【数据可视化-pyecharts】pyecharts快速入门
pyecharts快速开始
首先开始来绘制你的第一个图表
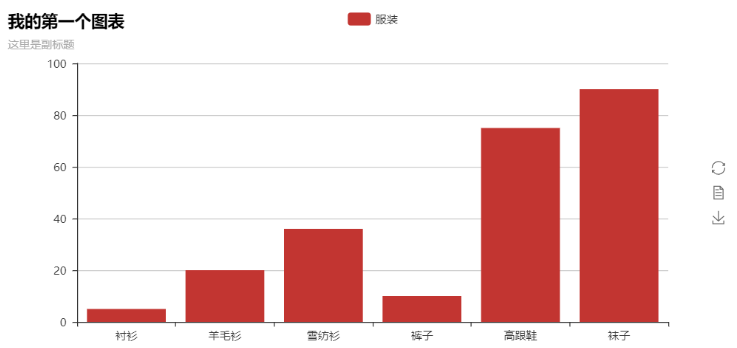
from pyecharts import Bar
bar = Bar("我的第一个图表", "这里是副标题")
bar.add("服装", ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"], [5, 20, 36, 10, 75, 90])
# bar.print_echarts_options() # 该行只为了打印配置项,方便调试时使用
bar.render() # 生成本地 HTML 文件
add()
主要方法,用于添加图表的数据和设置各种配置项print_echarts_options()
打印输出图表的所有配置项render()
默认将会在根目录下生成一个 render.html 的文件,支持 path 参数,设置文件保存位置,如 render(r"e:\my_first_chart.html"),文件用浏览器打开。
Note: 可以按右边的下载按钮将图片下载到本地,如果想要提供更多实用工具按钮,请在 add() 中设置 is_more_utils 为 True
使用主题
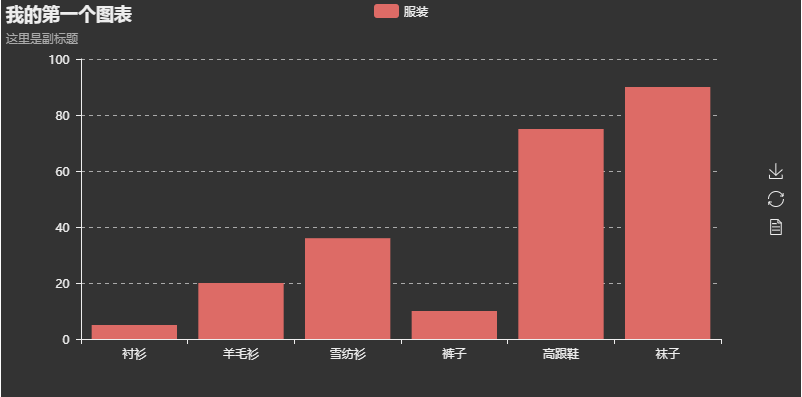
自 0.5.2+ 起,pyecharts 支持更换主体色系。下面是跟换为 'dark' 的例子:
from pyecharts import Bar
bar = Bar("我的第一个图表", "这里是副标题")
bar.use_theme('dark')
bar.add("服装", ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"], [5, 20, 36, 10, 75, 90])
bar.render()
pyecharts 支持另外 5 个主体色系,请移步到主题色系获取更多配置信息。
使用主题插件
echarts 自带 dark 主题,pyecharts 也就自带了 dark。 echarts-themes-pypkg 主题插件提供了如下主题
- vintage
- macarons
- infographic
- shine
- roma
- westeros
- wonderland
- chalk
- halloween
- essos
- walden
- purple-passion
- romantic
安装主题插件
pip install echarts-themes-pypkg
使用主题
更换单个图形主题
bar.use_theme("vintage")
更换运行环境内所有图表主题
from pyecharts import configure # 将这行代码置于首部
configure(global_theme='dark') bar = Bar()
# 其他代码
主题风格
vintage

macarons

infographic

shine

roma

westeros

wonderland

chalk

halloween

essos

walden

purple-passion

romantic

图形绘制过程
图表类提供了若干了构建和渲染的方法,在使用的过程中,建议按照以下的顺序分别调用:
数据解析与导入篇:
参考:http://pyecharts.org/#/zh-cn/data_import?id=networkx-%E5%BA%93
介绍了一些常用的数据处理模块和库。这些并不是 pyecharts 核心的部分。
#add 数据直接支持 numpy.array 对象,例如: from pyecharts import Bar
import numpy as np clothes = ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"]
v1 = np.array([5, 20, 36, 10, 75, 90])
bar = Bar("衣服销量")
bar.add("商家A", clothes, v1, is_stack=True)
bar.render()
numpy 数据类型
#在 pyecharts.base.Base.add(name, x_axis, y_axis) 函数中,数据参数通常要求数据是两个长度相等的列表。 from pyecharts import Line t_data = [(21, '2017-12-01'), (19, '2017-12-02'), (20, '2017-12-03')]
hs, ds = zip(*t_data)
line = Line('High Temperature')
line.add('High', ds, hs)
line.render()
zip 函数
数据格式化处理函数,能够将源数据转化为符合 pyecharts 的数据。
具体转化格式如下: 1、元组列表
[(A1, B1), (A2, B2), (A3, B3), (A4, B4)] --> k_lst[ A[i1, i2...] ], v_lst[ B[i1, i2...] ]
2、字典列表
[{A1: B1}, {A2: B2}, {A3: B3}, {A4: B4}] --> k_lst[ A[i1, i2...] ], v_lst[ B[i1, i2...] ]
3、字典
{A1: B1, A2: B2, A3: B3, A4: B4} -- > k_lst[ A[i1, i2...] ], v_lst[ B[i1, i2...] ] o_data = [('A', ''), ('B', ''), ('C', '')]
x, y = Base.cast(o_data)
print(x) # ['A', 'B', 'C']
print(y) # ['34', '45', '12']
Base.cast 函数
安装
borax 要求 Python3.5 以上,可以使用以下命令安装这个库。
$ pip install borax函数定义文档
该模块使用 fetch 函数,签名如下:
fetch(iterable, key, *keys, default=EMPTY, defaults=None, getter=None)各参数的意义如下:
- iterable:数据列表
- key / keys:键值、属性访问方式的索引
- default:默认值,用于选择单个属性
- defaults:默认值字典,用于选择多个属性
- getter:自定义访问回调函数
应当注意的是,在使用时, default 、 defaults 和 getter 参数必须使用关键字方式传递,详情参考 PEP 3102。
示例
选取多个属性
from borax.fetch import fetch objects = [
{'id': 282, 'name': 'Alice', 'age': 30},
{'id': 217, 'name': 'Bob', 'age': 56},
{'id': 328, 'name': 'Charlie', 'age': 56},
] names, ages = fetch(objects, 'name', 'age')
print(names)
print(ages) #输出
#['Alice', 'Bob', 'Charlie']
#[30, 56, 56]
borax.fetch 模块
networkx 库
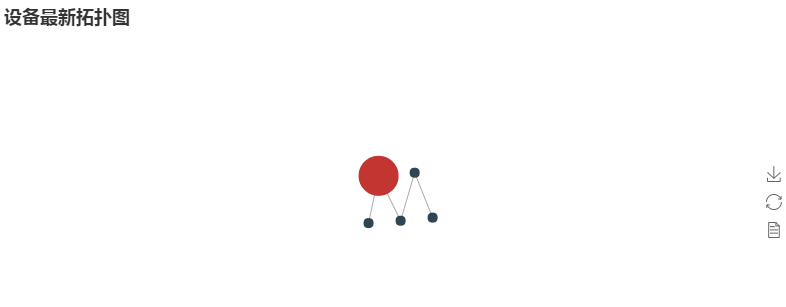
对于复杂的关系图,可以使用 networkx 库构建节点和连线,并传递给 add 函数。如下面的例子。
# coding=utf8 from __future__ import unicode_literals import networkx as nx
from networkx.readwrite import json_graph
from pyecharts import Graph g = nx.Graph()
categories = ['网关', '节点']
g.add_node('FF12C904', name='Gateway 1', symbolSize=40, category=0)
g.add_node('FF12CA02', name='Node 11', category=1)
g.add_node('FF12C326', name='Node 12', category=1)
g.add_node('FF45C023', name='Node 111', category=1)
g.add_node('FF230933', name='Node 1111', category=1) g.add_edge('FF12C904', 'FF12CA02')
g.add_edge('FF12C904', 'FF12C326')
g.add_edge('FF12CA02', 'FF45C023')
g.add_edge('FF45C023', 'FF230933') g_data = json_graph.node_link_data(g)
eg = Graph('设备最新拓扑图')
eg.add('Devices', nodes=g_data['nodes'], links=g_data['links'], categories=categories)
# eg.show_config()
eg.render()
networkx 库
Pandas&Numpy 简单示例
如果使用的是 Numpy 或者 Pandas,可以参考这个示例

Note: 使用 Pandas&Numpy 时,整数类型请确保为 int,而不是 numpy.int32
当然你也可以采用更加酷炫的方式,使用 Jupyter Notebook 来展示图表,matplotlib 有的,pyecharts 也会有的
Note: 从 v0.1.9.2 版本开始,废弃 render_notebook() 方法,现已采用更加 pythonic 的做法。直接调用本身实例就可以了。
比如这样

还有这样

如果使用的是自定义类,直接调用自定义类示例即可

更多 Jupyter notebook 的例子请参考 notebook-use-cases。可下载后运行看看。
如需使用 Jupyter Notebook 来展示图表,只需要调用自身实例即可,同时兼容 Python2 和 Python3 的 Jupyter Notebook 环境。所有图表均可正常显示,与浏览器一致的交互体验,这下展示报告连 PPT 都省了!!
【数据可视化-pyecharts】pyecharts快速入门的更多相关文章
- d3.js:数据可视化利器之快速入门
hello,data! 在进入d3.js之前,我们先用一个小例子回顾一下将数据可视化的基本流程. 任务 用横向柱状图来直观显示以下数据: var data = [10,15,23,78,57,29,3 ...
- 数据可视化之pyecharts
Echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化.pyecharts 是一个用于生成 Echarts 图表的类库.实际上就是 Echarts 与 Python 的对接. 安装 ...
- 【python可视化系列】python数据可视化利器--pyecharts
学可视化就跟学弹吉他一样,刚开始你会觉得自己弹出来的是噪音,也就有了在使用python可视化的时候,总说,我擦,为啥别人画的图那么溜: [python可视化系列]python数据可视化利器--pyec ...
- python数据可视化:pyecharts
发现了一个做数据可视化非常好的库:pyecharts.非常便捷好用,大力推荐!! 官方介绍:pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 如何使用Python快速制作可视化报表----pyecharts
如何使用Python快速制作可视化报表 数据可视化能力已经越来越成为各岗位的基础技能.领英的数据报告显示,数据可视化技能在2017年中国最热门技能中排名第一. 就数据分析而言,可视化探索几乎是你正 ...
- Python:数据可视化pyecharts的使用
什么是pyecharts? pyecharts 是一个用于生成 Echarts 图表的类库. echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化.pyecharts 是一个用于生 ...
- Scala并发编程【快速入门】
1.简介 Scala的actor提供了一种基于事件的轻量级线程.只要使用scala.actors.Actor伴生对象的actor()方法,就可以创建一个actor.它接受一个函数值/闭包做参数,一创建 ...
- 超级干货 :一文读懂数据可视化 ZT
前言 数据可视化,是指将相对晦涩的的数据通过可视的.交互的方式进行展示,从而形象.直观地表达数据蕴含的信息和规律. 早期的数据可视化作为咨询机构.金融企业的专业工具,其应用领域较为单一,应用形态较为保 ...
- python的数据可视化库 matplotlib 和 pyecharts
Matplotlib大家都很熟悉 不谈. ---------------------------------------------------------------------------- ...
随机推荐
- JVM 内部原理(一)— 概述
JVM 内部原理(一)- 概述 介绍 版本:Java SE 7 图中显示组件将会从两个方面分别解释.第一部分涵盖线程独有的组件,第二部分涵盖独立于线程的组件(即线程共享组件). 目录 线程独享(Thr ...
- c++ clr编译dll在c#调用时出现“试图加载不正确的格式”“找不到dll”错误的解决
用depends发现缺了一堆API-MS-WIN什么的dll,网上查找是因为少了VC++2010,VC++2015等一系列,装好后仍然不行,原来这种错误并不是该原因导致的,也并不缺少那些dll(dep ...
- 【转】Web前端性能优化——如何提高页面加载速度
前言: 在同样的网络环境下,两个同样能满足你的需求的网站,一个“Duang”的一下就加载出来了,一个纠结了半天才出来,你会选择哪个?研究表明:用户最满意的打开网页时间是2-5秒,如果等待超过10秒, ...
- Zookeeper系列三:Zookeeper客户端的使用(Zookeeper原生API如何进行调用、ZKClient、Curator)和Zookeeper会话
一.Zookeeper原生API如何进行调用 准备工作: 首先在新建一个maven项目ZK-Demo,然后在pom.xml里面引入zk的依赖 <dependency> <groupI ...
- C语言之单元测试
在ITOO高校云平台项目实践中,我们模板的模块因为在调别人的接口时出现了问题,为了弄明白是不是接口出了问题,就必须学会单元测试. WHAT? 单元测试(unit testing),是指对软件中的最小可 ...
- MSP MCU I2C入门指南
这是一份介绍性指南,指导你如何用超低功耗MSP微控制器 (MCU) 开始一个与I2C通信有关的项目: 简介 I2C(或称为I2C,集成电路总线)是一种两线制通信形式,主要用来在短距离.电路板间的应用中 ...
- shell脚本中的逻辑判断 文件目录属性判断 if特殊用法 case判断
case判断 • 格式 case 变量名 in value1) command ...
- css文件的MIME错误引发的Jquery Mobile绘制错误
静态文件serve设置的MIME不对,引起的浏览器警告 Resource interpreted as Stylesheet but transferred with MIME type applic ...
- Java中创建线程的三种方式以及区别
在java中如果要创建线程的话,一般有3种方法: 继承Thread类: 实现Runnable接口: 使用Callable和Future创建线程. 1. 继承Thread类 继承Thread类的话,必须 ...
- Linux内核之旅
http://www.kerneltravel.net/ Linux内核之旅 Linux Kernel Travel