pandas高效读取大文件的探索之路
使用 pandas 进行数据分析时,第一步就是读取文件。
在平时学习和练习的过程中,用到的数据量不会太大,所以读取文件的步骤往往会被我们忽视。
然而,在实际场景中,面对十万,百万级别的数据量是家常便饭,即使千万,上亿级别的数据,单机处理也问题不大。
不过,当数据量和数据属性多了之后,读取文件的性能瓶颈就开始浮现出来。
当我们第一次拿到数据时,经常会反反复复的读取文件,尝试各种分析数据的方法。
如果每次读取文件都要等一段时间,不仅会影响工作效率,还影响心情。
下面记录了我自己优化pandas读取大文件效率的探索过程。
1. 准备部分
首先,准备数据。
下面的测试用的数据是一些虚拟币的交易数据,除了常用的K线数据之外,还包含很多分析因子的值。
import pandas as pd
fp = "all_coin_factor_data_12H.csv"
df = pd.read_csv(fp, encoding="gbk")
df.shape
# 运行结果
(398070, 224)
总数据量接近40万,每条数据有224个属性。
然后,封装一个简单的装饰器来计时函数运行时间。
from time import time
def timeit(func):
def func_wrapper(*args, **kwargs):
start = time()
ret = func(*args, **kwargs)
end = time()
spend = end - start
print("{} cost time: {:.3f} s".format(func.__name__, spend))
return ret
return func_wrapper
2. 正常读取
先看看读取这样规模的数据,需要多少时间。
下面的示例中,循环读取10次上面准备的数据all_coin_factor_data_12H.csv。
import pandas as pd
@timeit
def read(fp):
df = pd.read_csv(
fp,
encoding="gbk",
parse_dates=["time"],
)
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.csv"
for i in range(10):
read(fp)
运行结果如下:
读取一次大概27秒左右。
3. 压缩读取
读取的文件all_coin_factor_data_12H.csv大概1.5GB左右,pandas是可以直接读取压缩文件的,尝试压缩之后读取性能是否能够提高。
压缩之后,大约 615MB 左右,压缩前大小的一半不到点。
import pandas as pd
@timeit
def read_zip(fp):
df = pd.read_csv(
fp,
encoding="gbk",
parse_dates=["time"],
compression="zip",
)
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.zip"
for i in range(10):
read_zip(fp)
运行结果如下: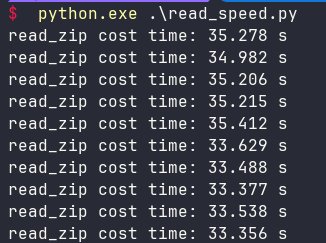
读取一次大概34秒左右,还不如直接读取来得快。
4. 分批读取
接下来试试分批读取能不能提高速度,分批读取的方式是针对数据量特别大的情况,
单机处理过亿数据量的时候,经常会用到这个方法,防止内存溢出。
先试试每次读取1万条:
import pandas as pd
@timeit
def read_chunk(fp, chunksize=1000):
df = pd.DataFrame()
reader = pd.read_csv(
fp,
encoding="gbk",
parse_dates=["time"],
chunksize=chunksize,
)
for chunk in reader:
df = pd.concat([df, chunk])
df = df.reset_index()
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.csv"
for i in range(10):
read_chunk(fp, 10000)
运行结果如下: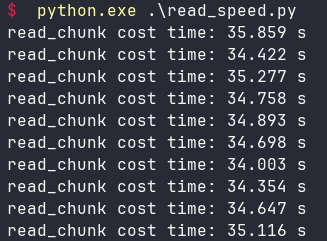
和读取压缩文件的性能差不多。
如果调整成每次读取10万条,性能会有一些微提高。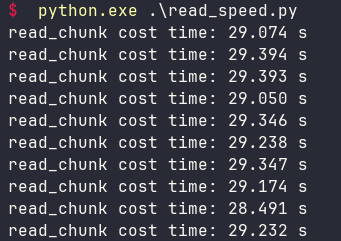
分批读取时,一次读取的越多(只要内存够用),速度越快。
其实我也试了一次读取1千条的性能,非常慢,这里就不截图了。
5. 使用polars读取
前面尝试的方法,效果都不太好,下面引入一个和pandas兼容的库Polars。
Polars是一个高性能的DataFrame库,它主要用于操作结构化数据。
它是用Rust写的,主打就是高性能。
使用Polars读取文件之后返回的Dataframe虽然和pandas的DataFrame不完全一样,
当可以通过一个简单的to_pandas方法来完成转换。
下面看看使用Polars读取文件的性能:
import polars as pl
@timeit
def read_pl(fp):
df = pl.read_csv(
fp,
encoding="gbk",
try_parse_dates=True,
)
return df.to_pandas()
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.csv"
for i in range(10):
read_pl(fp)
运行结果如下: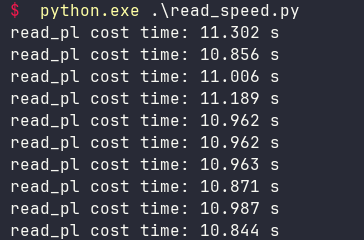
使用Polars后性能提高非常明显,看来,混合使用Polars和pandas是一个不错的方案。
6. 序列化后读取
最后这个方法,其实不是直接读取原始数据,而是将原始数据转换为python自己的序列化格式(pickle)之后,再去读取。
这个方法多了一个转换的步骤:
fp = "./all_coin_factor_data_12H.csv"
df = read(fp)
df.to_pickle("./all_coin_factor_data_12H.pkl")
生成一个 序列化文件:all_coin_factor_data_12H.pkl。
然后,测试下读取这个序列化文件的性能。
@timeit
def read_pkl(fp):
df = pd.read_pickle(fp)
return df
if __name__ == "__main__":
fp = "./all_coin_factor_data_12H.pkl"
for i in range(10):
read_pkl(fp)
运行结果如下: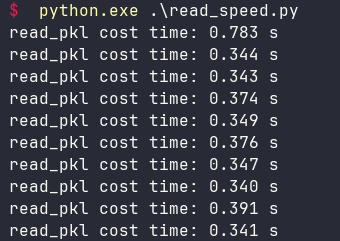
这个性能出乎意料之外的好,而且csv文件序列化成pkl文件之后,占用磁盘的大小也只有原来的一半。csv文件1.5GB左右,pkl文件只有690MB。
这个方案虽然性能惊人,但也有一些局限,
首先是原始文件不能是那种实时变化的数据,因为原始csv文件转换为pkl文件也是要花时间的(上面的测试没有算这个时间)。
其次,序列化之后的pkl文件是python专用的,不像csv文件那样通用,不利于其他非python的系统使用。
7. 总结
本文探讨了一些pandas读取大文件的优化方案,最后比较好的就是Polars方案和pickle序列化方案。
如果我们的项目是分析固定的数据,比如历史的交易数据,历史天气数据,历史销售数据等等,
那么,就可以考虑pickle序列化方案,先花时间讲原始数据序列化,
后续的分析中不担心读取文件浪费时间,可以更高效的尝试各种分析思路。
除此之外的情况,建议使用Polars方案。
最后补充一点,如果读取文件的性能对你影响不大,那就用原来的方式,千万不要画蛇添足的去优化,
把精力花在数据分析的业务上。
pandas高效读取大文件的探索之路的更多相关文章
- Java高效读取大文件
1.概述 本教程将演示如何用Java高效地读取大文件.这篇文章是Baeldung (http://www.baeldung.com/) 上“Java——回归基础”系列教程的一部分. 2.在内存中读取 ...
- Java高效读取大文件(转)
1.概述 本教程将演示如何用Java高效地读取大文件.这篇文章是Baeldung(http://www.baeldung.com/) 上“Java——回归基础”系列教程的一部分. 2.在内存中读取 读 ...
- 高效读取大文件,再也不用担心 OOM 了!
内存读取 第一个版本,采用内存读取的方式,所有的数据首先读读取到内存中,程序代码如下: Stopwatch stopwatch = Stopwatch.createStarted(); // 将全部行 ...
- pandas read_csv读取大文件的Memory error问题
今天在读取一个超大csv文件的时候,遇到困难:首先使用office打不开然后在python中使用基本的pandas.read_csv打开文件时:MemoryError 最后查阅read_csv文档发现 ...
- pandas读取大文件时memoryerror的解决办法
再用pd.read_csv读取大文件时,如果文件太大,会出现memoryerror的问题. 解决办法一:pd.read_csv的参数中有一个chunksize参数,为其赋值后,返回一个可迭代对象Tex ...
- php如何高效的读取大文件
通常来说在php读取大文件的时候,我们采用的方法一般是一行行来讲取,而不是一次性把文件全部写入内存中,这样会导致php程序卡死,下面就给大家介绍这样一个例子. 需求:有一个800M的日志文件,大约有5 ...
- PHP如何快速读取大文件
在PHP中,对于文件的读取时,最快捷的方式莫过于使用一些诸如file.file_get_contents之类的函数,简简单单的几行代码就能 很漂亮的完成我们所需要的功能.但当所操作的文件是一个比较大的 ...
- php使用file函数、fseek函数读取大文件效率分析
php读取大文件可以使用file函数和fseek函数,但是二者之间效率可能存在差异,本文章向大家介绍php file函数与fseek函数实现大文件读取效率对比分析,需要的朋友可以参考一下. 1. 直接 ...
- PHP读取大文件的几种方法介绍
读取大文件一直是一个头痛的问题,我们像使用php开发读取小文件可以直接使用各种函数实现,但一到大文章就会发现常用的方法是无法正常使用或时间太长太卡了,下面我们就一起来看看关于php读取大文件问题解决办 ...
- php -- 读取大文件
在PHP中,对于文件的读取时,最快捷的方式莫过于使用一些诸如file.file_get_contents之类的函数,简简单单的几行代码就能 很漂亮的完成我们所需要的功能.但当所操作的文件是一个比较大的 ...
随机推荐
- Jenkins Pipeline 流水线 - 声明式 Demo
Jenkins Pipeline 流水线 流水线既能作为任务的本身,也能作为 Jenkinsfile 使用流水线可以让我们的任务从UI手动操作,转换为代码化,像dockerfile 一样.从shell ...
- python WordCloud matplotlib docx 简易生成docx报告
# encode=utf-8 import numpy as np import matplotlib.pyplot as plt from docx import Document from doc ...
- CPU--实模式与保护模式
一.实模式(实地址访问模式) 是Intel公司80286及以后的x86(80386,80486和80586等)兼容处理器(CPU)的一种操作模式. 实模式被特殊定义为20位地址内存可访问空间上,这就意 ...
- 阿里云视频云人脸生成领域最新研究成果入选CVPR2022
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)作为计算机视觉和模式识别领域的顶级会议,在全球具有极高的权威性.目前在中 ...
- 邮箱发送SMARTFORMS 转 PDF附件
事务代码smartforms创建一个表单ZTEST001 将表单转换成PDF并添加到邮件的附件中发送给用户 "---------------------------------------- ...
- UVA - 10935:Throwing cards away I (简单模拟)
题目大意 桌上有一叠牌,自上而下编号为1~n.若桌上牌数大于1张,那么丢弃一张顶部牌后,再将现在的顶部牌移到最后.要求给出模拟过程和最终剩余的牌号 思路分析 典型队列模拟,丢弃即出队,移到最后即入队, ...
- 第九届蓝桥杯(2018)C/C++大学A组省赛题解
第一题:分数 1/1 + 1/2 + 1/4 + 1/8 + 1/16 + - 每项是前一项的一半,如果一共有20项, 求这个和是多少,结果用分数表示出来. 类似:3/2 当然,这只是加了前2项而已. ...
- SpringBoot 动态数据源
SpringBoot 实现动态数据源切换 Spring Boot + Mybatis Plus + Druid + MySQL 实现动态数据源切换及动态 SQL 语句执行. 项目默认加载 applic ...
- MongoDB 根据多个条件批量修改
转载请注明出处: MongoDB 根据单个条件修改的sql 如下: db.collection_name.update({"userid":"1111111"} ...
- WPF Prism框架Region失效了?
站长最近转载了痕迹的Prism 8系列博文,不知道你对该框架是否有一定了解了?不了解,可以看看本号转载的系列: WPF Prism框架合集(2.创建Prism应用程序) WPF Prism框架合集(3 ...