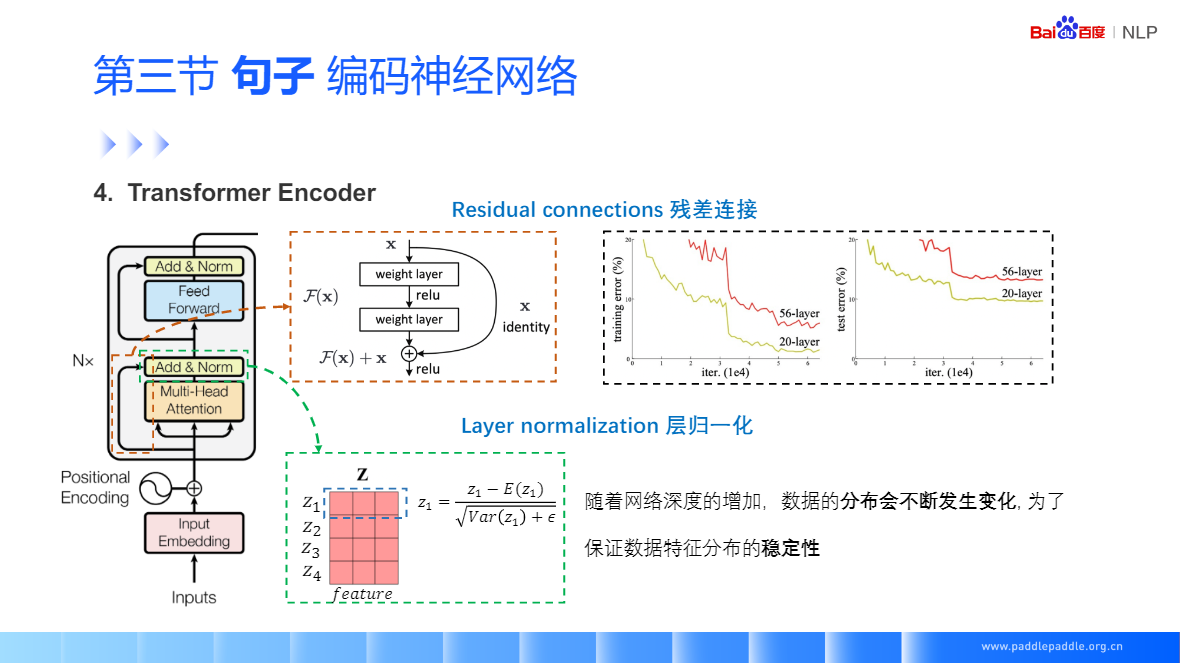
残差连接,很好的缓解梯度消失的问题,包括映射和直连接部分
https://aistudio.baidu.com/aistudio/education/lessonvideo/1451160
自然语言处理(NLP) - 前预训练时代的自监督学习的更多相关文章
- NLP之预训练
内容是结合:https://zhuanlan.zhihu.com/p/49271699 可以直接看原文 预训练一般要从图像处理领域说起:可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预 ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 预训练中Word2vec,ELMO,GPT与BERT对比
预训练 先在某个任务(训练集A或者B)进行预先训练,即先在这个任务(训练集A或者B)学习网络参数,然后存起来以备后用.当我们在面临第三个任务时,网络可以采取相同的结构,在较浅的几层,网络参数可以直接加 ...
- BERT总结:最先进的NLP预训练技术
BERT(Bidirectional Encoder Representations from Transformers)是谷歌AI研究人员最近发表的一篇论文:BERT: Pre-training o ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型 ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
随机推荐
- Java数据类型、标识符
目录 JavaSE 标识符 数据类型 基本数据类型 引用数据类型 转义字符 JavaSE 标识符 定义 Java中用于定义名称的都是标识符.例:包名,类名,变量名,方法名等. 组成 由数字.字母._. ...
- 在云服务器上搭建个人版chatGPT及后端Spring Boot集成chat GPT
总结/朱季谦 本文分成两部分,包括[国内服务器上搭建chat GPT]和[后端Spring Boot集成chat GPT]. 无论是在[国内服务器上搭建chat GPT]和[后端Spring Boot ...
- broadcom Ethernet BCM57412 驱动更新记录(dkms方式)
一 背景 现场Dell R740xd2机器使用网卡Broadcom 57412 10Gb SFP+,固件版本22.21.06.80.bnxt_en.ko内核模块是该网卡的驱动,我们默认的驱动版本为1. ...
- Hyperledger Fabric 使用 CouchDB 和复杂智能合约开发
前言 在上个实验中,我们已经实现了简单智能合约实现及客户端开发,但该实验中智能合约只有基础的增删改查功能,且其中的数据管理功能与传统 MySQL 比相差甚远.本文将在前面实验的基础上,将 Hyperl ...
- 简单的了解下 Fetch API 的工作原理
一.简介 Fetch API是一种现代的Web API,提供了一种异步获取网络资源的方法.由于其简单性.灵活性和一致性,它已经成为Web应用程序中获取数据和资源的流行选择.在本文中,我们将深入探讨Fe ...
- ip addr命令解析
转载请注明出处: 1.ip addr命令使用解析 ip addr 命令是Linux系统中的一个网络管理工具,用于显示和配置系统中的网络接口及其地址信息.它可以列出系统中所有的网络接口及其详细信息,包括 ...
- awk判断整除(包含小数和负数)
awk判断整除常用的方法是用内置的int或者求余数的算符% 被整数整除 输出0-100之间能被9整除的整数 使用 num/9==int(num/9) 的判断方法可以很好实现. awk 'BEGIN{ ...
- css实现文本溢出省略号
CSS常用属性: overflow:hidden; //超出的文本隐藏 text-overflow:ellipsis; //溢出用省略号显示 white-space:nowrap; //溢出不换行,只 ...
- 2022-12-03:部门工资最高的员工。以下数据Max 和 Jim 在 IT 部门的工资都是最高的,Henry 在销售部的工资最高。sql语句如何写? 输出结果如下: department emp
2022-12-03:部门工资最高的员工.以下数据Max 和 Jim 在 IT 部门的工资都是最高的,Henry 在销售部的工资最高.sql语句如何写? 输出结果如下: department empl ...
- 2021-04-21:手写代码:Dijkstra算法。
2021-04-21:手写代码:Dijkstra算法. 福大大 答案2021-04-21: Dijkstra算法是一种基于贪心策略的算法.每次新扩展一个路程最短的点,更新与其相邻的点的路程.时间紧,未 ...